
微服務在微信後臺的架構實踐
轉載:
極客時間
重拾極客精神 · 提升技術認知
APP內打開微服務在微信後臺的架構實踐
2017-10-21 許家滔微服務的理念與騰訊一直倡導的“大系統小做”有很多相通之處,本文將分享微信後臺架構的服務發現、通信機制、集群管理等基礎能力與其上層服務劃分原則、代碼管理規則等。
背景介紹
首先,我們需要敏捷開發。過去幾年,微信都是很敏捷地在開發一些業務。所以我們的底層架構需要支撐業務的快速發展,會有一些特殊的需求。
另外,目前整個微信團隊已經有一千多人了,開發人員也有好幾百。整個微信底層框架是統一的,微信後臺有千級模塊的系統。比如說某某服務,有上千個微服務在跑,而集群機器數有幾萬臺,那麽在這樣的規模下,我們會有怎麽樣的挑戰呢?
我們一直在說“大系統小做”,聯想一下,微服務與騰訊的理念有哪些相同與不同的地方呢?通過對比,最終發現還是有許多相通的地方。所以我挑出來講講我們的實踐。
看過過去幾個會議的內容,可能大家會偏向於講整一個大的框架,比如整個雲的架構。但是我這邊主要講的是幾個特殊的點。
概覽詳情
開始看一下我們的結構。全球都有分布,主要有上海、深圳、香港、加拿大幾個數據中心。
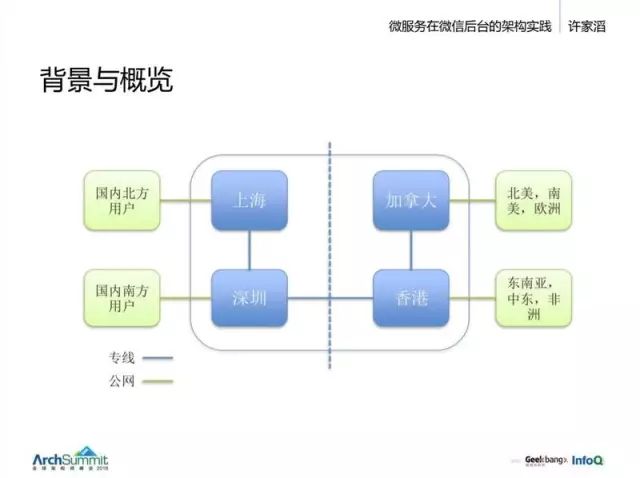
其中上海服務國內北方的用戶,深圳負責南方用戶,加拿大服務北美、南美和歐洲,香港服務東南亞、中東和非洲地區。
然後來看看我們的架構:
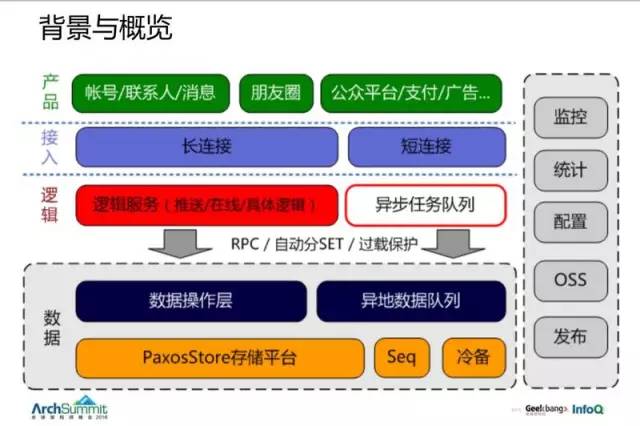
- 最上邊是我們的產品;
- 然後有一個號稱幾億在線的長連接和短連接的服務;
- 中間有一個邏輯層,後臺框架講的主要是邏輯層往後這塊,包括我們的 RPC、服務分組、過載保護與數據存儲;
- 底層有個 PaxosStore 存儲平臺。
整套就是這麽個體系。微服務很容易去構建,但是規模變大後有哪些問題,需要哪些能力?這裏挑出三個點來講一下:
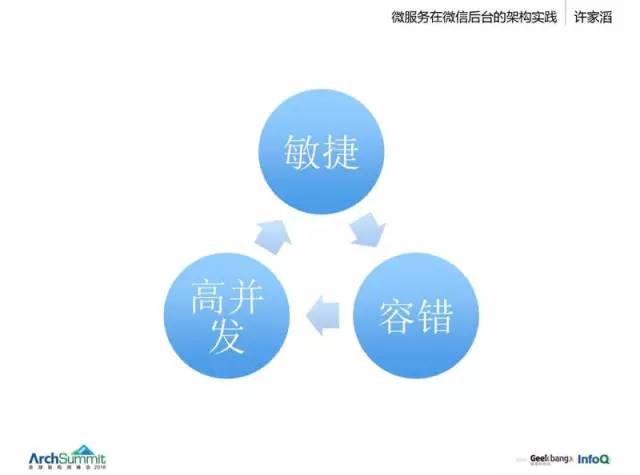
一、敏捷
希望你的服務很快實現,不太多去考慮。像我們早期互聯網業務,甚至包括 QQ 等,我們很註重架構師的一個能力,他需要把握很多的東西。他設置每個服務的時候,要先算好很多資源,算好容災怎麽做。容災這個問題直接影響業務怎麽去實現的,所以有可能你要做一個具體邏輯的時候要考慮很多問題,比如接入服務、數據同步、容災等等每個點都要考慮清楚,所以節奏會慢。
二、容錯
當你的機器到了數萬臺,那每天都有大量機器會有故障。再細一點,可以說是每一個盤的故障更頻繁一點。
三、高並發
基礎架構
接下來看看我們的基礎架構。

整個微服務的架構上,我們通常分成這些部分:
- 服務布局
- 服務之間怎麽做一些遠程調用
- 容錯(主要講一下過載保護)
- 部署管理
服務布局
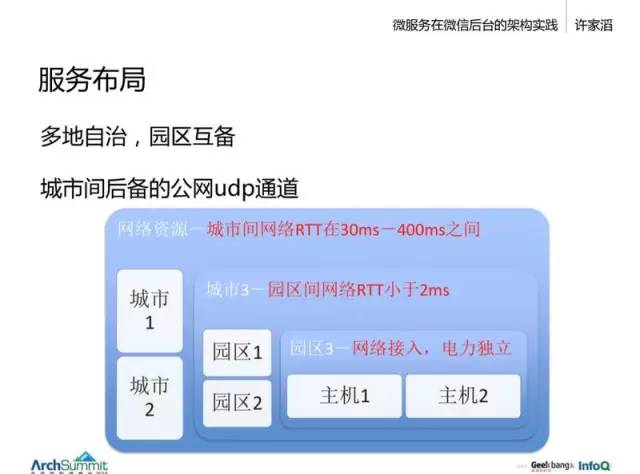
分兩層,一個是城市間。城市之間的數據是相對獨立的,除了少數賬號全球同步,大部分業務都希望做成電子郵件式的服務,各自有自身的環境在跑,之間使用類似於電子郵件的通信。所以我們選擇讓每個城市自治,它們之間有一個 200-400ms 的慢速網絡,國內會快點,30ms。
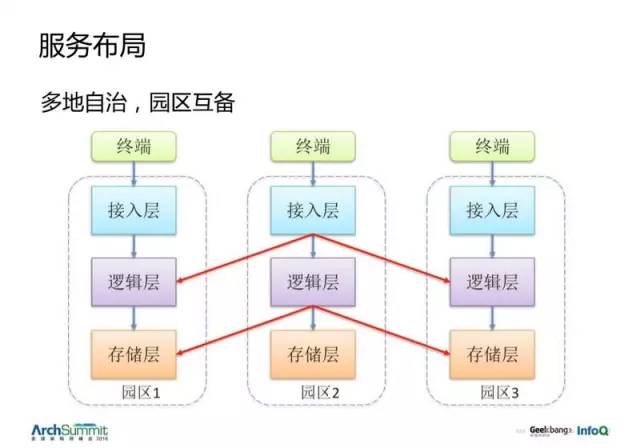
而城市內部,就是每個園區是一套獨立的系統,可以互相為對方提供備份。要求獨立的電源與網絡接入。
城市內部會有整套的劃分,終端 --> 接入層 --> 邏輯層 --> 存儲層 都是完全獨立的一套系統。
遠程調用
看到很多框架,竟然是沒有協程的,這很詫異。早年我們 QQ 郵箱、微信、圖像壓縮、反垃圾都是一個 web 服務,只有存儲層會獨立到後面去,甚至用 web 直連 MySQL。因為它早期比較小,後來變大之後就用微服務架構。
每個東西都變成一個小的服務,他們是跨機的。你可以想象一下,每天我們很多人買早餐的時候,掏出手機做一個微信支付,這一個動作在後臺會引起上百次的調用。這有一個復雜的鏈路。在 2014 年之前,我們微信就是沒有做異步的,都是同步的,在這麽多調用裏,A 服務調用 B,那要先等它返回,這樣就占住了一條進程或者線程。所以其實 13 年的時候,我們發生了大大小小的故障,很大一部分原因就在這裏。
然後 13 年底的時候,這個問題太嚴重了,嚴重到,比如發消息的時候,你去拿一個頭像之類的,它只要抖動,就可能引發整一條調用鏈的問題,並且因為過程保護的不完善,它會把整個消息發送的曲線掉下去,這是我們很痛苦的時間。
然後當時我們就去考慮這些方案,13 年的時候抽出 3 個人重新做了一個完整的庫 libco。(兩千行),實現時間輪盤與事件處理鏈、常用網絡編程模式、同步原語等。它分為三大塊,事件驅動、網絡 HOOK 和協程機制。
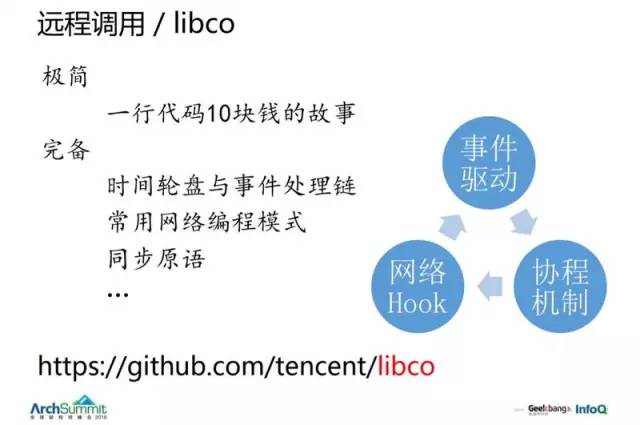
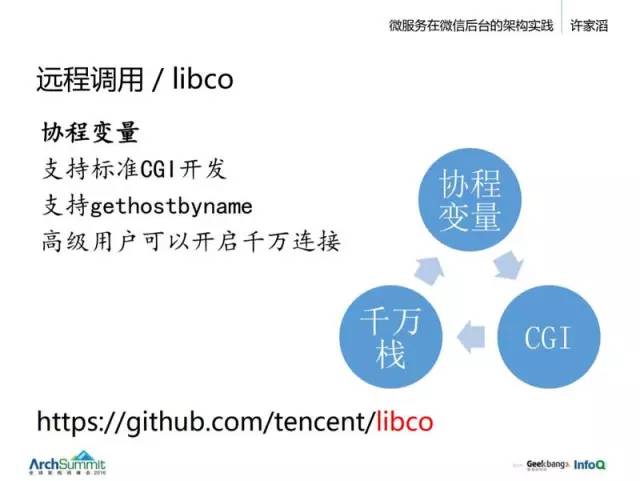
早期是多進程為主,當年切多線程的時候,也遇到一大波修改,後來線程裏有了一個線程變量就好多了。如果沒有這個東西,你可能要把許多變量改成參數再一層一層傳遞下去。有了線程變量就好多了。現在我們的協程變量也是這個意義,效果就像寫一個宏一樣。
另一個是,我們支持 CGI,早期庫在 CGI 上遇到問題,所以沒有推廣。因為一個標準 CGI 服務是基於一些古老的接口的,像 getENV、setENV,就是說你的 coreString 是通過 ENV 來得到的,那麽這個我們也把它給 HOOK 掉了,它會根據你的協程去分派。
最難的一個是 gethostbyname 方法,我發現很多人就連在異步編程裏,處理 hostbyname 也可能是用了一套獨立線程去做,或者你很辛苦地把整個代碼摳出來重新寫一遍,這個肯定是有很多問題的。所以我們 libco 就把這個 gethostbyname 給完整地支持了。
最後如果你還不爽,說一般業務邏輯可以這麽幹,那我還有很多後臺代碼怎麽辦呢?很多有經驗的老的程序員可能要拿著他們那一堆很復雜的異步編程的代碼來質疑我們,他們不認為他們的代碼已經完全可以被協程所取代了。
他們有如下兩個質疑:
- 質疑性能:協程有很多切換,會不會帶來更大開銷?
- 你可能處理幾萬並發就好,消耗個 1G 內存就行,但是我們這裏是處理千萬並發哦,這麽大的規模,我不信任你這個東西。
這樣我們其實是面臨了一個問題,因為一些老代碼,越是高級的人寫的,它的技術棧越深,稍微改動一點代碼,就出 BUG 了。
但是你用協程的話,很多變量就自然在一個連續的內存裏了,相當於一個小的內存池,就比如 if……else……這個你沒有必要去 new 一個東西保存狀態的,直接放在棧裏就行了,所以它的性能更好了。
第二個是,它要求很高的並發。由於協程要一個棧,我們一般開 128k,如果你對這個代碼掌控得比較好,可能開 16k,就算是這樣,你要開 1 萬個協程,還是要 100 多 M 的內存。所以我們後來就在這基礎上做了一個可以支持千萬連接的協程模式。
Libco 是一個底層庫,讓你很方便開發,但是大部分開發人員不是直接面對 libco 的,我們花了一年時間把整個微信後臺絕大部分邏輯服務、存儲服務改成基於 libco,整個配置就直接通過配一臺機器上的並發數配 10 倍甚至 20、30 倍,這樣子就一下子把整個問題解決了。
過載保護
並發數上去後容易引發另一個問題,早期的時候,後端服務性能高,邏輯服務性能相對弱,很容易被 hold,不可能給後端發起很多連接,不具有“攻擊性”,但修改完成後,整個前端變得很強,那可能對後端產生很大的影響。這個時候就要來考慮一下過載保護了。
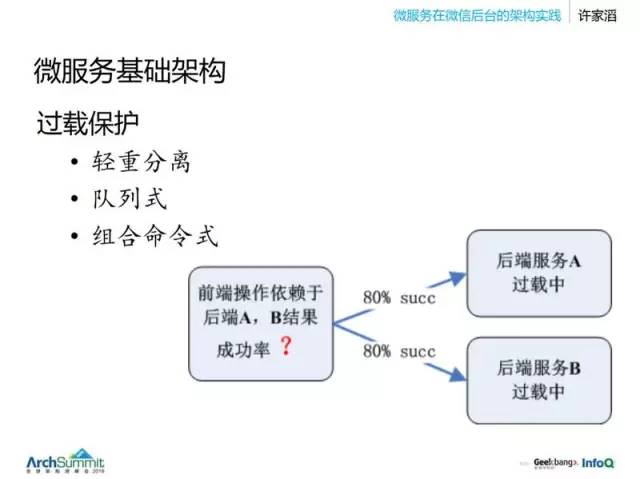
一般會提到幾個點。
1.輕重分離:
就是一個服務裏邊不要又有重的操作,又有輕的,這樣過載的時候,大量的請求都被某些小請求攔截掉了,資源被占滿了。
2.隊列:
過載保護一般是說系統內部服務在做過去的事情,做無用功。它們可能待在某個隊列裏邊,比如服務時間要求 100ms,但它們總是在做 1s 以前的任務,所以整個系統會崩潰。所以老的架構師會註重說配好每一個服務的隊列長度,估算好。但是在繁忙的開發中,是很難去控制的。
3.組合命令式:
後端服務並不是只有一個,上邊這個圖中的例子,想要調用很多服務,然後 AB 都過載,它們每一個其實都只是過載一點,通過率可達到 80%,但是前端需要這兩個服務的組合服務,那麽這裏就可能只能達到 60% 的通過率。然後後邊如果是更多的服務,那麽每個服務的一點點過載,到了前端就是很嚴重的問題。怎麽解決呢?

這本書在 12、13 年的時候很火,裏邊提到了兩個對我們有用的點。
- 一個是“希望系統是分布式的,去中心化”,指系統過載保護依賴每一個節點自身的情況去做,而不是下達一個統一的中心指令。
- 二是“希望整個控制是基於反饋的”,它舉了一些例子,像抽水馬桶,像過去煉鋼鐵的參數很難配,但是只要有一個反饋機制就好解決了。
於是我們構建了一套看起來有點復雜的過載保護系統。
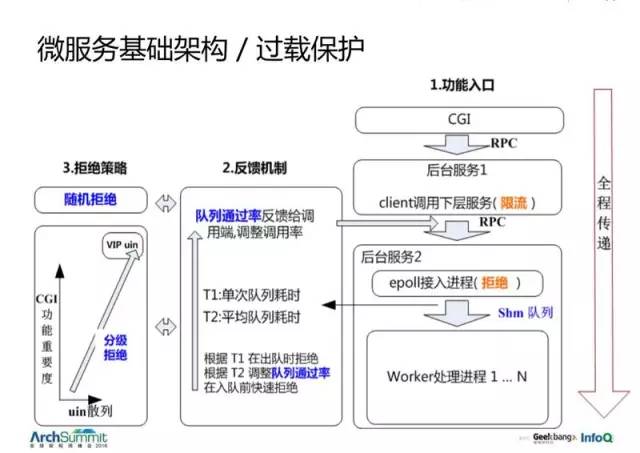
整個系統基於反饋,然後它把整個拒絕的信息全程傳遞了。看到最右邊,有幾個典型的服務,從一個 CGI 調用一個後臺服務,再調用另一個後臺服務,它會在 CGI 層面就把它的重要程度往下傳。回到剛才那個前端調用 A、B 服務的例子,使用這樣的一種重要程度傳遞,就可以直接拒絕那些相同用戶的 20% 的請求,這樣就解決了這個問題。
怎麽配隊列?這個只是反映了生產者和服務者處理能力的差異,觀察這個差異,就可以得到一個好的拒絕的數。你不需要去配它多長,只需要去看一個請求在隊列裏待的平均時間是否可以接受,是一個上漲趨勢還是一個下降趨勢。這樣我們就可以決定要不要去拒絕。那這樣幾乎是全自動的。你只要配得相對大一點就行了,可以抗一些抖動。在接入之前就評估它,在過去一段時間內平均隊列耗時多長,如果超過預支,我們就往下調。這樣就把整個系統的過載能力提升了很多。
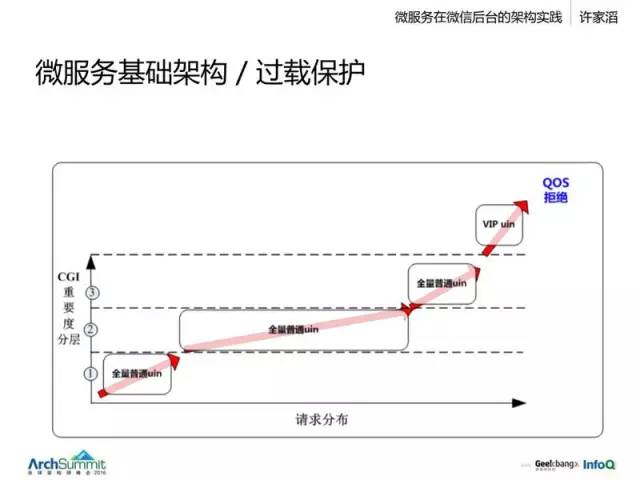
這是一個具體的做法,我們會考慮兩個維度,一個是後臺服務,可能服務很多不同的前端,它可能來源於一個支付的請求,經過層層調用,到達後臺;或者是一個發消息的服務;它也可能是一個不重要的小服務,如果這個賬戶服務過載的時候,那麽我們可以根據這個表來自動地優先去拒絕一些不那麽重要的服務請求,使得我們核心服務能力可以更好地提供。這樣整個系統就可以做到很好的過載保護。
數據存儲
上邊提到一個數據層,那我們是怎麽去做數據的呢?

在過去很多年裏,我們可能是盡可能去事務化、不追求強一致,一般是采用主備同步的方法。但我們的目標還是強一致的存儲。
強一致是說,寫一個數據之後,服務器的返回成功不會因為單機故障而丟失。早年我們用的是自己設計的協議,嚴格來證明的話,沒有 Paxos 這麽嚴謹,所以我們在過去一年多的時間內,重新做了一個 Paxos 存儲。

它是一個同步復制的數據存儲,支持各個園區之間的數據一致性,並且是可以多組多寫的,就是說任何一個園區接入,它都可以進行數據的強制讀寫。另外它並不只是 key-value 模式,它支持 key-value、list、表。在微信這邊很少會說完全依賴 key-value 的,因為很多業務都是有列表、表格等的請求,所以很多年前就開始用表格的存儲。
Paxos 可用性很高,所以我們就敢做單表有億行的設計,這樣像公眾號粉絲等需要很大的,幾千萬甚至幾億行的記錄,就不用考慮自己去分表。並且這個存儲可以使用類 SQL 的語句去做,它是完全保證事務的。
它還是插件化系統,不僅支持 LSM,還支持其它存儲引擎。
然後它低成本,後臺 CPU 有 E3-1230V3,也有 E5-2670 型號的,內存,CPU 與 ssd 之間有一些能力用不上,所以我們系統是可以靈活組合很多不同存儲介質的。
這個系統是跑在同城的,也就是上海內部、深圳內部、加拿大內部和香港內部。它們之間的延遲相對較低,幾毫秒的級別。這是一個非租約的,沒有 leader,不存在切換的不可用期,隨時都可以切換任何一個園區。負載均衡這一塊我們沿用 kb64 架構,6 臺機為一組。因為園區故障少,平時單機時,分攤 25% 的流量,整體比較穩定。6 臺為一組時,整個作為一個 set,有很多 set 之間的適用一致性要去做,會有一個很細粒度的伸縮性,比如它可以 100 組擴展到 101 組。
為什麽用這麽重的方式呢?因為希望應用是 簡單快速 的,不用假設一個數據寫完之後還可能被回退掉,這樣只會有很多額外的開銷,會有很多問題。比如公眾號,他們有很多素材庫之類的很重要的存儲,如果數據突然丟了,或者說回退了,沒有了,那用戶投訴是會很嚴重的。微信賬號這邊也是這樣,如果一個賬戶註冊了,但是這個數據回退了,那也是很嚴重的問題。
另一個原因是 可用性。在一個傳統的主備系統裏面,當主機掛掉,面臨切不切備機的抉擇,然後你會層層請示,說明目前的同步狀況,甚至你不知道當前的同步狀況,經過很多流程來請示是否切換備機。
而另外,它也不是一個高成本的方案。
為什麽不用 Raft 呢?Raft 的開源很有價值,它把互聯網後臺的數據一致性能力提升了很多,就算是一個很小的團隊,它也能直接用 Raft 獲得一個強一致能力,而這可能就已經超過了許多互聯網後臺的強一致能力,因為很多後臺都是用了很古老的架構,比如長期用到主機架構。
Raft 與 Paxos 的區別是什麽呢?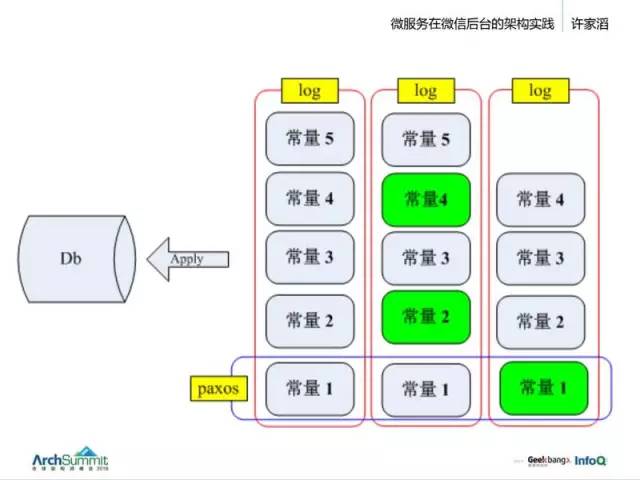
其實 Raft 和 Paxos 不是一個層面的概念,這個圖就是典型的通過一個 log 變更 db 的架構,通過三條 log 一致性做到數據持久強一致性。那 Paxos 在哪裏?在一個 log 的某一個 entry 那邊,三個點構成一個常量。
那 Raft 是什麽呢?它是整一個二維的東西,就是說,基於一個 Paxos 強一致協議做的一條 log,它整個就是一個 Raft。所以我們可以認為 Raft 其實是 Paxos(log)的一種選擇。如果你允許綠色部分不存在,那它就不是 Raft。因為 Raft 的設計是你自己做的,它與 Paxos 沒關系。
整個 PaxosStore 架構如圖:
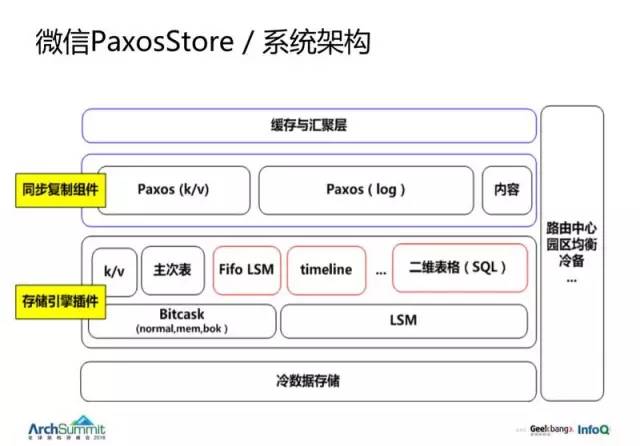
它包含了很多層,包括緩存和匯聚層、同步復制的組件等。
這一套方案是在線上用了好幾千臺的,是一個非租約的方案。存儲引擎可以自由定制。如果想用大表,那可以用 leveldb。如果想用更強的 LSM,也可以選擇。然後我們也有很多 Bitcask 的模型,更適合於內存的 key-value。
由於有幾萬臺機,所以變很重要,我們也基於 BT 做了一套存儲方案。它會以園區為根據地,通常一個變更,會以 BT 協議發送到每個園區裏,然後園區內部把同機架機器分成一個分組,然後分組內再互傳。就我了解,Facebook 和 Twitter、Ebay 都是這樣做的。
微服務在微信後臺的架構實踐