
機器學習系列-決策樹
決策樹
什麽是決策樹
決策樹是一種簡單高效並且具有強解釋性的模型,廣泛應用於數據分析領域。其本質是一顆由多個判斷節點組成的樹。
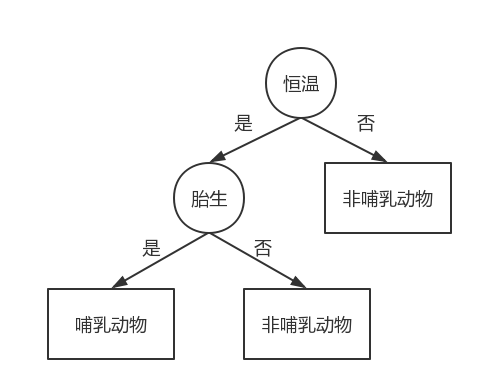
上圖是一個簡單的決策樹模型,用來判斷某個動物樣本是否屬於哺乳動物,樹中包含三種節點:
- 根節點:沒有入邊,但有零條或者多條出邊
- 內部節點:有一條或者多條出邊
- 葉節點:只有一條入邊,沒有出邊
在決策樹中,每個葉子節點都賦予一個類標號。非葉子節點包含屬性測試條件,用來分開具有不同特性的記錄。
在上面的例子中,體溫屬性就可以把哺乳動物和非哺乳動物區分開來;如果體溫是恒溫的,通過是否胎生可以進一步區分哺乳動物和其他恒溫動物(比如鳥類)。
一旦決策樹構造完成,對記錄進行分類就很容易了。從樹的根節點開始,將測試條件用於檢驗,直到到達一個葉子節點。到達葉子節點後,這個葉子節點的類稱號就被賦予這條記錄。
我們現在用這顆決策樹預測麻雀所屬的類別:首先,麻雀是恒溫動物,因此,因此,我們要檢驗麻雀是否是胎生,檢驗結果為‘否’,因此我們確定,麻雀不是哺乳動物。
決策樹的構造
原則上講,對於給定的屬性集,可以構造的決策樹的數目達指數級。盡管某些決策樹比其他決策樹更準確,但是由於搜索空間是指數規模的,找出最佳決策樹在計算上是不可行的。盡管如此,人們還是開發了一些有效的算法。能夠在合理的時間內構造出具有一定準確率的次最優決策樹。這些算法通常都采用貪心策略,在選擇劃分數據的屬性時,采取一系列局部最優決策來構造決策樹,Hunt算法就是一種這樣的算法。Hunt算法是許多決策樹算法的基礎,包括ID3,C4.5和CART。下面將敘述Hunt算法並討論它的設計問題。
在Hunt算法中,通過將訓練記錄相繼劃分成較純的子集,以遞歸方式建立決策樹。設\(D_t\)是與結點\(t\)相關聯的訓練記錄集,而\(y=\{y_1,y_2,...,y_c\}\)是類標號,Hunt算法的遞歸定義如下:
如果\(D_t\)中所有記錄都屬於同一個類\(y_t\),則\(t\)是葉結點,用\(y_t\)標記。
如果\(D_t\)中包含屬於多個類的記錄,則選擇一個屬性測試條件將記錄劃分成較小的子集。對於測試條件的每個輸出,創建一個子女結點,並根據測試結果將\(D_t\)中的記錄分布到子女結點中。然後,對於每個子女結點,遞歸地調用該算法。
為了解釋該算法如何執行,考慮如下問題:預測貸款申請者是會按時歸還貸款,還是會拖欠貸款。對於這個問題,訓練數據集可以通過考察以前貸款者的貸款記錄來構造。下表每條記錄都包含貸款者的個人信息,以及貸款者是否拖欠貸款的類標號。
| id | 有房 | 婚姻狀況 | 年收入 | 拖欠貸款 |
|---|---|---|---|---|
| 1 | 是 | 單身 | 125k | 否 |
| 2 | 否 | 已婚 | 100k | 否 |
| 3 | 否 | 單身 | 70k | 否 |
| 4 | 是 | 已婚 | 120k | 否 |
| 5 | 否 | 離異 | 95k | 是 |
| 6 | 否 | 已婚 | 60k | 否 |
| 7 | 是 | 離異 | 220k | 否 |
| 8 | 否 | 單身 | 85k | 是 |
| 9 | 否 | 已婚 | 75k | 否 |
| 10 | 否 | 單身 | 90k | 是 |
該分類問題的初始決策樹只有一個結點,類標號為“拖欠貨款=否”,意味大多數貸款者都按時歸還貸款。然而,該樹需要進一步的細化,因為根結點包含兩個類的記錄。根據“有房者”測試條件,這些記錄被劃分為較小的子集。選取屬性測試條件的理由稍後討論,目前,我們假定此處這樣選是劃分數據的最優標準。接下來,對根結點的每個子女遞歸地調用Hunt算法。從給出的訓練數據集可以看出,有房的貸款者都按時償還了貸
款,因此,根結點的左子女為葉結點,標記為“拖欠貸款=否”。對於右子女,我們需要繼續遞歸調用Hunt算法,直到所有的記錄都屬於同一個類為止。每次遞歸調用所形成的決策樹如下圖所示。
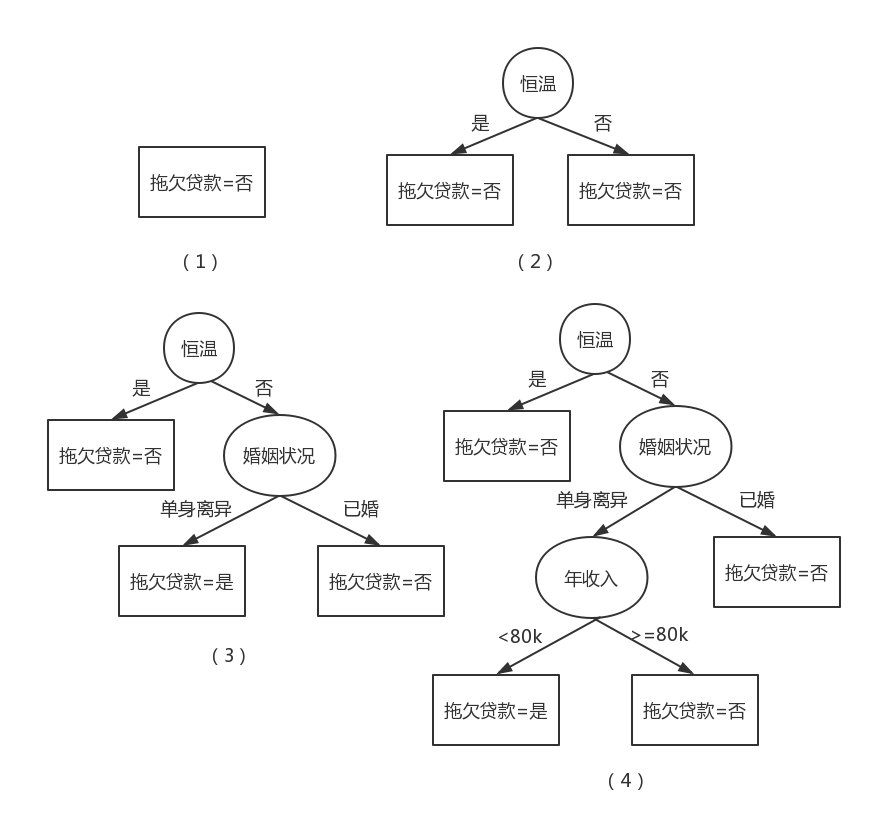
如果屬性值的每種組合都在訓練數據中出現,並且每種組合都具有唯一的類標號,則Hunt算法是有效的。但是對於大多數實際情況,這些假設太苛刻了,因此,需要附加的條件來處理以下的情況。
- 算法的第二步所創建的子女結點不能為空,即不存在與這些結點相關聯的記錄。如果沒有一個訓練記錄包含與這樣的結點相關聯的屬性值組合,這種情形就可能發生。這時,該結點成為葉結點,類標號為其父結點上訓練記錄中的多數類。
- 在第二步,如果與\(D_t\)相關聯的所有記錄都具有相同的屬性值(目標屬性除外),則不可能進一步劃分這些記錄。在這種情況下,該結點為葉結點,其標號為與該結點相關聯的訓練記錄中的多數類。
決策樹歸納的學習算法必須解決下面兩個問題。
- 如何分裂訓練記錄? 樹增長過程的每個遞歸步都必須選擇一個屬性測試條件,將記錄劃分成較小的子集。為了實現這個步驟,算法必須提供為不同類別的屬性指定測試條件的方法,並且提供評估每種測試條件的客觀度量。
如何停止分裂過程? 需要有結束條件,以終止決策樹的生長過程。一個可能的策略是分裂結點,直到所有的記錄都屬於同一個類,或者所有的記錄都具有相同的屬性值。盡管兩個結束條件對於結束決策樹歸納算法都是充分的,但是還可以使用其他的標準提前終止樹的生長過程。
選擇最佳劃分的度量
接下來就是構造決策樹的重點:選擇最佳劃分的度量,這也是ID3,C4.5,CART的出處。
ID3算法
ID3算法是構造決策樹的常用算法,同時它也是C4.5和CART的基礎。介紹ID3算法之前,首先要說一下信息熵和信息增益的概念。
在信息論中,期望信息越小,信息增益越大,從而純度越高,這裏純度高的意思是不同類別的記錄要分得足夠開。所以ID3算法的核心思想就是根據信息增益進行屬性選擇,選擇分裂後信息增益最大的屬性進行分裂。
設\(D\)為用類別對訓練元組進行的劃分,則\(D\)的熵表示為
\[info(D)=-\sum_{i=1}^{m}p_ilog_2(p_i)\]
其中\(p_i\)表示第\(i\)個類別在整個訓練元組中出現的概率,可以用屬於此類別元素的數量除以訓練元組元素總數量作為估計。熵的實際意義表示是\(D\)中元組的類標號所需要的平均信息量。
現在我們假設將訓練元組\(D\)按屬性\(A\)進行劃分,則\(A\)對\(D\)劃分的期望信息為:
\[info_A(D)=\sum_{j=1}^{v}\frac{|D_j|}{|D|}info(D_j)\]
這裏\(v\)是屬性\(A\)所有可能取值的個數。比如,用是否恒溫檢驗是否為哺乳動物時,只有‘是’與‘否’兩種可能取值,所以\(v=2\)。
至於信息增益,即為上兩者之差:
\[gain(A)=info(D)-info_A(D)\]
ID3算法在每次需要分裂時,計算每個屬性的增益率,然後選擇增益率最大的屬性進行分裂。
我們以貸款還款問題為例,分別用\(H,M,I\)代表是否有房,婚姻狀況,年收入這三個屬性,並假設年收入的劃分點為80k:
|id |有房 |婚姻狀況 |年收入 |拖欠貸款 |
|---|:------|:--------|:------|:-------|
|1 |是 |單身 |125k |否 |
|2 |否 |已婚 |100k |否 |
|3 |否 |單身 |70k |否 |
|4 |是 |已婚 |120k |否 |
|5 |否 |離異 |95k |是 |
|6 |否 |已婚 |60k |否 |
|7 |是 |離異 |220k |否 |
|8 |否 |單身 |85k |是 |
|9 |否 |已婚 |75k |否 |
|10 |否 |單身 |90k |是 |
\(info(D)=-0.7log_{2}0.7-0.3log_{2}0.3=0.879\)
\(info_H(D)=0.3*(-\frac{0}{3}log_{2}\frac{0}{3}-\frac{3}{3}log_{2}\frac{3}{3})+0.7*(-\frac{4}{7}log_{2}\frac{4}{7}-\frac{3}{7}log_{2}\frac{3}{7})=0.689\)
\(info_M(D)=0.4*(-\frac{2}{4}log_{2}\frac{2}{4}-\frac{2}{4}log_{2}\frac{2}{4})+0.4*(-\frac{0}{4}log_{2}\frac{0}{4}-\frac{4}{4}log_{2}\frac{4}{4})+0.2*(-\frac{1}{2}log_{2}\frac{1}{2}-\frac{1}{2}log_{2}\frac{1}{2})=0.6\)
\(info_I(D)=0.3*(-\frac{0}{3}log_{2}\frac{0}{3}-\frac{3}{3}log_{2}\frac{3}{3})+0.7*(-\frac{4}{7}log_{2}\frac{4}{7}-\frac{3}{7}log_{2}\frac{3}{7})=0.689\)
那麽相應的信息增益分比為:
\(gain_H=info(D)-info_H(D_j)=0.19\)
\(gain_M=info(D)-info_M(D_j)=0.279\)
\(gain_I=info(D)-info_I(D_j)=0.19\)
由於選擇婚姻狀況為屬性時信息增益最大,所以第一次檢驗條件選擇婚姻狀況。接下來只需處理葉子節點,或者遞歸調用上述步驟即可,最終可以得到整棵決策樹。
C4.5算法
ID3算法在選擇屬性時偏向於多值屬性,另外ID3不能處理連續屬性,上面的例子中,我們在處理年收入屬性時,認為的選擇了閾值。ID3的後繼算法C4.5被設計用於克服這些不足之處。C4.5算法首先定義了“分裂信息”,其定義可以表示成:
\[SplitInfo_A(D)=-\sum_{j=1}^{v}\frac{|D_j|}{|D|}log_{2}(\frac{|D_j|}{|D|})\]
其中各符號意義與ID3算法相同,然後,增益率被定義為:
\[GainRatio(A)=\frac{gain(A)}{SplitInfo(A)}\]
C4.5選擇具有最大增益率的屬性作為分裂屬性。
在處理連續型屬性時,C4.5將連續型變量由小到大遞增排序,取相鄰兩個值的中點作為分裂點,然後按照離散型變量計算信息增益的方法計算信息增益,取其中最大的信息增益作為最終的分裂點。
CART算法
CART,又名分類回歸樹,是一種在ID3的基礎上進行優化的二叉決策樹。CART既能是分類樹,又能是分類樹.當CART是分類樹時,采用GINI值作為節點分裂的依據;當CART是回歸樹時,采用樣本的最小方差作為節點分裂的依據。註意,CART是二叉樹。
分類樹情況下,選擇具有最小\(Gain_GINI\)的屬性及其屬性值,作為最優分裂屬性以及最優分裂屬性值。\(Gain_GINI\)值越小,說明二分之後的子樣本的“純凈度”越高,即說明選擇該屬性(值)作為分裂屬性(值)的效果越好。對於訓練集\(D\),\(GINI\)計算如下:
\[GINI(D)=1-\sum p_{k}^{2}\]
其中,在訓練記錄\(D\)中,\(p_k\)表示第\(k\)個類別出現的概率。
對於含有\(N\)個樣本的訓練集\(D\),根據屬性\(A\)的第\(i\)個屬性值,將訓練集\(D\)劃分成兩部分,則劃分成兩部分之後,\(Gain_GINI\)計算如下:
\($GainGINI_{A,i}(D)=\frac{n_1}{N}GINI(D_1)+\frac{n_2}{N}GINI(D_2)\) $
其中,\(n1,n2\)分別為樣本子集\(S1,S2\)的樣本個數。
對於屬性\(A\),分別計算任意屬性值將數據集劃分成兩部分之後的\(GainGINI\),選取其中的最小值,作為屬性\(A\)得到的最優二分方案:
\[min_{i\in A}(GainGINI_{A,i}(D))\]
對於樣本集\(D\),計算所有屬性的最優二分方案,選取其中的最小值,作為樣本集\(D\)的最優二分方案:
\[min_{A\in Attribute}(min_{i\in A}(GainGINI_{A,i}(D)))\]
所得到的屬性\(A\)及其第\(i\)屬性值,即為樣本集\(S\)的最優分裂屬性以及最優分裂屬性值。
回歸樹情況下,選取\(Gainσ\)為評價分裂屬性的指標。選擇具有最小\(Gainσ\)的屬性及其屬性值,作為最優分裂屬性以及最優分裂屬性值。\(Gainσ\)值越小,說明二分之後的子樣本的“差異性”越小,說明選擇該屬性(值)作為分裂屬性(值)的效果越好。
針對含有連續型分類結果的訓練集\(D\),總方差計算如下:
\[\sigma (D)=\sqrt{\sum{(C_k-\mu)^2}}\]
其中,\(\mu\)表示訓練集\(D\)中分類結果的均值,\(C_k\)表示第\(k\)個分類結果。
對於含有\(N\)個樣本的訓練集\(D\),根據屬性\(A\)的第\(i\)個屬性值,將訓練集\(D\)劃分成兩部分,則劃分成兩部分之後,\(Gainσ\)計算如下:
\[Gain\sigma _{A,i}(D)=\sigma (D_1)+\sigma (D_2)\]
對於屬性\(A\),分別計算任意屬性值將訓練集\(D\)劃分成兩部分之後的\(Gainσ\),選取其中的最小值,作為屬性\(A\)得到的最優二分方案:
\[min_{i\in A}(Gain\sigma _{A,i}(D))\]
對於訓練集\(D\),計算所有屬性的最優二分方案,選取其中的最小值,作為訓練集\(D\)的最優二分方案:
\[min_{A\in Attribute}(min_{i\in A}(Gain\sigma _{A,i}(D)))\]
所得到的屬性\(A\)及其第\(i\)屬性值,即為訓練集\(D\)的最優分裂屬性以及最優分裂屬性值。
決策樹的優缺點
決策樹的優點
- 決策樹易於理解和實現,人們在通過解釋後都有能力去理解決策樹所表達的意義。
- 對於決策樹,數據的準備往往是簡單或者是不必要的,其他的技術往往要求先把數據一般化,比如去掉多余的或者空白的屬性。
- 能夠同時處理數據型和常規型屬性。其他的技術往往要求數據屬性的單一。
- 在相對短的時間內能夠對大型數據源做出可行且效果良好的結果。
- 可以處理不相關特征數據。
- 效率高,決策樹只需要一次構建,反復使用,每一次預測的最大計算次數不超過決策樹的深度。
決策樹不需要相關領域知識,學習過程本身有一定的探索性。
決策樹的缺點
- 對有時間順序的數據,需要很多預處理的工作。
- 當類別太多時,錯誤可能就會增加的比較快。
- 一般的算法分類的時候,只是根據一個字段來分類。
- 在處理特征關聯性比較強的數據時表現得不是太好。
決策樹的構建過程是一個遞歸的過程,所以需要確定停止條件,否則過程將不會結束。在決策樹構造的最後一部分雖然提到過解決方案,但是很容易出現過擬合問題。
決策樹的優化
剪枝用於解決決策樹的過擬合問題,分為預剪枝(Pre-Pruning)和後剪枝(Post-Pruning)。
預剪枝(Pre-Pruning)
在構造決策樹的同時進行剪枝。所有決策樹的構建方法,都是在無法進一步降低熵的情況下才會停止創建分支的過程,為了避免過擬合,可以設定一個閾值,熵減小的數量小於這個閾值,即使還可以繼續降低熵,也停止繼續創建分支。但是這種方法實際中的效果並不好。
後剪枝(Post-Pruning)
決策樹構造完成後進行剪枝。剪枝的過程是對擁有同樣父節點的一組節點進行檢查,判斷如果將其合並,熵的增加量是否小於某一閾值。如果確實小,則這一組節點可以合並一個節點,其中包含了所有可能的結果。後剪枝是目前最普遍的做法。
後剪枝的剪枝過程是刪除一些子樹,然後用其葉子節點代替,這個葉子節點所標識的類別通過大多數原則(majority class criterion)確定。所謂大多數原則,是指剪枝過程中, 將一些子樹刪除而用葉節點代替,這個葉節點所標識的類別用這棵子樹中大多數訓練樣本所屬的類別來標識,所標識的類 稱為majority class ,(majority class 在很多英文文獻中也多次出現)。
機器學習系列-決策樹