
個人第二次作業
0前言
本次作業要求做一個詞頻統計的軟件,功能簡單來說是實現英文文章的單詞總數,以及每個單詞出現次數的統計。
編程語言語言:C++
工具:CodeBlocks
git地址:https://git.coding.net/Vrocker/wf.git
一、主要功能
0.簡述:
題目要求總共為四部分,通過對這四部分功能需求的研究,可以將主要功能細分成以下部分:
1.可以讀入本地txt格式的文件,要求內容是英文書籍或者文章。
2.統計文件中不重復出現單詞的總數,並輸出。
3.統計文件中英文單詞的詞頻,即出現的單詞以及這個單詞出現的次數,並且降序輸出。
4.要求在命令提示符中直接控制程序,即輸入相應參數實現相應的功能。
5.支持單一文件,同時支持指定文件夾下的所有文件中英文單詞的詞頻統計。
6.在多文件統計時只輸出出現次數最多的十個單詞。
二、設計思路
要實現題目要求的功能,我首先想到的是用數組或者鏈表來進行操作:
首先讀入輸入的文本文件,將文本文件的各個字符包括標點符號等逐一放進數組中。然後設置一個指針從頭開始進行遍歷,一旦遇到標點或者空格的時候(我認為“-”連接的兩個或多個英文單詞應該算作一個單詞,所以“-”不用排除掉)就可以分割單詞,將這個單詞保存到另外一個數組中。然後再設置另外一個指針,對新數組進行遍歷,統計每個單詞出現的次數,以及這個單詞本身。最後利用排序算法,例如冒泡排序,進行降序排序。這樣就可以大致實現主要的功能。
但我在查閱資料的時候,我看到一篇博客名為”【tips】【詞頻統計】中可能用到的資源,以C++為例“的博客,網址是:http://www.cnblogs.com/Z-XML/p/3329234.html(真的很感謝這位作者)。看完這篇博客我了解到在C++中有一個MAP容器,可以更好更簡單,而且更快的完成想要的功能。因為之前接觸C++的時候,並不了解map容器,所以便開始了學習的過程。同時在這篇博客中我了解到利用vector以及自帶的sort函數可以排序數組。這樣就大大減少了工作量。但是由於之前我也沒接觸過這些,所以也要開始學習這些對我來說新的概念和方法。所以我放棄了最開始選擇的設計思路,改用這個來設計我的程序。
三、難點
1.參數
功能要求通過命令提示符輸入相應的參數可以直接進行操作。這樣的設計方法,之前我並不了解。所以開始查詢資料,找解決方案。因為選擇了C++進行編程,所以也開始看相關的C++書籍。這個功能花費了我相當多的時間來解決。首先的難題是不知道怎麽可以獲取到這些參數,同時也不清楚怎麽樣對參數進行判斷,以便進行不同的操作。
在學習之後,知道了C++中可以用int main(int argc, char* argv[])定義主函數,從而直接實現參數的功能。部分代碼如下:
1 for(int i=1; i<argc; i++)//用於接受從命令提示符傳遞進來的參數 2 { 3 str = argv[i]; 4 if(str=="-s")//如果從命令提示符傳遞的第一個參數是“-s”執行以下操作 5 { 6 char const *a = "g:\\"; 7 char const *b = argv[i+1]; 8 std::string const& cc = std::string(a) + std::string(b); 9 char const *c = cc.c_str();//將兩個char進行拼接,以便傳入fin.open函數中 10 fin.open(c); 11 break;//跳出判斷 12 } 13 else if(str=="floder")//如果從命令提示符傳遞的第一個參數是floder執行以下操作 14 { 15 system("dir /b /a-d G:\\floder\\*.* >d:\\allfiles.txt");//讀取指定文件夾下的所有txt文件 16 for(int j=2; j<argc; j++)//將所有的txt文件寫入流文件 17 { 18 ............//此功能未能實現 19 } 20 } 21 else//當傳遞的第一個參數是txt文件的文件名時 22 { 23 char const *a = "g:\\"; 24 char const *b = argv[i]; 25 char const *d = ".txt"; 26 std::string const& cc = std::string(a) + std::string(b) + std::string(d); 27 char const *c = cc.c_str(); 28 fin.open(c); 29 } 30 }
2.拼接char*
要求的功能中,要實現在命令提示符輸入wf和書名來實現詞頻統計。而在我設計的程序中,要用到被統計文件的實際地址。例如"c:\\a.txt"。但是文件的名字又是不確定的所以我在這裏要用到拼接char*來實現。在查詢大量資料後,發現可以實現。代碼如下:
1 if(str=="-s")//如果從命令提示符傳遞的第一個參數是“-s”執行以下操作 2 { 3 char const *a = "g:\\"; 4 char const *b = argv[i+1]; 5 std::string const& cc = std::string(a) + std::string(b); 6 char const *c = cc.c_str();//將兩個char進行拼接,以便傳入fin.open函數中 7 fin.open(c); 8 break;//跳出判斷 9 }
3.去除標點
要實現統計詞頻的功能,標點就一定會影響統計。所以要除去標點,才能正確的統計單詞,並且最後完整正確的輸出。為此定義了一個函數,來實現這個功能。代碼如下:
1 void StringToLower(string &theString)//將字符串轉化成全小寫 2 { 3 int nLen = theString.length(); 4 for(int i = 0; i < nLen; i++) 5 { 6 theString[i] = tolower(theString[i]); 7 } 8 }
並且在輸入文本之後,調用這個函數,將不相關的符號排除。代碼如下:
1 set<char> ignoreSet;//除去標點符號或者會影響判斷單詞等符號 2 ignoreSet.insert(‘,‘); 3 ignoreSet.insert(‘.‘); 4 ignoreSet.insert(‘?‘); 5 ignoreSet.insert(‘:‘); 6 ignoreSet.insert(‘!‘); 7 ignoreSet.insert(‘;‘); 8 ignoreSet.insert(‘\‘‘); 9 ignoreSet.insert(‘"‘);
4.轉換大小寫
我在第一次測試程序的時候,發現自己犯了一個錯誤。就是大小寫沒有轉換,導致同樣的單詞只是大小寫不一樣,會有兩個結果。這顯然不符合題目的要求。所以為了讓大小寫統一,這裏把統計到的所有單詞都轉化成小寫字母。這樣就不會有問題。代碼如下:
1 void StringToLower(string &theString)//將字符串轉化成全小寫 2 { 3 int nLen = theString.length(); 4 for(int i = 0; i < nLen; i++) 5 { 6 theString[i] = tolower(theString[i]); 7 } 8 }
5.排序輸出
最後要對統計過的單詞以及出現的次數,以次數為標準降序排列輸出。這裏就用到了排序的函數。最開始,我想用冒泡排序或者其他相應的算法進行。但是在了解C++中各種排序的方法之後。我了解到C++自帶一個sort函數可以用於排序。所以在這裏我選擇這個方法。在看了一些用map容器最後進行排序的相關代碼之後,我發現這些代碼最後大部分都是把map轉化成vector之後再進行排序。但是對於這個知識點我之前也是沒有接觸過。所以再進行學習之後,模仿同樣方法的排序代碼嘗試進行自己編寫。代碼如下:
1 struct CmpByValue 2 { 3 bool operator()(const PAIR& lhs, const PAIR& rhs) 4 { 5 return lhs.second > rhs.second; 6 } 7 }; 8 .................. 9 vector<PAIR> wmap_vec(wmap.begin(), wmap.end()); 10 sort(wmap_vec.begin(), wmap_vec.end(), CmpByValue());
利用wmap_vec.size()可以直接輸出總數。
這時候每個單詞存放在對應的wmap_vec[i].first 中。而出現的次數存放在對應的wmap_vec[i].second中。再用一個for循環就可以輸出。
1 float sum=0; 2 for (int i = 0; i != wmap_vec.size(); ++i)//利用map輸出總字數 3 { 4 sum=sum+1; 5 } 6 cout<<"total "<<sum<<" words"<<endl<<endl<<endl; 7 for (int i = 0; i != wmap_vec.size(); ++i)//利用map輸出每個單詞以及其出現次數 8 { 9 cout << left << setw(50) << wmap_vec[i].first << wmap_vec[i].second << endl; 10 }
四、功能測試
1.
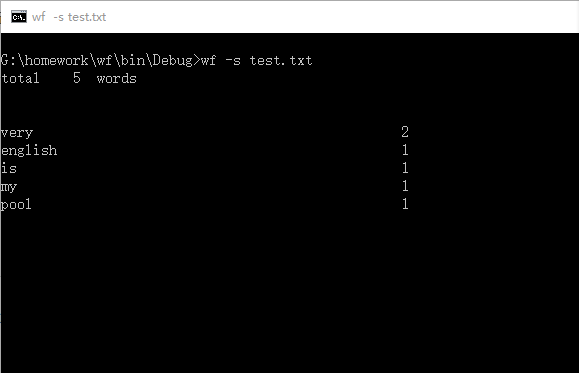
2.
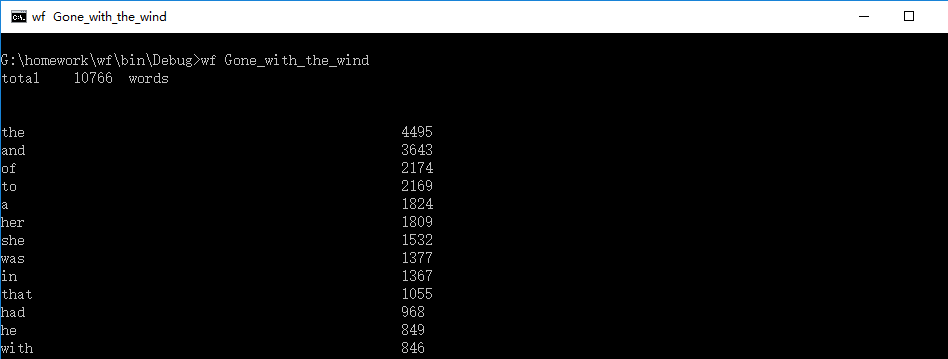
3.
這個部分支持命令行輸入存儲有英文作品文件的目錄名,批量統計。這個功能花費了我很長的時間來做。但是還是沒有做好。試了很多方法,但是都沒有成功。上述代碼有出現str = argv[i];else if(str=="floder");判斷參數成功的時候試過設置一個flag,當主函數運行到輸出部分的時,如果flag正確則多次輸出結果。但是沒有成功。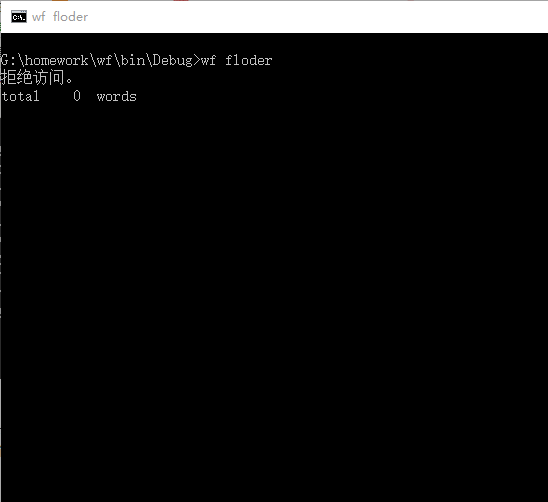
五、總結
剛開始我看到這個題目的時候,第一感覺是挺簡單的。邏輯不復雜,而且應該比較容易實現。所以一直沒覺得會花費我太多時間。但當我真正開始著手寫代碼的時候發現,可以用更簡單便捷的方法實現。所以我就開始研究這個新的方法。因為覺得代碼量並不大,所以又一次估算時間應該沒有多久。然而,寫著寫著我開始發現自己的知識掌握的太不牢固,同時也發現自己想要用的這個方法裏面,有太多東西是我之前沒有接觸過的。但是既然選擇了這個方法,況且這個方法看起來確實比較簡潔,我就硬著頭皮邊寫邊學。
首先map容器和vector之前我並不知道。所以兩個知識點我花了相當大的時間來處理。之後參數的相關知識也是一知半解,再查了很多資料之後才開始著手編寫,這個環節花費的時間也不少。雖然知識點不多,但是由於沒有實際編寫過,所以在調試,測試的過程中出現了很多很多的問題。同時,char*的拼裝,也是在查閱資料之後在知乎看到一個回答,才讓我很好的解決。這些只是花費時間比較多的環節,實際上每個步驟我都花費了相當長的時間。總結來看,預估的時間遠遠小於我真實花費的時間。
通過這次編寫程序,讓我最感觸的就是預估的時間可能會遠遠低於花費的時間。一個看上去不難的程序,在編寫的過程中也會遇到很多難題。同時,這次編寫程序讓我開始知道自己掌握的知識點,遠遠不夠,需要不斷的學習同時不斷地練習才能保證熟練的掌握一門語言。
PSP表格
|
分類 |
預計時間(分鐘) |
實際時間(分鐘) |
實際總時間(分鐘) |
時間差(分鐘) |
|
功能一 |
90 |
95 |
155 |
65 |
|
測試1 |
60 |
|||
|
功能二 |
150 |
150 |
240 |
90
|
|
測試2 |
90 |
|||
|
功能三 |
120 |
240 |
330 |
110 |
|
測試3 |
90 |
|||
|
功能四 |
180 |
90 |
150 |
-30 |
|
測試4 |
60 |
|||
|
總體調試 |
60 |
90 |
90 |
30 |
個人第二次作業