
Word2Vec-語言模型的前世今生
引言

在機器學習領域,語言識別和圖像識別都比較容易做到。語音識別的輸入數據可以是音頻頻譜序列向量所構成的matrix,圖像識別的輸入數據是像素點向量構成的矩陣。但是文本是一種抽象的東西,顯然不能直接把文本數據餵給機器當做輸入,因此這裏就需要對文本數據進行處理。
現在,有這麽一個有趣的例子,我接下來要講的模型就可以做到。
- 首先給出一個例子,Paris - France + America = ?
從我們人的角度來看,Paris是法國的首都,那麽首都減去國家再加上一個國家,很可能表示的就是另一個國家的首都。因此這裏的結果就是華盛頓Washington.機器想做到這一點,並不容易。
眾所周知,只有標量或者向量可以應用加減法,抽象的自然語言該如何做到呢?
一個很自然的想法就是,自然語言能否表示成數學的形式,這樣就可以更加方便地研究其規律了。
答案是肯定的。
現在我們可以進行思考,如何將文本中的詞語用數學的形式表達出來,也就是說,文本中藏著哪些數學形式需要我們去挖掘。
文本中各個詞語出現的頻數是有限的,這是一個可以提取的數學形式
從邏輯的角度出發,詞語之間不可能是獨立的,一個詞語的出現肯定與另一個或者若幹個詞語有關系。這就涉及到詞語共現的層面了。
統計語言模型和大多數的詞向量表示都是基於以上兩點考慮的。
詞向量的表現形式主要分為兩種,一種是one-hot(one-hot representation)表示方式,將詞表示成一個很長的向量,向量的長度就是詞典的長度;另一種表示方法是分布式表示(distributed representation).同時,分布式表示方法又可以分為基於矩陣的表示方法、基於聚類的表示方法和基於神經網絡的表示方法。
首先,最簡單的就是one-hot表示方法,將詞表示成一個很長的向量,向量的分量只有一個1,其他全為0,1所對應的位置就是該詞在詞匯表中的索引。
這樣表示有兩個缺點:
容易受維度災難(the curse of dimentionality)的困擾;
沒有考慮到詞之間的關系(similarity)。
現在主要應用的都是分布式表示形式了。下面介紹一種簡單的分布式表示形式——基於矩陣的表示形式。
如下表所示:
| Probability and Ratio | k = solid | k = gas | k = water | k = fashion |
|---|---|---|---|---|
| \(p(k\vert ice)\) | \(1.9\times 10^{-4}\) |
\(6.6\times 10^{-5}\) | \(3.0\times 10^{-3}\) | \(1.7\times 10^{-5}\) |
| \(p(k\vert steam\)) | \(2.2\times 10^{-5}\) | \(7.8\times 10^{-4}\) | \(2.2\times 10^{-3}\) | \(1.8\times 10^{-5}\) |
| \(p(k\vert ice)/(p(k\vert steam)\) | \(8.9\) | \(8.5\times 10^{-2}\) | \(1.36\) | \(0.96\) |
簡單說一下上面的矩陣。
假設我們對一些熱力學短語或者詞語的概念感興趣,我們選擇i=ice,k=steam,我們想看看ice和steam的關系,可以通過他們與其他詞語的共現頻率來研究。這些其他詞語我們稱之為探測詞。這裏我們選擇探測詞k為solid,gas,water和fashion。顯然,ice與solid的相關性較高,但是與steam相關性較低,因此我們期望看到的是\(p_{ik}/p_{jk}\)比值比較大。對於探測詞gas,我們期望看到的是\(p_{ik}/p_{jk}\)比值比較小。而water和fashion與ice和steam的關系要麽都十分密切,要麽都不怎麽密切,因此對於這兩個探測詞,\(p_{ik}/p_{jk}\)應該接近於1.
上表是基於一個很大的語料庫統計得出的,符合我們的預期。相比於單獨使用原始概率,概率比值可以更好的區分相關詞語和不相關詞語,比如solid和gas與water和fashion;也可以很容易區分兩個相關詞。
那麽,在正式介紹自然語言處理,或者說wrod2vec之前,有必要介紹以下統計語言模型。它是現在所有語言模型的基礎。
第二個需要講的分布式表示方式是基於神經網絡的表示方法。在此之前,有必要講一下傳統的統計語言模型,畢竟它對語言模型影響深遠。
統計語言模型
1. 引言
給出以下三個句子:
美聯儲主席本·伯南克昨天告訴媒體7000億美元的救助資金將借給上百家銀行、保險公司和汽車公司
美主席聯儲本·伯南克告訴昨天媒體7000億美元的資金救助將借給百上家銀行、保險公司和汽公車司
美主車席聯儲本·克告訴昨天公司媒體7000伯南億美行元的金將借給百救助上家資銀、保險公司和汽對於第一個句子,語句通暢,意思也很不明白;對於第二個句子,雖然個別詞語調換了位置,但也不影響閱讀,我們仍然能夠知道表達的是什麽意思;對於第三個句子,我們就很難知道具體表示什麽意思了。
如果問你為什麽第三個句子不知道表達什麽,你可能會說句子混亂,語義不清晰。在上個世紀70年代的時候,科學家們也是這樣想的,並且試圖讓計算機去判斷一個句子的語義是否清晰,然而,這樣的方法是走不通的。
賈裏尼克想到了一種很好的統計模型來解決上述問題。判斷一個句子是否合理,只需要看它在所有句子中出現的概率就行了。第一個句子出現的概率大概是\(10^{-20}\),第二個句子出現的概率大概是\(10^{-25}\),第三個句子出現的概率大概是\(10^{-70}\),第一個句子出現的可能性最大,因此這個句子最為合理。
那麽,如何計算一個句子出現的概率呢,我們可以把有史以來人類說過的話都統計一遍,這樣就能很方便的計算概率了。然而,你我都知道這條路走不通。
假設想知道S在文本中出現的可能性,也就是數學上所說的S的概率,既然\(S=w_1,w_2,...,w_n\),那麽不妨把S展開表示,
\[P(S)=P(w_1,w_2,...,w_n)\]
利用條件概率的公式,S這個序列出現的概率等於每一個詞出現的條件概率的乘乘積,展開為:
\[P(w_1,w_2,...,w_n)=P(w_1)P(w_2\vert w_1)P(w_3\vert w_1,w_2)\cdots P(w_n\vert w_1,w_2,\cdots w_{n-1})\],
計算\(P(w_1)\)很容易,\(P(w_2\vert w_1)\)也還能算出來,\(P(w_3\vert w_1,w_2)\)已經非常難以計算了。
2. 偷懶的馬爾科夫(Andrey Markov)
假設上面的n不取很長,而只取2個,那麽就可以大大減少計算量。即在此時,假設一個詞\(w_i\)出現的概率只與它前面的\(w_{i-1}\)有關,這種假設稱為1階馬爾科夫假設。
現在,S的概率就變得簡單了:
\[P(w_1,w_2,...,w_n) \approx P(w_1)P(w_2\vert w_1)\]
那麽,接下來的問題就變成了估計條件概率\(P(w_i\vert w_{i-1})\),根據它的定義,
\[P(w_i\vert w_{i-1}) = \frac{P(w_i,w_{i-1})}{P(w_{i-1})}\],
當樣本量很大的時候,基於大數定律,一個短語或者詞語出現的概率可以用其頻率來表示,即
\[P(w_i,w_{i-1}) \approx \frac{count(w_i,w_{i-1})}{count(*)}\]
\[P(w_{i-1}) \approx \frac{count(w_{i-1})}{count(*)}\]
其中,\(count(i)\)表示詞\(i\)出現的次數,\(count\)表示語料庫的大小。
那麽
\[P(w_i\vert w_{i-1}) = \frac{P(w_i,w_{i-1})}{P(w_{i-1})} \approx \frac{count(w_i,w_{i-1})}{count(w_{i-1})}\]
3. 高階語言模型
在前面的模型中,每個詞只與前面1個詞有關,和更前面的詞就沒有關系了,這似乎簡單的有點過頭了。那麽,假定每個詞\(w_i\)都與前面的N-1個詞有關,而與更前面的詞無關,這樣,當前詞的概率只取決於前面N-1個詞的聯合概率,即
\[P(w_1\vert w_1,w_2,\cdots w_{i-1}) \approx P(w_1\vert w_{i-N+1},w_{i-N+2},\cdots w_{i-1})\],
上面這種假設被稱為n-1階馬爾科夫假設,對應的模型稱為N元模型。N=2就是二元模型,N=1其實就是上下文無關的模型,基本不怎麽使用。
上面的模型看起來已經很完美了,但是考慮以下兩個問題,對於二元模型:
如果此時\(count(w_i,w_{i-1})=0\),是否可以說\(P(w_i\vert w_{i-1})=0\) ?
如果此時\(count(w_i,w_{i-1})=count(w_{i-1})\),是否可以說\(P(w_i\vert w_{i-1})=1\) ?
顯然,不能這麽武斷。
但是,實際上上述兩種情況肯定是會出現的,尤其是語料足夠大的時候,那麽,我們怎麽解決上述問題呢?
古德和圖靈給出了一個很漂亮的重新估計概率的公式,這個公式後來被稱為古德-圖靈估計。
古德圖靈的原理是:
對於沒有看見的事件,我們不能認為他發生的概率就是0,因此從概率的總量中,分配一個很小的比例給這些沒有看見的事件。這樣一來,看見的那些事件的概率就要小於1了,因此,需要將所有看見的事件的概率調小一點。至於小多少,要根據“越是不可信的統計折扣越多”的方法進行。假定在語料庫中出現\(r\)次的詞有\(N_r\)個,特別的,未出現的詞數量為\(N_0\),語料庫大小為\(N\),那麽,很顯然,
\[N = \sum _{r=1}^ \infty rN_r\],
出現\(r\)次的詞在整個語料庫中的相對頻度則是\({rN_r}/{N}\),如果不做任何處理,這個相對頻度作為這些詞的概率。但是當\(r\)比較小的時候,統計上可能不可靠,因此需要使用一個更小的次數\(d_r\)來表示,古德-圖靈按照如下公式計算\(d_r\):
\[d_r=(r+1)\cdot N_{r+1}/N_r\],
顯然
\[\sum_r d_r\cdot N_r = \sum_r (r+1)\cdot N_{r+1} = N\],
此時,
\[d_0 = (0+1)\cdot N_1/N_0 = \frac{N_1}{N_0} > 0\]
在實際處理的時候,一般對出現次數超過某個閾值的詞,頻率不下調。
基於這種思想,估計二元模型概率的公式如下:
\[P(w_i\vert w_{i-1})= \begin{cases} f(wi\vert w_{i-1}) & {if\quad count(w_{i-1},w_i)} \ge T \f_{gt}(w_i\vert w_{i-1})& if\quad 0 \le count(w_{i-1},w_i) < T \Q(w_{i-1})\cdot f(w_i) & otherwise \end{cases}\],
其中,\(f(\cdot)\)表示相對頻度,即頻率。
\[Q(w_{i-1})=\frac{1-\sum_{w_i\quad seen}P(w_i \vert w_{i-1})}{\sum _{wi\quad unseen}f(w_i)}\]
上面這種方法稱為卡茨退避法。
n-gram模型的作用就是,基於語料庫計算出各種詞串出現的概率,遇到一個句子的時候,可以直接使用上面所計算的概率,把所有的概率連乘,就得到了整個句子的概率。
4. 機器學習的思想
機器學習的套路是,對所研究的問題建模,構造一個目標函數,然後優化參數,最後用這個目標函數進行預測。
對於統計語言模型,常使用最大對數似然作為目標函數,即
\[L = \sum_{w\in C}logP(w\vert context(w))\],
在n-gram模型中,\(context(w_i) = (w_{i-n+1},w_{i-n+2},\cdots,w_{i-1})\),
由此可見,概率\(P(w_i\vert context(w_i))\)是關於\(w\)和\(context(w)\)的函數,即
\[P(w\vert context(w)) = F(w,context(w),\theta)\],
一旦\(F\)確定下來了,任何概率都可以使用這個函數進行計算了。
似乎到這裏,我們仍然不知道詞向量是什麽,因為n-gram模型中根本沒有用到詞向量。那麽,接下來將要介紹的神經網絡語言模型則是實實在在用到了詞向量。之所以提到統計語言模型,是因為它是其他語言模型的基礎,我們得知道語言模型是幹嘛的,然後再對語言模型進行展開。
神經網絡語言模型
上面介紹的n-gram模型相信我們已經十分清楚了,但是n-gram模型的一個突出的確定就是,n的設置不宜過大,n從2到3提升效果顯著,但是從3-4提升的效果就沒那麽好了。而且隨著n的增大,參數的數量是以幾何形勢增長的。
因此,n-gram模型只能提取某個詞前面兩到三個詞的信息,而不能提取更多的信息了。然而很明顯的是,整文本序列中,包含更前面的詞能夠提供比僅僅2到3個詞更多的信息,這也是神經網絡語言模型著重要解決的問題之一。
神經網絡模型主要在以下兩點上尋求更大的進步:
n-gram模型沒有考慮上下文中更多的詞提供的信息
n-gram模型沒有考慮詞與此之間的相似性。
舉個栗子:
如果在一個語料庫中,"the cat is walking in the bedroom"出現了5000次,而"a dog is running in the room"只出現了5次,n-gram模型得出的結果是前面一個句子的可能性會比後面一個句子大得多。但是實際上,這兩個句子是相似的,他們在真實的情況下出現的概率也應該是相仿的。
神經網絡語言模型可以概括為以下三點:
將詞匯表中的每個詞表示成一個在m維空間裏的實數形式的分布式特征向量
使用序列中詞語的分布式特征向量來表示連接概率函數
同時學習特征向量和概率函數的參數
特征向量表示詞的不同特征:每一個詞都是向量空間內的一個點。特征的個數通常都比較小,比如30,60或者100,遠遠小於詞匯表的長度。概率函數是在給定一個詞前面的若幹詞的情況下,該詞出現的條件概率。調整概率函數的參數,使得訓練集的對數似然達到最大。每個詞的特征向量是通過訓練得到的,也可以用先驗知識進行初始化。
訓練集是詞序列\(W_1,W_2,...,W_T,W_T\in V\),\(V\)是詞匯表,是一個很大但是有限的集合。
目標是找到一個好的模型,使得\(f(W_t,...,W_{t-n+1})=\hat{P}(W_t|W_1^{n-1})\)
唯一的約束條件是\(\sum _{i=1}^{|V|}f(i,W_{t-1},...,W_t-n+1)=1,f>0\)
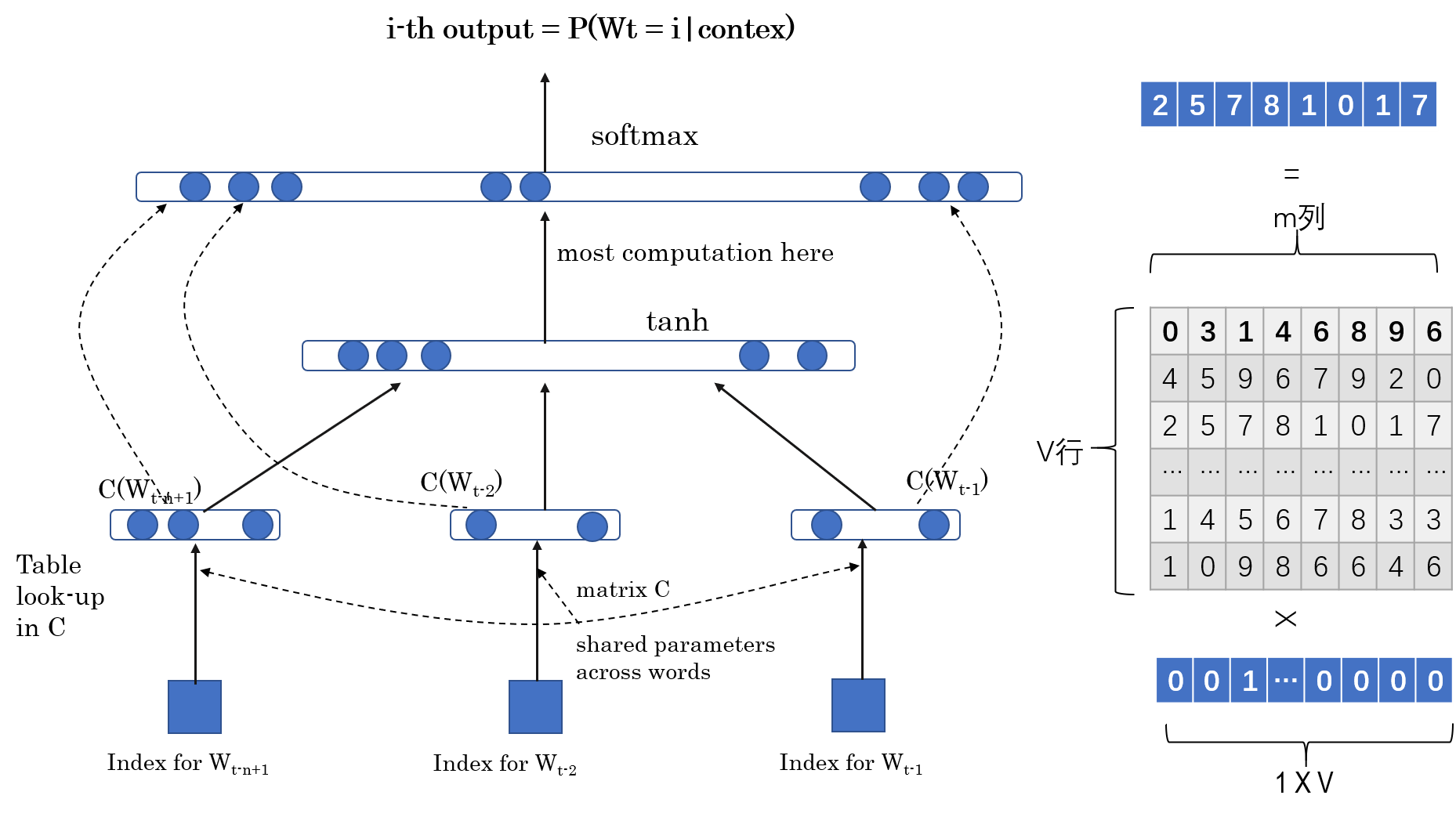
我們將函數\(f(W_t,...,W_{t-n+1})\)分解為以下兩個部分:
映射\(C\),將\(V\)中的所有元素映射為真實的向量\(C(i)\in R^m\),\(C(i)\)代表詞匯表中的每個詞的分布式特征向量,實際上,\(C\)是一個由自由參數構成的\(|V|\times m\)矩陣。其中\(|V|\)代表詞匯表的大小,也就是詞匯表中的詞數量。
每個詞的概率函數是由\(C\)來表示的:函數\(g\)將輸入的詞特征向量\((C(W_{t-n+1}),...,C(W_{t-1}))\)映射為詞\(W_t\)前面\(n-1\)個詞的條件概率分布。
\[f(i,W_{t-1},...,W_{t-n+1})=g(i,C(W_{t-1}),...,C(W_{t-n+1}))\]
函數\(f\)是由兩個映射組成的(\(C\&g\)),\(C\)是所有詞共享的。每一個部分都與一些參數有關。
映射\(C\)的參數實際上就是特征向量本身,表示為一個\(|V|\times m\)矩陣,矩陣的每一行代表詞\(i\)的特征向量\(C(i)\).
函數\(g\)的參數是\(\omega\),所有的參數就是\(\theta = (C,\omega)\).
當尋找到使得帶懲罰項的訓練語料庫的對數似然率最大的\(\theta\),那麽訓練完成。
\[L = \frac{1}{T}\sum _t log f(W_t,W_{t-1},...,W_t-n+1)+R(\theta)\]
\(R(\theta)\)是懲罰項,只作用於神經網絡的權重和矩陣\(C\)。自由參數的規模是\(V\)的線性函數,也是\(n\)的線性函數。
在下面的大多數試驗中,神經網絡只有一個隱藏層,外加一個映射層。還有一個可選的直連層。所以說實際上有兩個隱藏層,但是由於影射層只是做了一個線性變換,並沒有添加新的信息,因此不能視為真正的隱藏層。所以真正的隱藏層就只有一個。
從圖中可以看出,最底層實際上就是一些單一的詞,表示成one-hot形式,即長度為詞匯表的長度。然後,每個one-hot向量分別與投影矩陣C相乘,則原來長度為\(|V|\)的one-hot向量,經過線性變換以後,縮短為一個長度為\(m\)的向量,其中m就是我們設置的特征的個數,一般在2個數量級。投影完成以後,將所有的特征向量按照順序首尾相連,形成一個長度為\(m(n-1)\)的向量,以詞向量作為隱藏層的輸入,隱藏層的激活函數為雙曲正切函數\(tanh\)。輸出層接受隱藏層的輸出作為輸入,經過一個softmax函數進行轉換,得到最終的輸出P.
即
\[\hat{P}(w_t\vert w_{t-1},...,w_{t-n+1})=\frac{e^{y_{w_t}}}{\sum_i e^{y_i}}\],
其中
\[y = b+Wx + Utanh(d+Hx)\]
雙曲正切函數逐個應用於隱藏層的各個單元。當沒有直連的時候,\(W=0\),\(x\)是首尾相連的特征向量:
\[x = (C(w_{t-1}),C(w_{t-2}),...,C(w_{t-n+1}))\]
令\(h\)是隱藏層的單元數,\(m\)是特征向量的長度,當沒有直連的時候,\(W=0\)。那麽,所有的自由參數就是:
輸出層的偏置\(b\),長度為|V|
隱藏層的偏置\(d\),長度為\(h\)
隱藏層到輸出層的權重矩陣\(U\),是一個\(|V|\times h\)矩陣
詞向量到輸出層的權重矩陣\(W\),是一個\(|V|\times (n-1)m\)矩陣
隱藏層權重\(H\),是一個\(h\times (n-1)m\)矩陣
特征矩陣\(C\),是一個\(|V|\times m\)矩陣
此時的輸出\(y\)實際上是一個長度為\(|V|\)的向量,那麽分量\(y_{wt}\)不能表示給出前(n-1)個詞的情況下\(w_t\)的概率,因此需要進行一次歸一化。
那麽,我們所有的參數如下:
\[\theta = (b,d,W,U,H,C)\]
主要的計算量都集中在隱藏層到輸出層的以及輸出層的歸一化計算。
使用隨機梯度下降進行參數求解:
\[\theta \leftarrow \theta + \epsilon\frac{\partial log \hat{P}(w_t\vert w_{t-1},w_{t-2},w_{t-n+1})}{\partial \theta}\]
其中,\(\epsilon\)是學習率。
當訓練結束以後,矩陣\(C\)就是我們需要的詞向量,每一行代表該位置的詞的向量。得到了詞向量,就可以進行許多有趣的分析。
比如:
文本聚類
計算文本相似度
其他應用
Skip-Gram 模型
基本版的skip-gram模型是十分簡單的。我們將會訓練一個只有一個隱藏層的簡單的神經網絡來完成我們的任務,但是當神經網絡訓練完成以後,我們實際上並不使用這個網絡做什麽,而是獲得隱藏層的權重矩陣,這個矩陣實際上就是我們需要的詞向量(word vectors)
skip-gram模型需要完成這樣的工作:給定一個詞,預測其周圍的詞,或者說在其附近的詞。這個神經網絡將會計算出我們從詞匯表中選出的每個“候選”鄰居詞的概率。
這裏的附近需要說明一下,實際上在算法裏有一個"window size"參數,用來控制窗口大小,如果選擇參數的值為5,則會預測該詞前後各5個詞的概率。
skip-gram模型的輸入需要經過特殊的調整,不同於上述神經網絡語言模型,應該首先將這裏的語料整理成詞對(word-pair)。
比如對於語句"The quick brown fox jumps over the lazy dog."此處我們選擇window size = 2.
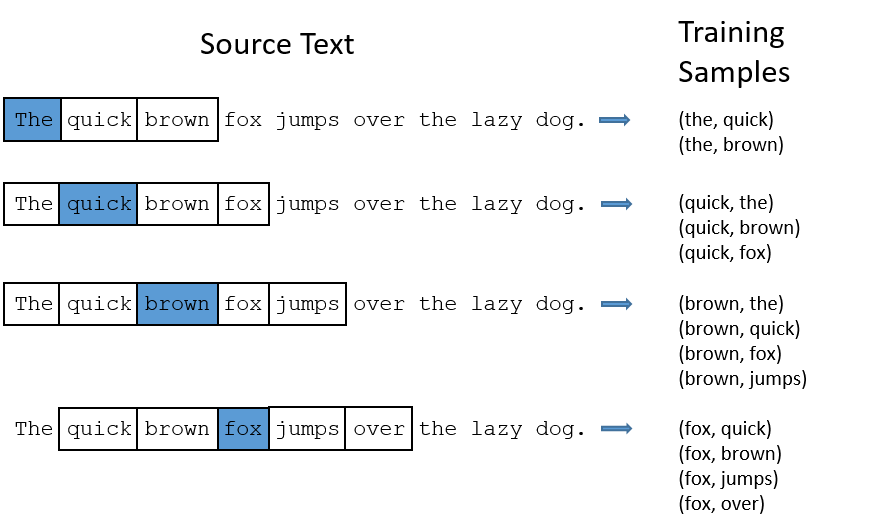
具體操作如圖所示:
對於單詞"The",取其前後兩個詞與其湊成詞對,這裏"The"前面沒有單詞,因此取後面兩個,湊成兩個詞對,分別是(the,quick),(the,brown)。
對於單詞quick,其前面有1個單詞,後面有2個單詞,可以湊成3對,分別為:(quick,the),(quick,brown),(quick,fox)。
對於單詞brown,其前面有兩個單詞,後面有兩個單詞,可以湊成4對,分別是:(brown,the),(brown,quick),(browm,fox),(brown,fox)。
以此類推,可以把語料庫中的所有文本調整成上述詞對。
所有的詞對都應該是(input,output)形式。
有了詞對,接下來看一下skip-gram的最簡單的模型長什麽樣子。

在上圖中,可以清晰地看出,skip-gram模型是一個簡單的神經網絡,有一個隱藏層(實際上在作者的論文中是以投影層的形式表述的),該隱藏層並沒有對應的激活函數。
輸入數據仍然是one-hot向量,向量只有一個分量是1,其他全為0.向量的長度為詞匯表的長度。
對下面所要用的符號進行說明:
\(i\):輸入的one-hot向量,長度為|V|
\(|V|\):詞匯表的長度
\(P\):輸入層到投影層的\(|V|\times m\)權重矩陣
\(W\):投影層到輸出層的\(m\times |V|\)權重矩陣
\(y\):輸出層輸出結果
由於這個神經網絡沒有激活函數,因此看起來比較簡單。
神經網絡的計算過程如下:
首先,將輸入詞向量(one-hot)投影到隱藏層(投影層),即\(i^T\times P=1\times |V|\times |V| \times m=1\times m\)
將隱藏層的結果乘以隱藏層到輸出層的權重矩陣\(W\),即\(1\times m \times m\times |V|=1\times |V|\)
將輸出層的輸出結果進行softmax歸一化,即
\[y=\frac{e^{y}}{\sum_{i\in y}e^i }\]
此時\(y\)是一個\(1\times |V|\)向量,向量的每個分量代表給定詞\(w_i\)的情況下,其相鄰詞是詞匯表中對應詞的概率。將\(y\)與output的one-hot向量相乘,就可以得到給定\(w_i\)的情況下,其相鄰詞是output的概率,即
\[P(w_o\vert w_i)=y\times w_o\],
其中,\(w_o\)是詞output的向量形式。
以上矩陣相乘只是為了說明維度變化,並不是實際上的矩陣乘法。
用矩陣說明如下:
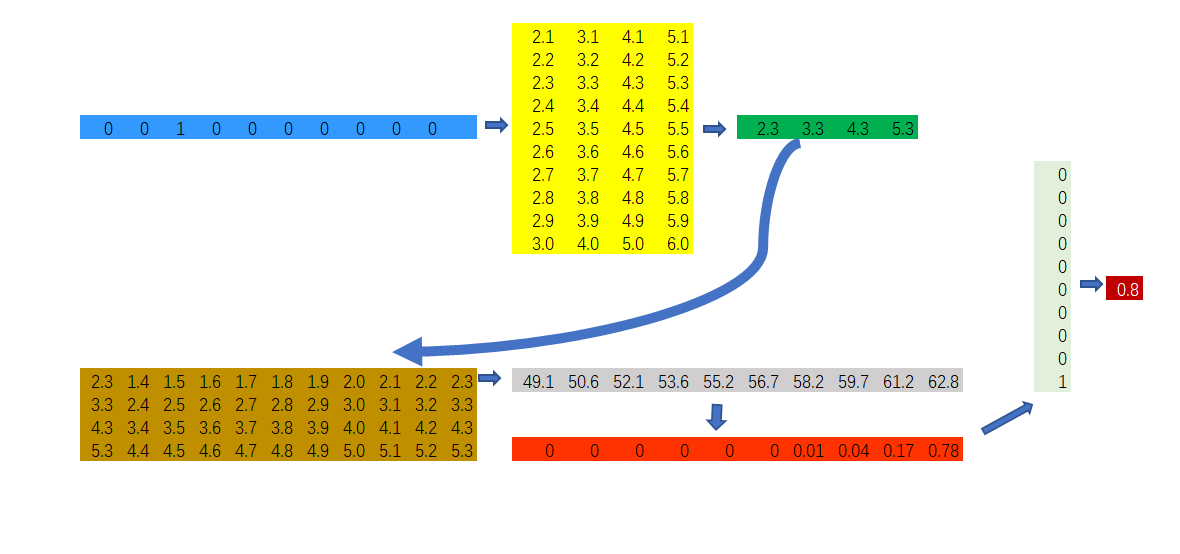
假定我們的詞庫大小為10,輸出層到投影層的權重矩陣為\(10\times 4\)矩陣。
我們的輸入樣本是詞對(brown,quick).其中,brown的one-hot表示形式如圖中的藍色向量所示,quick的one-hot表示形式如圖中的淺綠色向量所示。
藍色向量是我們的輸入向量,即one-hot向量
黃色矩陣是輸入層到投影層的權重矩陣
綠色向量是輸入向量與第一個權重矩陣的向量乘積
棕色矩陣是投影層到輸出層的權重矩陣
灰色向量是綠色向量與棕色矩陣的矩陣乘積
紅色向量是對灰色向量進行了一次\(softmax\)歸一化計算
淺綠色矩陣是詞對中的輸出詞對應的one-hot向量
深紅色數值是我們計算出的輸出詞對應的概率
skip-gram的目標是對於訓練樣本\(w_1,w_2,\cdots,w_T\),最大化如下平均對數似然概率:
\[\frac{1}{T}\sum _{t=1}^T\sum_{-c\le i\le c,j\ne 0}log p(w_{t+j}\vert w_t)\]
實際上,以上模型是難以實現的,因為計算 \(\nabla logp(w_O\vert w_I)\)的代價隨著\(W\)的增大而增大(W表示詞匯表的長度),經常達到\(10^5-10^7\)數量級。
Hierarchical Softmax
哈夫曼樹
哈夫曼樹是一種最優二叉樹,它是這樣定義的:
給定n個權值作為n個葉子結點,構造一棵二叉樹,若帶權路徑長度達到最小,稱這樣的二叉樹為最優二叉樹。哈夫曼樹的構造方法如下:
(1) 將\(w_1,w_2,\cdots,w_n\)看成是有n 棵樹的森林(每棵樹僅有一個結點);
(2) 在森林中選出兩個根結點的權值最小的樹合並,作為一棵新樹的左、右子樹,且新樹的根結點權值為其左、右子樹根結點權值之和;
(3)從森林中刪除選取的兩棵樹,並將新樹加入森林;
(4)重復(2)、(3)步,直到森林中只剩一棵樹為止,該樹即為所求得的哈夫曼樹
假設我們的權值為:26 24 15 10 17 18 10 27
首先對上面的權值按照從小到大排序:
排序後的權值為:10 10 15 17 18 24 26 27然後。我們按照上述步驟構建哈夫曼樹。
此處我們約定將大的權值放在左子樹。
---Begin
選擇最小的兩個權值10,10,合並成一個新樹的左右子樹。新樹的權值為20,刪除合並的兩個權值,將20加入到森林,此時的權值為(仍然進行排序):15 17 18 20 24 26 27
選擇最小的15和17合並,刪除15和17,將32加入到森林,此時的權值為:18 20 24 26 27 32
選擇最小的18和20合並,刪除18和20,將38加入到森林,此時的權值為:24 26 27 32 38
選擇最小的24和26合並,刪除24和26,將20加入到森林,此時的權值為:27 32 38 50
選擇最小的27和32合並,刪除27和32,將59加入到森林,此時的權值為:38 50 59
選擇最小的38和50合並,刪除38和50,將88加入到森林,此時的權值為:59 88
選擇最小的59和88合並,刪除59和88,將147加入到森林,此時的權值為:147
---End
根據上述權值構造的哈夫曼樹如下:

背景為黃色的是新生成的樹
邏輯回歸
邏輯回歸通常用來處理二分類問題,因變量通常只有兩個可能的取值,自變量既可以是連續型變量,也可以是分類變量。
利用sigmoid函數,對於任意的樣本\(x=(x_1,x_2,\cdots,x_n)^T\),可將二分類問題的h函數(hypothesis)寫成如下形式:
\[h_\theta(x)=\sigma(\theta_0+\theta_1x_1+\cdots+\theta_nx_n)\],
其中\(\theta =(\theta_0,\theta_1,\cdots,\theta_n)\)為待定參數,為了簡化起見,可以引入\(x_0=1\)將\(x\)擴展為\((x_0,x_1,\cdots,x_n)\),於是,\(h_\theta\)可簡寫為
\[h_\theta(x)=\sigma(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}}\]
sigmoid函數圖像如下:
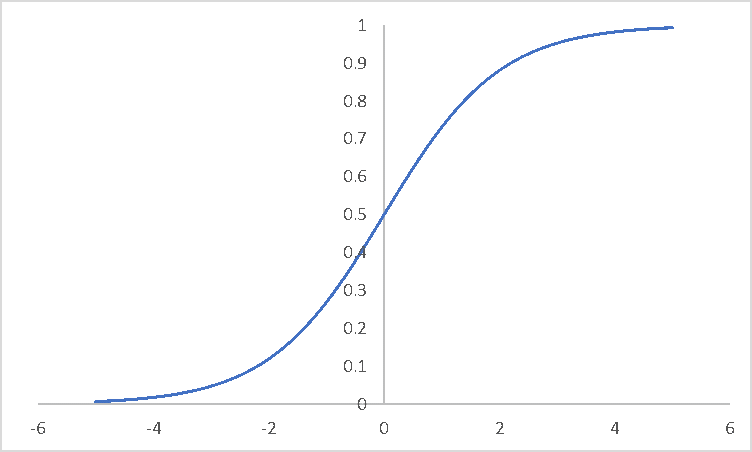
函數\(h_\theta(x)\)的值有特殊的含義,它表示結果取1的概率,因此對於輸入\(x\),分類結果為類別1和類別0的概率分別為:
\[P(y=1\vert x;\theta)=h_\theta(x)\]
\[P(y=0\vert x;\theta)=1-h_\theta(x)\]
上式也可以寫成如下綜合形式:
\[P(y\vert x;\theta)=(h_\theta(x))^y(1-h_\theta(x))^{1-y}\]
sigmoid函數具有很好的導數特征
已知
\[\sigma(x) = \frac{1}{1+e^{-x}}\]
則
\[\sigma(x)^{'}=\frac{e^{-x}}{(1+e^{-x})^2}=\sigma(x)(1-\sigma(x))\]
另外
\[[log\sigma(x)]^{'}=1-\sigma(x),[log(1-\sigma(x))^{'}=- \sigma(x)\]
Hierarchical Softmax
hierarchical softmax使用一顆二叉樹的葉子結點來代表輸出層對應詞匯表中每個詞的輸出結果。每個結點都代表了它的孩子結點的相關概率。這種方式定義了一種給詞分配概率的隨機遊走解決方案。
準確地說,從根結點出發,每一個詞都能以一條確定的路徑抵達。對所使用的符號作如下闡述:
\(w\):代表詞匯表中的詞,用葉子結點表示
\(n(w,j)\):從根結點到達某個葉子結點的路徑上的第\(j\)個結點,根結點為第一個結點
\(L(w)\):路徑的長度,也就是結點的個數
因此,\(n(w,1)=root,n(w,L(w))=w\)
\(n\):非葉子結點
\(ch(n)\):非葉子結點的孩子結點
\([[x]]\):if x is true,than 1,else than -1
hierarchical softmax定義\(P(w_o\vert w_i)\)如下:
\[P(w\vert w_i)=\prod_{j=1}^{L(w)-1}\sigma([[n(w,j+1)=ch(n(w,j))]]\cdot (v^{'}_{n(w,j)})^T v_{w_i})\]
其中
\[\sigma(x)=1/(1+e^{-x})\]
可以證明:
\[\sum _{i=1}^Wp(w\vert w_i)=1\]
那麽,hierarchical softmax框架下的skip-gram結構是什麽樣的呢?
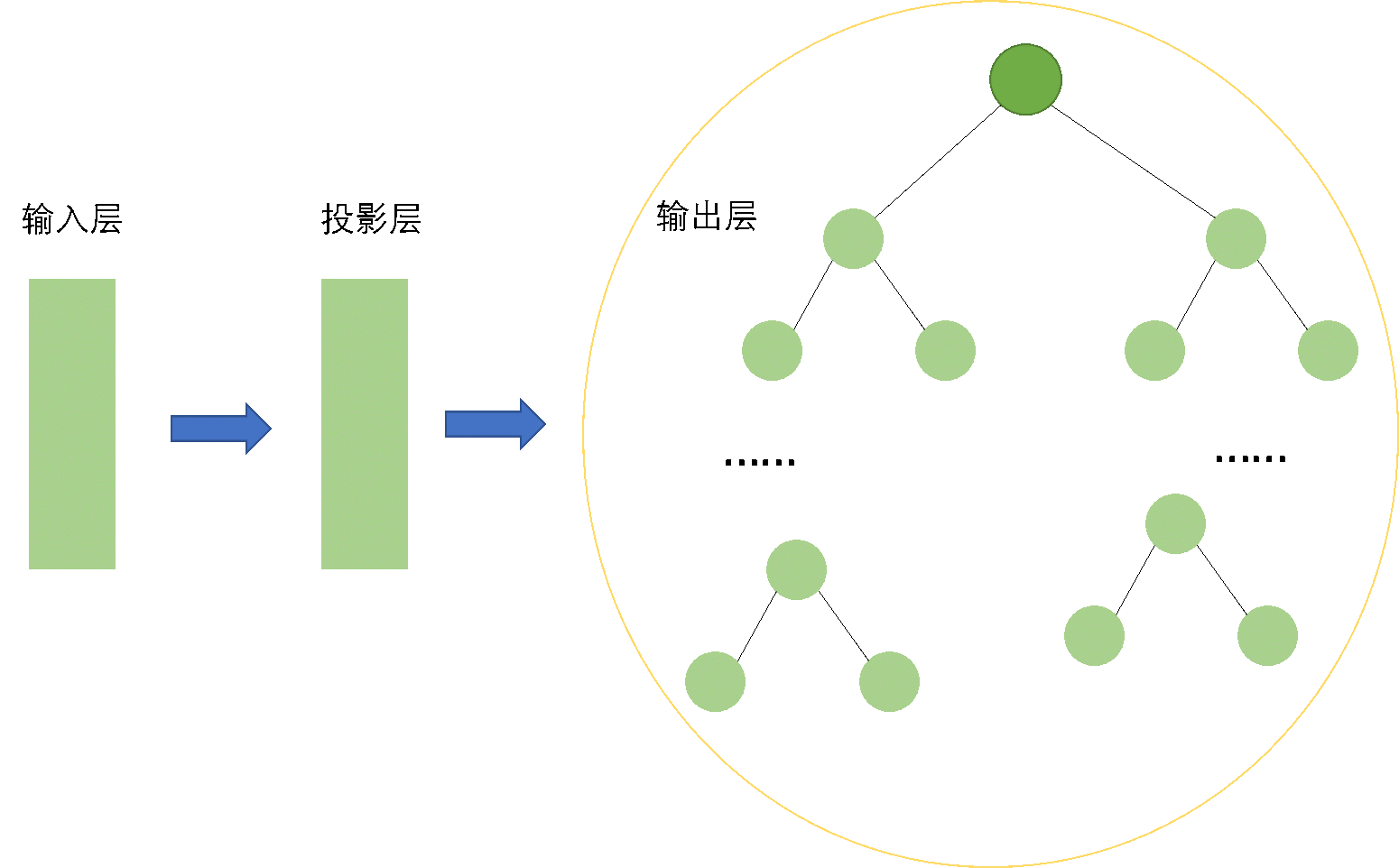
如上圖所示,與basic版本的skip-gram模型相比,hierarchical softmax版本的模型輸出層不再是線性結構,而是樹形結構。
上面已經說過,線性結構的skip-gram模型的參數規模十分龐大,最大能夠達到\(10^7\)數量級,再加上動輒10億級別的語料庫,訓練代價很高,效率就特別低了。
引入了hierarchical softmax以後,輸出層的維度得到了大幅降低。正如作者所說,計算\(logp(w_o\vert w_i)\)和\(\nabla logp(w_o\vert w_i)\)的代價是與\(L(w_o)\)也就是哈夫曼樹的深度成正比的。
下面假裝正經地推導參數的更新過程:
假設我們的訓練樣本是【今天我上課遲到了,然後被老師批評了】,對應詞匯表中的詞匯為【今天 我 上課 遲到 了 然後 被 老師 批評】
假設在語料庫中,上述詞匯對應的頻數如下表所示:
| 詞匯 | 頻率 |
|---|---|
| 今天 | 8 |
| 我 | 15 |
| 上課 | 2 |
| 遲到 | 1 |
| 了 | 20 |
| 然後 | 10 |
| 被 | 5 |
| 老師 | 3 |
| 批評 | 2 |
將頻率看做是哈夫曼樹的權值,將大的權值放在左子樹,小的權值放在右子樹。
繪制出的帶權值的哈夫曼樹如下:
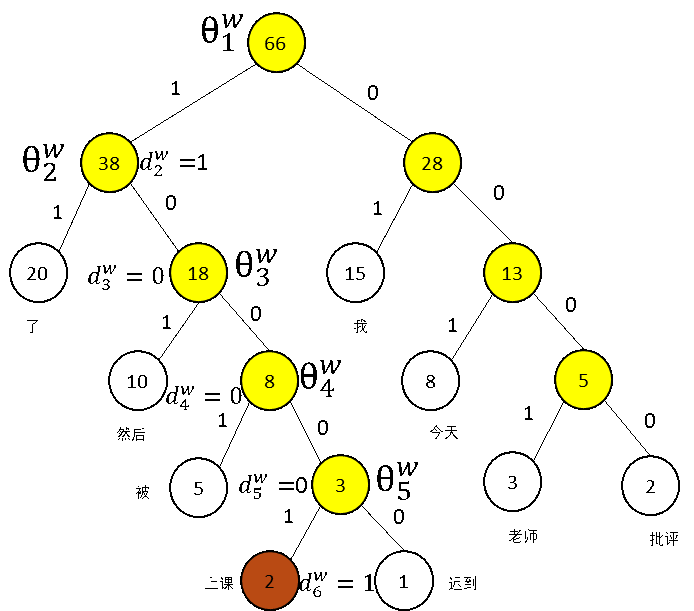
說明如下:
黃色的結點表示新生成的樹
\(\theta_i^w \in R^m\),非葉子結點對應的向量
\(d_1^w,d_2^w,\cdots,d_{l(w)-1}^w \in \{0,1\}\):詞\(w\)的哈夫曼編碼,由\(l(w)-1\)位編碼構成,\(d_j^w\)對應對應路徑中第\(j\)個非葉子結點的編碼(0 or 1).
根據基於hierarchical softmax的skip-gram模型,投影層將輸入的one-hot向量投影成\(R^m\)空間中的向量,即輸出層接受的輸入為投影層的輸出,即\(v_m\)。
目標函數仍然是最大化對數似然概率,那麽,當前的重點是條件概率函數的構造。
skip-gram模型將其定義為
\[P(context(w_i)\vert w_i)=\prod _{u\in context(w_i)}p(u\vert w_i)\]
而根據hierarchical softmax的思想,\(p(u\vert w_i)\)可以寫出如下形式:
\[p(u\vert w_i)=\prod _{j=2}^{l(w)}p(d_j^u\vert v_m;\theta_{j-1}^u)\]
其中
\[p(d_j^u\vert v_m;\theta_{j-1}^u)=[\sigma(v_m^T\theta^u_{j-1})]^{1-d_j^u}\cdot[1-\sigma(v_m^T\theta^u_{j-1})]^{d_j^u}\]
那麽,我們的目標函數可以寫成如下形式:
\[L=\sum _{w\in C} log \prod _{u\in context(w)}\prod _{j=2}^{l(w)}[\sigma(v_m^T\theta^u_{j-1})]^{1-d_j^u}\cdot[1-\sigma(v_m^T\theta^u_{j-1})]^{d_j^u}\]
\[=\sum _{w\in C}\sum _{u \in context(w)}\sum _{j=2}^{l(w)}\{(1-d_j^u)\cdot log[\sigma(v_m^T\theta^u_{j-1})]+d_j^u\cdot log[1-\sigma(v_m^T\theta^u_{j-1})]\}\]
上面的函數就是skip-gram的目標函數,為了方便推導梯度,將三重求和符號下花括號的內容簡記為\(L(w,u,j)\),即
\[L(w,u,j)=(1-d_j^u)\cdot log[\sigma(v_m^T\theta^u_{j-1})]+d_j^u\cdot log[1-\sigma(v_m^T\theta^u_{j-1})]\]
首先考慮\(L\)關於\(\theta_{j-1}^u\)的梯度計算:
\[\frac{\partial L}{\partial \theta_{j-1}^u}=\frac{\partial L(w,u,j)}{\partial \theta_{j-1}^u}=\frac{\partial \{(1-d_j^u)\cdot log[\sigma(v_m^T\theta^u_{j-1})]+d_j^u\cdot log[1-\sigma(v_m^T\theta^u_{j-1})]\}} {\partial \theta_{j-1}^u}=[1-d_j^u-\sigma(v_m^T\theta_{j-1}^u)]\cdot v_m\]
於是,\(\theta_{j-1}^u\)的更新公式可寫為:
\[\theta_{j-1}^u\leftarrow \theta_{j-1}^u+\epsilon [1-d_j^u-\sigma(v_m^T\theta_{j-1}^u)]\cdot v_m\]
接下來考慮\(L\)對\(v_m\)的梯度。由於在\(L\)中,\(v_m\)與\(\theta_{j-1}^u\)具有對稱性,因此可以根據上述所求,直接寫出\(v_m\)的更新公式:
\[v_m\leftarrow v_m+\epsilon \sum _{u\in C}\sum _{j=2}^{l(w)}\frac{\partial L(w,u,j)}{\partial v_m}\]
其中,\(\epsilon\)是學習率。
Negative Sampling and Subsampling of Frequent Words
考慮到basic版本的skip-gram模型擁有兩個異常巨大的權重矩陣,再加上一個10億數量級的語料庫,神經網絡跑起來會非常吃力。
word2vec的作者是這樣處理這個問題的,主要有以下三個創新點:
將常用詞對或者詞組看成一個單獨的詞
subsampling(降采樣)出現頻率很高的詞以減小訓練樣本的大小
使用一種被稱為"Negative Sampling"的方法來改變優化目標,這種方法在訓練時只優化與訓練樣本有關的很小一丟丟權重。
值的一提的是,應用Subsampling和NEG方法不僅可以減小計算壓力,還能提高最終產生的詞向量的質量。
Negative Sampling
回想一下那個basic版本的skip-gram,神經網絡的真實值或者說標簽是一個one-hot矩陣,也就是說,只有一個分量是1,而其他分量都是0(成千上萬個0)。但是我們在更新神經網絡權重的時候,對於所有的輸出為0的權重都進行了更新,這樣效率是比較差的。
negative sampling的思想就是,當我們在訓練一個特定樣本的時候,能不能只更新幾個輸出為0的權重,這樣計算起來就比較輕松了。
我們把one-hot向量分量為負的位置所對應的詞稱為negative words,在訓練一次樣本時,我們只更新幾個(假如說5個吧)negative words,同時也更新我們的pisitive words(即分量為1所對應的位置在詞匯表中對應的詞)。
作者在論文中說到,當樣本量比較小的時候,選擇5-20個negative words效果會比較好,當樣本量比較大的時候,2-5個negative words就能得到很好的效果。
現在假設我們在basic model中需要更新的權重矩陣為\(300\times 10000\)矩陣,那麽basic model每次叠代需要更新\(3\times 10^6\)個參數,而采用了negative sampling 方法以後,我們只需要更新5個negative words和1個positive words對應的權重,也就是\(300\times (5+1)=1800\)個權重,是原來的\(1800/3\times 10^6=0.06\%\).
想法是好的,我們要怎麽選擇這5個negative words呢?
我們知道,語料庫中的每個詞都有一定的頻率,那麽我們就利用頻率這個信息,對negative words進行采樣。
由此可見,高頻詞被選為negative words的概率就比較大,同理,低頻詞被選為negative words的概率就比較小。
作者的處理方法是,賦予每一個詞被選為negative words的概率,具體計算公式如下:
\[P(w_i)=\frac{f(w_i)^{0.75}}{\sum _{j=0}^nf(w_i)^{0.75}}\],
至於為什麽是0.75,這是作者及其團隊經過不斷試驗得出的效果比較好的,沒有特別的原因。
計算出了概率,我們又怎麽選擇相應的negative words呢?
作者在其代碼中給出了答案。
下面給出了具體的方法:
構造一個很長的數組,作者的數組長度達到了1000000
將詞匯表中的每個詞對應的index(索引)向數組中填充多次,填充的次數是這樣計算的:
根據一元模型可以從語料庫生成樣本(也就是把語料庫中的文本以詞的形式展示)
填充次數times的計算公式為:
\[times = P(w_i)\times 100000\]
- 欲選出你的negative words,只需要在0-100M之間隨機生成一個整數,以這個整數為索引,在數組中查找元素,該元素也是一個索引,根據這個元素從詞匯表中查找negative words。
不難理解,\(P(w_i)\)大的被選中的概率就大。
Subsampling of Frequent Words
讓我們再看一遍詞對的生成過程。
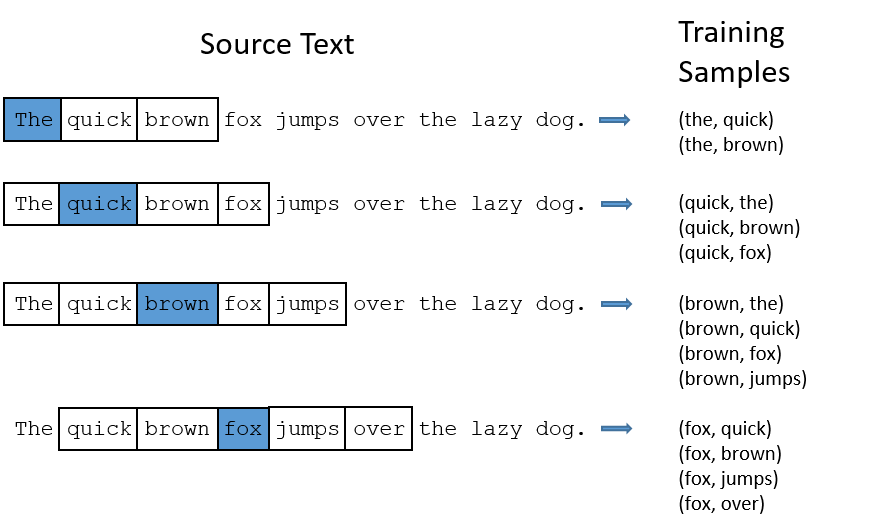
如上圖所示,我們設定window size = 2 來生成樣本。對於包含"the"的詞對來說,有以下兩個問題:
當我們在尋找詞對的時候,("fox","the")所能提供的信息並不比"fox"多。然而,"the"幾乎在上面的所有詞對中都有出現。
形如("the",...)這樣的詞對已經遠遠超過了我們的需求。
word2vec 應用了一種稱之為subsampling的方法來解決這個問題。
對於我們遇到每一個語料庫中的詞,都有一定的概率將它從語料庫中刪除,刪除的概率與該詞出現的頻率有關。
如果我們將window size 設置為10,我們是這樣刪除"the"相關樣本的:
我們在訓練其他詞的時候,"the"不會出現在他們的窗口
當輸入詞是"the"的時候,將樣本數減少10個(不減少的情況下是20)
那麽,我們怎麽決定是否刪除一個詞呢?
假設\(w_i\)是待定刪除的詞,\(z(w_i)\)是\(w_i\)在語料庫中出現的頻率,\(P(w_i)\)是保留該詞的概率:
\[P(w_i)=(\sqrt{\frac{z(w_i)}{0.001}}+1)\cdot \frac{0.001}{z(w_i)}\]
0.001也是一個經驗參數,如果比0.001還要小,那麽保留詞的概率就會更小。
下面是\(P(w_i)\)函數的圖像:
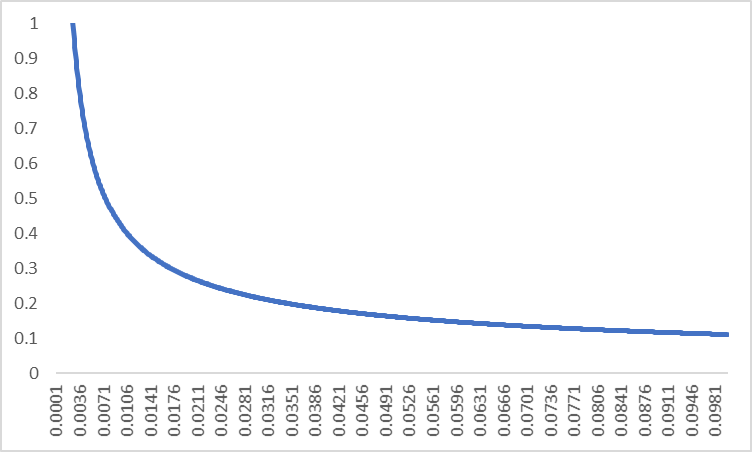
從圖像可以看出:
當頻率等於0.0026的時候,被保留的概率為1,也就是說,當頻率大於0.0026的時候,就有可能被刪除。
當頻率為0.0074的時候,有一半的概率會被保留
當頻率為0.1的時候,被保留的概率就驟減到0.1
Learning Phrase
learning phrase 方法使得樣本更加接近真實世界。考慮以下句子:
New York is a beautiful and modern city where I want to have a travel.我們設置窗口大小為4,對beautiful進行采樣,獲得如下樣本:
(beautiful,New) (beautiful,York) (beautiful,is) (beautiful,a) (beautiful,New) (beautiful,and) (beautiful,modern) (beautiful,city) 采用一元的方法,會將常用的詞組分開,從而降低詞向量的質量。
我們可以采取一個簡單的數據驅動的方法,來對兩個詞是否能組成詞組進行打分:
\[score(w_i,w_j) = \frac{count(w_iw_j)-\delta}{count(w_i)\times count(w_j)}\]
\(\delta\)作為一個折扣系數的作用,用來防止那些不怎麽經常一起出現的詞語形成詞組。當score超過了我們設置的閾值時,將兩個詞視為詞組。
上述打分程序可以多進行幾次,以獲得三元組或者更多詞的詞組。
參考文獻
[1]McCormick, C. (2016, April 19). Word2Vec Tutorial - The Skip-Gram Model. Retrieved from http://www.mccormickml.com
[2]Pennington J, Socher R, Manning C. Glove: Global Vectors for Word Representation[C]// Conference on Empirical Methods in Natural Language Processing. 2014:1532-1543.
[3]Mikolov T, Le Q V, Sutskever I. Exploiting Similarities among Languages for Machine Translation[J]. Computer Science, 2013.
[4]Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
[5]Bengio, Y & Ducharme, Réjean & Vincent, Pascal. (2000). A Neural Probabilistic Language Model. Journal of Machine Learning Research. 3. 932-938. 10.1162/153244303322533223.
[6]NSS,(JUNE 4, 2017).An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec.Retrieved from https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/
[7]peghoty,2014年07月.word2vec 中的數學原理詳解.http://blog.csdn.net/itplus/article/details/37969519
[8]吳軍.數學之美[M].北京:人民郵電出版社,2014.
==========================The End=============================
Word2Vec-語言模型的前世今生