
翻譯(九)——Clustered Indexes: Stairway to SQL Server Indexes Level 3
原文鏈接:www.sqlservercentral.com/articles/Stairway+Series/72351/
Clustered Indexes: Stairway to SQL Server Indexes Level 3
By David Durant, 2013/01/25 (first published: 2011/06/22)
The Series
本文是階梯系列的一部分:SQL Server索引的階梯。
索引是數據庫設計的基礎,並告訴開發人員使用數據庫大量關於設計者的意圖。不幸的是,當性能問題出現時,索引常常會作為事後考慮添加。這裏最後是一系列簡單的文章,應該能讓數據庫專業人員快速地與它們同步。
前面的水平在這樓梯概述指標一般和專門的非聚集索引。它總結了以下關鍵的SQL服務器索引概念。當請求到達數據庫時,無論是SELECT語句還是插入、UPDATE或刪除語句,SQL Server只有三種可能的方式訪問語句中引用的表的數據:
訪問只是非聚集索引,避免訪問表。只有在索引包含查詢所請求的這個表的所有數據時,才有可能。
使用搜索鍵(s)訪問索引,然後使用所選的書簽訪問表的各個行。
忽略索引並搜索所請求行的表。
這個級別從上面列表中的第三個選擇開始,搜索表。反過來,這將引導我們討論聚集索引;在第2級提到的主題,但沒有包括在內。
初級AdventureWorks數據庫表我們將在這個級別使用的是salesorderdetail表。在121317行中,它足以說明表上有聚集索引的一些好處。而且,有兩個外鍵,它很復雜,足以說明您必須對集群索引做出的一些設計決策。
Sample Database
雖然我們已經在第1級討論了示例數據庫,但現在仍在重復。在整個樓梯中,我們將用例子來說明概念。這些例子都是基於微軟的AdventureWorks示例數據庫。我們專註於銷售訂單。表五將給我們一個很好的組合交易與非交易數據;客戶、銷售人員、產品、salesorderheader,和salesorderdetail。為了使事情集中,我們使用列的一個子集。因為是標準化的銷售人員中,信息被分解成三個表:銷售人員,員工和接觸。
在整個階梯中,我們使用以下兩個術語,即一行互換的單行項:“行項目”和“訂單詳細信息”。前者是比較常見的業務術語;在AdventureWorks表的名稱出現後。
完整的一組表及其之間的關系如圖1所示。
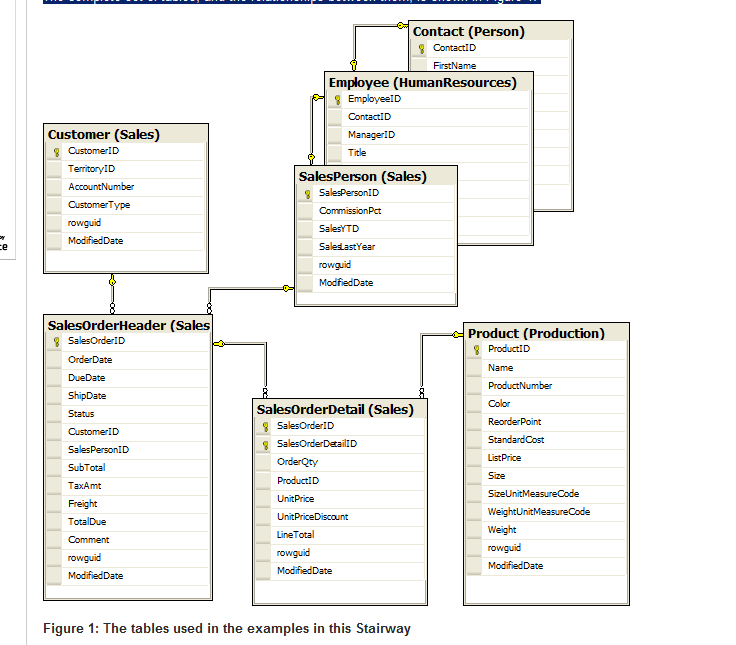
Clustered Indexes
我們開始問這樣的問題:有多少工作需要找到一個排(S)表中如果非聚集索引是不使用?搜索請求行的表是否意味著掃描無序表中的每一行?或者SQL Server永久序列表中的行,它可以快速的搜索關鍵字訪問它們,正如它快速訪問搜索關鍵非聚集索引的條目?答案取決於是否指示SQL Server在表上創建聚集索引。
與非聚集索引,這是一個分離的對象占用的空間,聚集索引的表是一樣的。通過創建聚集索引,您指示SQLServer將表的行排序為索引鍵序列,並在將來的數據修改期間維護該序列。即將出現的級別將查看生成的內部數據結構,以完成此任務。但是現在,將聚集索引看作是一個已排序的表。給定一行的索引鍵值,SQL Server可以快速訪問該行,並可以從該行的表中連續地進行訪問。
出於演示的目的,我們創建了兩個本例表,salesorderdetail;沒有指標和一個聚簇索引。對於索引的鍵列,我們設計師的adventureworksdatabase做出了同樣的選擇:SalesOrderID / salesorderdetailid。清單1中的代碼對SalesOrderDetail表復印件。我們可以隨時重新運行這個代碼,我們希望從一個“幹凈的石板”開始。
IF EXISTS (SELECT * FROM sys.tables  WHERE OBJECT_ID = OBJECT_ID(‘dbo.SalesOrderDetail_index‘)) DROP TABLE dbo.SalesOrderDetail_index; GO IF EXISTS (SELECT * FROM sys.tables  WHERE OBJECT_ID = OBJECT_ID(‘dbo.SalesOrderDetail_noindex‘)) DROP TABLE dbo.SalesOrderDetail_noindex; GO
SELECT * INTO dbo.SalesOrderDetail_index FROM Sales.SalesOrderDetail;
SELECT * INTO dbo.SalesOrderDetail_noindex FROM Sales.SalesOrderDetail;
GO
CREATE CLUSTERED INDEX IX_SalesOrderDetail
ON dbo.SalesOrderDetail_index (SalesOrderID, SalesOrderDetailID)
GO
Listing 1: Create copies of the SalesOrderDetail table
所以,假設SalesOrderDetail表看起來像這樣在創建聚集索引:
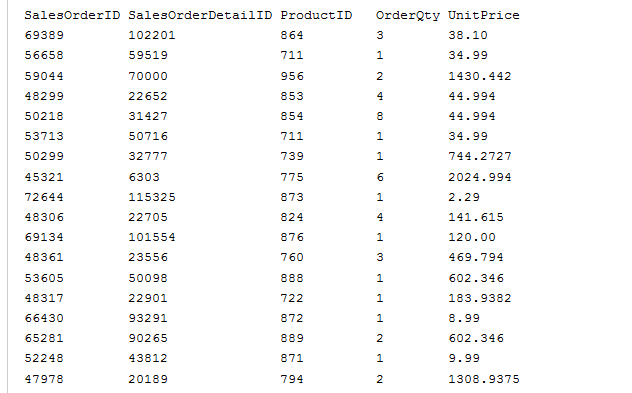
在創建上面顯示的聚集索引之後,生成的表/聚集索引將如下所示:
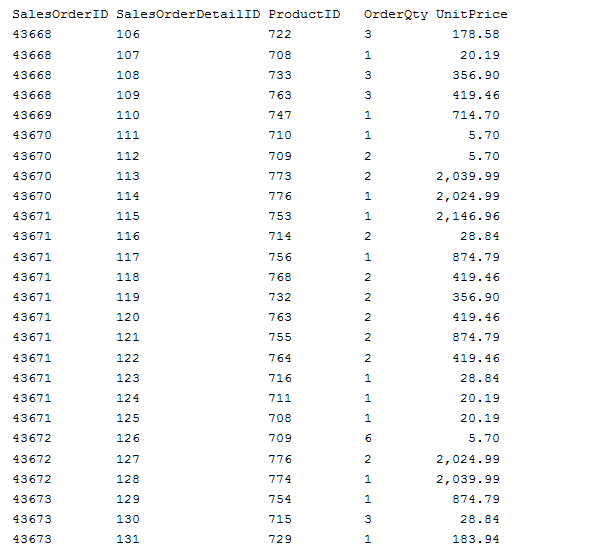
你看上面的示例數據,你會發現每個salesorderdetailid值是唯一的。Do not be confused; SalesOrderDetailID is not the primary key of the table. 對salesorderdetailid SalesOrderID /組合是表的主鍵;以及聚集索引的索引鍵。
Understanding the Basics of Clustered Indexes
每個表最多可以有一個聚集索引。表的行只能在一個序列中。您需要決定什麽順序(如果有的話)對每一個表最好,如果可能的話,在表充滿數據之前,創建聚集索引。做這個決定時,要記住,排序不僅意味著訂貨,還意味著分組;如按銷售訂單分組行項。
這就是為什麽在adventureworksdatabase設計師選擇在SalesOrderID salesorderdetailid為SalesOrderDetail表的順序;它是商品的自然順序。
例如,如果用戶請求一個訂單的行項,他們通常會請求該訂單的所有行項目。一個典型的銷售訂單表格告訴我們,訂單的打印副本總是包含所有的行項。銷售訂單業務的性質是按銷售訂單對生產線項目進行分組。有可能從倉庫想要的產品而不是銷售訂單行項目偶爾觀要求;但大多數的請求;如從銷售人員或客戶,或該程序打印發票,或一個查詢,計算每個訂單的總價值;需要所有的行項目對於任何給定的銷售訂單。
然而,用戶需求本身並不能決定什麽是最好的聚集索引。本系列中的未來級別將涵蓋索引的內部;因為索引的某些內部方面也會影響您選擇的聚集索引列。
Heaps
如果表上沒有聚集索引,則該表稱為堆。每個表要麽是堆,要麽是聚集索引。所以,雖然我們經常認為每個指標分為兩種類型之一,聚集或非聚集;需要註意的是,每一個表分成兩個類型同樣重要;它是一個聚集索引或是一堆。開發人員經常說表“有”或“沒有”聚集索引,但是說表“是”或“不是”是一個更有意義的聚集索引。
有SQL Server搜索一堆當尋找行只有一個方法(不包括非聚集索引的使用),這是開始在表中的第一行並進行表直到所有的行被讀取。沒有序列,沒有搜索鍵,無法快速導航到特定行。
Comparing a Clustered Index with a Heap
評價一個聚集索引和一堆的性能,使兩份清單1的salesorderdetailtable。一份是堆版,另一方面,我們創造了相同的聚集索引,即對原表(SalesOrderID,SalesOrderDetailID)。既有非聚集索引的表。
我們將對表的每一個版本執行相同的三個查詢;一個檢索單個行,一個檢索一個訂單的所有行,另一個查詢單個產品的所有行。我們在下面的表中展示了SQL和每個執行的結果。
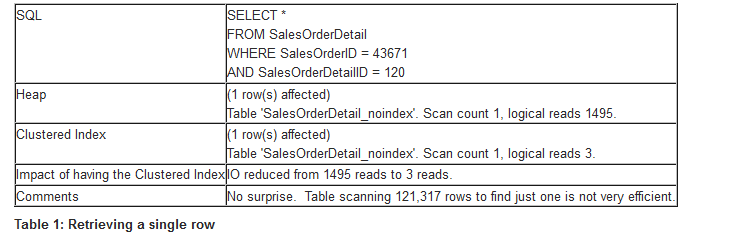
我們的第一個查詢檢索一行,執行細節如表1所示。
我們的第二個查詢檢索單個銷售訂單的所有行,您可以在表2中看到執行細節。

我們的第三查詢檢索單個產品的所有行,執行結果如表3所示。

我們的第一個查詢大大受益於聚集索引的存在;第三是大致相等的。聚集索引是否有危害?答案是肯定的,它主要與插入、更新和刪除行有關。就像在早期階段遇到的索引的許多其他方面一樣,它也是一個更高層次更詳細地討論的主題。
一般來說,檢索的好處大於維修的危害;使聚集索引比一堆。如果在Azure數據庫中創建表,則沒有選擇;每個表必須是一個聚集索引。
Conclusion
聚集索引是一個排序表,它在索引創建時由您指定,由SQLServer維護。該表中的任何行都可以很快地訪問它的鍵值。索引鍵序列中的任何一組行,也可以在鍵的範圍內快速訪問。
每個表只能有一個聚集索引。哪些列應該是聚集索引鍵列的決定是您對任何表所作的最重要的索引決策。
在我們的第4級中,我們將重點從邏輯到物理,引入頁面和範圍,並檢查索引的物理結構。
Downloadable Code
- Clustered.SQL
翻譯(九)——Clustered Indexes: Stairway to SQL Server Indexes Level 3