
2017-2018-1 20155331 《信息安全系統設計基礎》第13周學習總結
2017-2018-1 20155331 《信息安全系統設計基礎》第13周學習總結
學習目標
找出全書你認為最重要的一章,深入重新學習一下。
第六章教材學習內容重溫總結
存儲技術
隨機訪問存儲器
隨機訪問存儲器分為:靜態RAM(SRAM)和動態RAM(DRAM),靜態RAM(SRAM)比動態RAM(DRAM)更快,但也貴很多。
靜態RAM:
SRAM將每個位存儲在一個雙穩態的存儲器單元裏,每個單元是用一個六晶體管電路來實現的。
SRAM的特點:存儲器單元具有雙穩態特性,只要有電就會永遠保持它的值,幹擾消除時,電路就會恢復到穩定值。
動態RAM:
DRAM的特點:每一位的存儲是對一個電容的充電,電容約為30×10-15F;對幹擾非常敏感,當電容的電壓被擾亂之後,它就永遠不會恢復了。暴露在光線下會導致電容電壓改變。
用途:數碼照相機和攝像機的傳感器
DRAM存儲不穩定的應對機制:存儲器系統必須周期性地通過讀出,或者重寫來刷新存儲器的每一位;使用糾錯碼。
SRAM和DRAM的區別:
只要有電,SRAM就會保持不變,而DRAM需要不斷刷新;
SRAM比DRAM快;
SRAM對光和電噪聲等幹擾不敏感;
SRAM比DRAM需要使用更多的晶體管,所以更昂貴。
傳統的DRAM:
行地址i:RAS
列地址j:CAS DRAM組織成二位陣列而不是線性數組的一個原因是降低芯片上地址引腳的數量。
二維陣列組織的缺點是必須分兩步發送地址,這增加了訪問時間。
存儲器模塊分類:
168個引腳的雙列直插存儲器模塊,以64位為塊傳送數據;
72個引腳的單列直插存儲器模塊,以32位為塊傳送數據。
增強的DRAM:
快頁模式DRAM(FPM DRAM):異步控制信號,允許對同一行連續的訪問可以直接從行緩沖區得到服務。
擴展數據輸出DRAM(EDO DRAM):異步控制信號,允許單獨的CAS信號在時間上靠的更緊密一點
同步DRAM(SDRAM):同步的控制信號,比異步的快
雙倍數據速率同步DRAM(DDR SDRAM):使用兩個時鐘沿作為控制信號,使DRAM速度翻倍。
Rambus DRAM(RDRAM):一種私有技術
視頻RAM(VRAM):用在圖形系統的幀緩沖區中。
非易失性存儲器:ROM是以它們能被重編程的次數和對它們進行重編程所用的機制區分的
可編程ROM(PROM):只能被編程一次
可擦寫可編程ROM(EPROM):使用紫外線實現
電子可擦除PROM(EEROM):使用印制電路卡實現
閃存(FM):非易失性存儲設備
訪問主存:
讀事務:從主存傳送數據到CPU。
寫事務:從CPU傳送數據到主存。
總線:一組並行的導線,能攜帶地址、數據的控制信號。
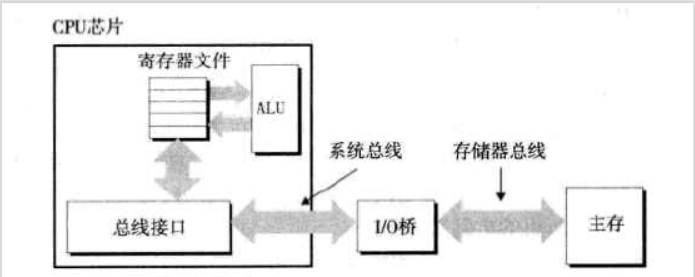
- 讀事務語句:``movl A,%eax``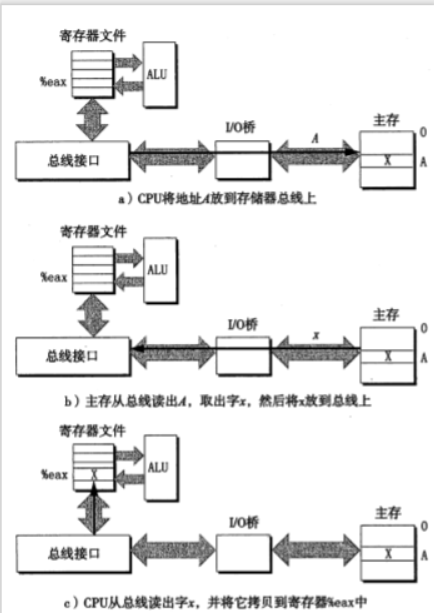
- 寫事務語句:``movl %eax,A``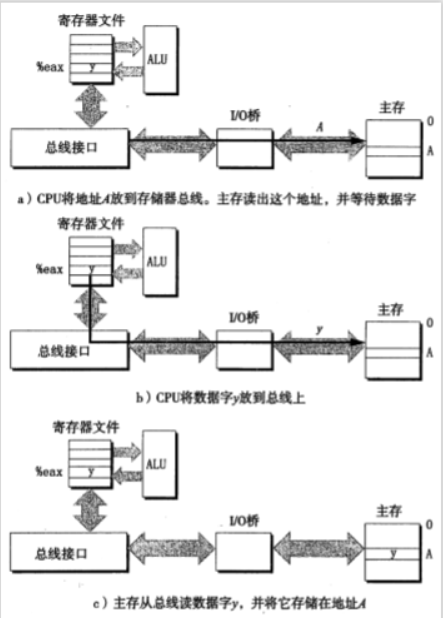
磁盤存儲
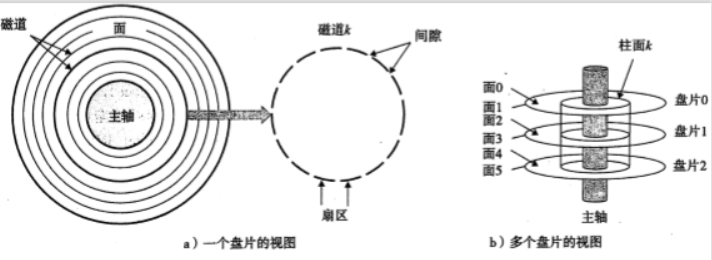
磁盤構造:
由盤片構成,每個盤片有兩面或者稱為表面,表面覆蓋著磁性記錄材料。盤片中央有一個可以旋轉的主軸,使得盤片以固定的旋轉速率旋轉,通常是5400~15000轉每分鐘(RPM)
每個表面是由一組稱為磁道的同心圓組成;每個磁道被劃分成一組扇區;每個扇區包含相等數量的數據位(通常是512字節);這些數據編碼在扇區上的磁性材料中。扇區之間由一些間隙分隔開,這些間隙中不存在數據位。間隙存儲用來標識扇區的格式化位。
磁盤容量:
一個磁盤上可以記錄的最大位數稱為它的最大容量/容量。
磁盤容量的決定因素:記錄密度:磁道一英寸的段可以放入的位數;磁道密度:從盤片中心出發半徑上一英寸的段
內可以有的磁道數;面密度:記錄密度與磁道密度的乘積。
計算磁盤容量的公式:磁盤容量 = 字節數/扇區 X 平均磁盤數/磁道 X 磁道數/表面 X 表面數/盤片 X 盤片數/磁盤
磁盤操作:
磁盤用讀寫頭來讀寫存儲在磁性表面的位,而讀寫頭連接到一個轉動臂一端。尋道就是通過沿著半徑軸前後移動這個轉動臂,使得驅動器可以將讀寫頭定位在盤面上的任何磁道上。
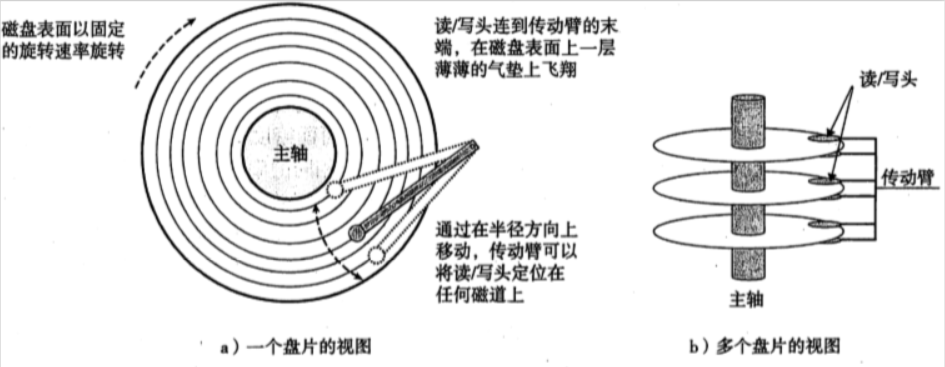
磁盤以扇區大小的塊來讀寫數據。
訪問時間=尋道時間+旋轉時間+傳送時間;
尋道時間:移動傳送臂所需要的時間
旋轉時間:一旦讀寫頭定位你到了期望的磁道,驅動器等待目標扇區的第一個位旋轉到讀寫頭下。 該性能依賴於當
讀寫頭到達目標磁道時盤面的位置和磁盤的旋轉速度。最大旋轉延遲=1/RPM X 60secs/1min (s),平均旋轉時間是最大旋轉時間的一半
傳送時間:一個扇區的傳送時間依賴於旋轉速度和每條磁道的扇區數目。平均傳送時間=1/RPM x 1/(平均扇區數/磁道) x 60s/1min,一個磁盤扇區內容的平均時間為平均尋道時間、平均旋轉延遲和平均傳送時間之和。
邏輯磁盤塊:
磁盤控制器:磁盤中一個小的硬件、固件設備,維護著邏輯塊號和實際物理磁盤扇區之間的映射關系。
三元組(盤面,磁道,扇區):唯一地表示了對應的物理扇區。
連接到I/O設備:
外圍設備互連(PCI):連接到CPU和主存 I/O總線的分類
通用串行總線(USB):包括鍵盤、鼠標、調制解調器、數碼相機、遊戲操縱桿、打印機、外部磁盤驅動器和固態硬盤等
圖形卡(適配器):負責代表CPU在顯示器上畫像素
主機總線適配器:使用特別的主機總線接口定義的通信協議
訪問磁盤:
CPU使用一種存儲器映射I/O技術來向I/O設備發出命令,在使用存儲器映射I/O的系統中,地址空間中有一塊地址是
為與I/O設備通信保留的,稱為I/O端口。當一個設備連接到總線時,它與一個或多個端口相連。
直接存儲器訪問:設備可以自己執行讀或者寫總線事務,而不需要
基本思想:中斷會發信號到CPU芯片的一個外部引腳上。這會導致CPU暫停它當前正在做的工作,跳轉到一個操作系統例程。這個程序會記錄下I/O已經完成,然後將控制返回到CPU被中斷的地方。
固態磁盤
固態硬盤是一種基於閃存的存儲技術。
一個SSD包由一個或多個閃存芯片和閃存翻譯層組成,閃存芯片替代傳統旋轉磁盤中機械驅動器;閃存翻譯層(一個硬件/固件設備)替代磁盤控制器,將對邏輯塊的請求翻譯成對底層物理設備的訪問。
性能特性:順序讀和寫(CPU按順序訪問邏輯磁盤塊)性能相當,順序讀比順序寫稍快一點;隨機順序訪問邏輯塊時,寫比讀慢一個數量級;讀寫性能差別是由底層閃存基本屬性決定的。
優點:由半導體構成,沒有移動的部件;隨機訪問時間比旋轉磁盤要快、能耗低、結實。
缺點:易磨損、更貴
存儲技術趨勢
不同的存儲技術有不同的價格和性能折中
不同存儲技術的價格和性能屬性以截然不同的速率變化著(增加密度從而降低成本比降低訪問時間更容易)
DRAM和磁盤的性能滯後於CPU的性能
局部性
局部性:傾向於引用鄰近與其他最近引用過的數據項的數據項,或者最近引用過的數據項本身,這種傾向性,被稱為局部性原理。
局部性包括時間局部性和空間局部性
時間局部性:被引用過一次的存儲器位置很可能在不遠的將來再被多次引用。
空間局部性:一個存儲器位置被引用了一次,那麽程序很可能在不遠的將來引用附近的一個存儲器位置。
有良好局部性的程序比局部性差的程序運行得更快
硬件層:局部性原理允許計算機設計者通過引入高速緩存存儲器來保存最近被引用的指令和數據項,從而提高對主存的訪問速度。
操作系統級:局部性原理允許系統使用主存作為虛擬地址空間最近被引用塊的高速緩存,用主存來緩存磁盤文件系統中最近被使用的磁盤塊。
應用程序中:例如,Web瀏覽器將最近被引用的文檔放在本地磁盤上。
對程序數據引用的局部性
步長為k的引用模式:一個連續變量中,每隔k個元素進行訪問。
順序引用模式:具有步長為1的引用模式
一般來說,隨著步長增加,空間局部性下降。
取指令的局部性
程序指令是存放在存儲器中的,CPU必須取出(讀出)這些指令。
代碼區別於程序數據的一個重要屬性是在運行時它是不能被修改的。當程序正在執行時,CPU只從存儲器中讀出它的指令,CPU絕不會重寫或修改這些指令。
存儲器層次結構
存儲技術:不同的存儲技術的訪問時間差異很大,速度較快的技術每字節的成本要比速度較慢的技術高,而且容量較小,CPU和主存之間的速度差距在增大。
計算機軟件:一個編寫良好的程序傾向於展示出良好的局部性。
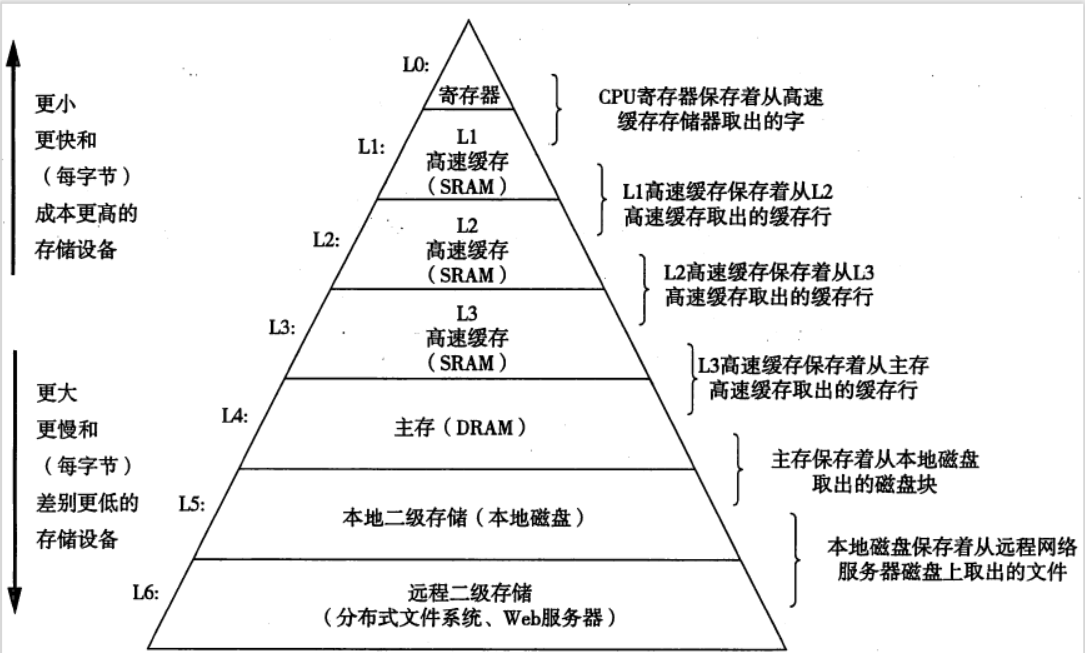
存儲器層次結構中的緩存
高速緩存:是一個小而快速地存儲設備,它作為存儲在更大、也更慢的設備中的數據對象的緩沖區域。
緩存:使用高速緩存的過程。
塊:第k+1層的存儲器被劃分成連續的對象片。每個塊有一個唯一的地址或名字,使之區別於其他的塊。
傳送單元:數據總是以塊大小為傳送單元。
緩存命中:
當程序需要第k+1層的某個數據對象d時,首先在當前存儲在第k層的一個塊中查找d,如果d剛好緩存在第k層中,就
稱為緩存命中。
該程序直接從第k層讀取d,比從第k+1層中讀取d更快。
緩存不命中:第k層中沒有緩存數據對象d
這時第k層緩存會從第k+1層緩存中取出包含d的那個塊。如果第k層緩存已滿,就可能會覆蓋現存的一個塊;覆蓋一個現存的塊的過程稱為替換/驅逐這個塊;被驅逐的塊有時也稱為犧牲塊。
替換策略:決定替換哪個塊;隨機替換策略:隨機選擇一個犧牲塊;最近最少被使用替換策略(LRU):選擇最後被訪問的時間距現在最遠的塊。
緩存不命中的種類:
強制性不命中/冷不命中:即第k層的緩存是空的(稱為冷緩存),對任何數據對象的訪問都不會命中。通常是短暫事件,不會在反復訪問存儲器使得緩存暖身之後的穩定狀態中出現。
沖突不命中:由於一個放置策略:將第k+1層的某個塊限制放置在第k層塊的一個小的子集中,這就會導致緩存沒有滿,但是那個對應的塊滿了,就會不命中。
容量不命中:當工作集的大小超過緩存的大小時,緩存會經歷容量不命中,就是說緩存太小了,不能處理這個工作集。
緩存管理:某種形式的邏輯必須管理緩存,而管理緩存的邏輯可以是硬件、軟件,或者兩者的集合。
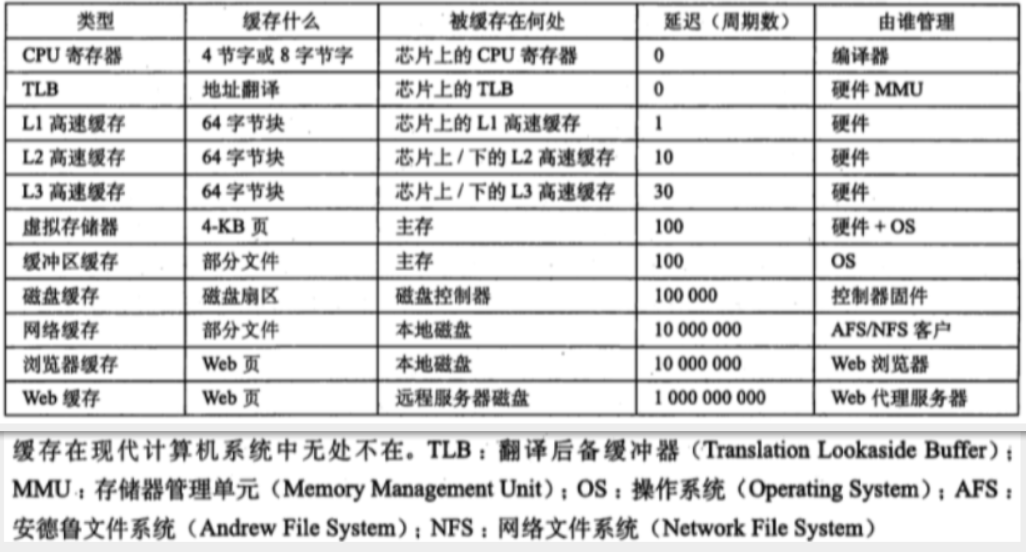
高速緩存存儲器
存儲器層次結構只有三層:CPU寄存器、DRAM主存儲器和磁盤存儲。
通用的高速緩存存儲器結構
每個存儲器地址有m位,形成M=2^m個不同的地址。
高速緩存組:S = 2^m個高速緩存組的數組
高速緩存行:B = 2^m字節的數據塊組成
有效位:指明這個行是否包含有意義的信息
標記位:唯一地標識存儲在這個高速緩存行中的塊,t = m -(b+s)
直接映射高速緩存
直接映射高速緩存:每個組只有一行的高速緩存。
高速緩存確定一個請求是否命中,然後抽取出被請求的字的過程,分為三步:(1)組選擇(2)行匹配(3)字抽取
組選擇:
高速緩存從w的地址中間抽取出s個組索引位
組索引位:一個對應於一個組號的無符號整數。
行匹配:
判斷緩存命中的兩個充分必要條件:該行設置了有效位;高速緩存行中的標記和w的地址中的標記相匹配
字選擇:確定所需要的字在塊中是從哪裏開始的。
組相聯高速緩存
組選擇:與直接映射高速緩存中的組選擇一樣,組索引位標識組。
行匹配和字選擇:
把每個組看做一個小的相關聯存儲器,是一個(key,value)對的數組,以key為輸入,返回對應數組中的value值。高速緩存必須搜索組中的每一行,尋找有效 的行其標記與地址中的相匹配。
形式是(key, value),用key作為標記和有效位去匹配,匹配上了之後返回value。
組中的任意一行都可以包含任何映射到這個組的存儲器塊,所以告訴緩存必須搜索組中的每一行。
組相連高速緩存中不命中時的行替換:
隨機替換
最不常使用策略LFU:替換在過去某個時間窗口內引用次數最少的那一行。
最近最少使用策略LRU:替換最後一次訪問時間最久遠的那一行。
全組相連高速緩存:
組選擇:只有一個組,沒有組索引位。
行匹配和字選擇:與組相連高速緩存是一樣的,但規模大很多,因此只適合做小的高速緩存,例如虛擬存儲系統中的翻譯備用緩沖器。
寫命中時,更新低一層中的拷貝的方法
直寫:立即將w的高速緩存塊協會到緊接著的低一層中;缺點:每次寫都會引起總線流量。
寫回:只有當替換算法要驅逐更新過的塊時,才寫到緊接著的低一層中。優點:符合局部性原理,顯著的減少總線流量;缺點:增加了復雜性,必須為每個高速緩存行維護一個額外的修改位
寫不命中的處理方法:
寫分配(對應寫回):加載相應的低一層中的塊到高速緩存中,然後更新這個高速緩存塊。
非寫分配(對應直寫):避開高速緩存,直接把這個字寫在低一層中
課後習題部分
習題6.2
計算這樣一個磁盤的容量。它有2個盤片,10 000個柱面,每條磁道平均有400個扇區,每個扇區平均有512個字節。
根據磁盤容量公式
可得:磁盤容量 = 512(字節)400(扇區)10000(磁道數)2(表面)2(盤片面數)= 8 192 000 000 字節 = 8.192GB
習題6.3
估計訪問下面的一個磁盤上的一個扇區需要的時間(以ms為單位)。旋轉速率:15000RPM;Taveseek = 8ms;每條磁道的平均扇區數:500
訪問時間 = Taveseek+Taverotation+Tavetransfer=8ms+0.51/15000RPM60secs.min1000ms/s+1/15000RPM1/50060secs/min1000ms/s=8ms+2ms+0.008ms=10.008ms
習題6.4
假設1MB的文件由512字節的邏輯塊組成,存儲在有如下特性的磁盤驅動器上(旋轉速率:10000RPM,
Taveseek=5ms,平均扇區/磁道 = 1000)。
(1)最好的情況:給定邏輯塊到磁盤扇區的最好的可能的映射(即,順序的),估計讀這個文件需要的最優時間
(2)隨機的情況:如果塊是隨機地映射到磁盤扇區的,估計讀這個文件需要的時間
首先明確:1MB=2^20字節,即數據存儲在2000個邏輯塊中;對於磁盤,
Taverotation=0.51/10000RPM60secs/1min1000ms/s=3ms則:
(1)T=Taveseek+Taverotation+2Tmaxrotation=5ms+3ms+26ms=20ms
(2)在這種情況下,塊被隨機的映射到扇區上,讀2000塊的每一塊都需要Taveseek+Tavgrotation=8ms。所以讀這個文件的總時間為T = 8ms2000=16000ms=16s
習題6.7
改變下面函數中的循環順序,使得它以步長為1的引用模式掃描三維數組a
int sumarray3d(int a[N][N][N])
{
int i,j,k,sum=0;
for(i=0;i<N;i++)
{
for(j =0;j<N;j++)
{
for(k=0;k<N;k++)
{
sum+=a[k][i][j];
}
}
}
return sum;
}只需要對三層嵌套循環體的順序進行調整即可:
int sumarray3d(int a[N][N][N])
{
int i,j,k,sum=0;
for(i=0;k<N;i++)
{
for(j =0;i<N;j++)
{
for(k=0;j<N;k++)
{
sum+=a[k][i][j];
}
}
}
return sum;
}習題6.10
在前面dotprod的例子中,在我們對數組x做了填充之後,所有對x和y的引用的命中率是多少?
在填充了之後,對於x和y數組,只有在引用第0個和第4個元素的時候發生不命中。因而命中率為75%
習題6.11
一般而言,如果一個地址的高s位被用作組索引,那麽存儲塊連續的片會映射到同一個高速緩存組。
A.每個這樣連續的數組有片多少個塊?
B.考慮下面的代碼;它運行在一個高速緩存形式為(S,E,B,m)=(512,1,32,32)的系統上
int array[4096]
for(i=0;i<4096;i++)
sum+=array[i];在任意時刻,存儲在高速緩存中的數組塊的最大數量是多少?
A.用高位做索引,每個連續的數組片(chunk)由2^t個塊組成,這裏t是標記位數,因此,數組頭2^t個連續的塊都會映射到組0,接下來的2^t個塊會映射到組1,以此類推。
B.對於直接映射高速緩存(S.E.B.m)=(512,1,32,32),高速緩存容量是512個32子節的塊,每個高速緩存行中有t=18個標記位。因此,數組中頭2^18個塊會映射到組0,接下來2^18個塊會映射到組1.因為我們的數組只由(4095*4)/32=512個塊組成,所以數組中所有的塊都被映射到組0.因此,在任何時刻,高速緩存之多只能保存一個數組塊,即時數組足夠小,能夠完全放到高速緩存中。很明顯,用高位做索引不能充分利用高速緩存。
2017-2018-1 20155331 《信息安全系統設計基礎》第13周學習總結