
2017-2018-1 20155201 《信息安全系統設計基礎》第十四周學習總結
2017-2018-1 20155201 《信息安全系統設計基礎》第十四周學習總結
教材學習內容總結
輸入/輸出(I/O)是在主存和外部設備(例如磁盤驅動器、終端和網絡)之間復制數據的過程。輸入操作是從I/O設備復制數據到主存,輸出操作是從主存復制數據到I/O設備。
在Unix系統中,通過使用由內核提供的系統級UnixI/O函數來實現較高級別的I/O函數。但是Unix I/O的學習也必不可少,Unix I/O是系統操作不可或缺的部分,我們需要通過學習理解其他的系統概念,而且很多時候,使用高級I/O函數不太合適,還是需要使用Unix I/O。而且這一章是網絡編程和並發性的前提和基礎,所以我決定重新學習一下。
10.1 Unix I/O
具體Unix I/O是什麽呢?
一個Linux文件就是一個m個字節的序列,所有I/O設備(例如網絡、磁盤和終端)都被模型化為文件,所有輸入和輸出都被當作對相應文件的讀和寫來執行。這種將設備優雅的映射為文件的方式,允許Linux內核引出一個簡單、低級的應用接口,簡稱Unix I/O,這使得所有的輸入和輸出都能以一種統一且一致的方式來執行:
先了解一個概念,叫做描述符:描述符是內核返回的、一個較小的非負整數,它記錄著有關這個文件的信息,應用程序無需記住這個文件在哪裏、什麽格式、多大,只需要記住這個描述符,就可以對這個文件進行相應的操作。
打開文件。一個應用程序通過要求內核打開相應的文件,來告訴它想要訪問的
I/O設備。內核返回一個小的非負整數,叫做描述符,它在後續對此文間的所有操作中標識這個文件。內核記錄有關這個打開文件的所有信息。應用程序只需要記住這個描述符。- Linux shell 創建的每個進程開始時都由三個打開的文件:標準輸入(描述符為0)、標準輸出(描述符為1)和標準錯誤(描述符為2)。
改變當前的文件位置。對於每個打開文件,內核保持著一個文件位置k,初始為0。即從文件開頭起始的字節編偏移量。
- 讀寫文件。
- 一個讀操作就是從文件復制
n>0個字節到內存,從當前文件位置k開始,然後將k增加到k+n。當超過文件字節大小時,讀操作會出發一個end-of-file的條件,應用程序能檢測到這個條件。 - 同理,寫操作就時從內存復制n個字節到一個文件中。
- 一個讀操作就是從文件復制
關閉文件。當應用完成對文件的訪問之後,它就通知內核關閉文件。作為響應,內核釋放文件打開時創建的數據結構,並將這個描述父回復到可用的描述符池中。無論一個進程因為何種原因終止時,內核都會關閉所有打開的文件並釋放他們的內存資源。
10.2 打開和關閉文件
進程通過open函數來打開一個已存在的文件或者創建一個新文件的:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *filename, int flags, mode_t mode); //返回值:若成功則為文件描述符,出錯為-1。
- 該函數將
filename轉換為一個文件描述符,並且返回描述符數字。 flags指明如何訪問這個文件:O_RDONLY(只讀),O_WRONLY(只寫),O_RDWR(讀寫)flags還有為寫操作提供一些額外指示的掩碼,在使用時把他們或起來就好。O_CREAT:如果文件不存在,那就創建它的一個截斷的空文件。O_TRUNC如果文件已存在,就截斷它。O_APPEND在每次寫操作前,設置文件位置到文件的結尾處。(學習Java的時候,append就可以向String後面添加String)
- 而
mode制定了新文件的訪問權限位,在sys/stat.h頭文件中定義,我們可以使用#define來將多種權限復合在一起,省略重復寫這麽多字母。 
先復習下之前講用戶對文件的權限:
權限分三種:(r)可讀、(w)可寫、(x)可執行
對用戶的限制分三種:User(當前用戶)、Groups(用戶所在組的成員)、Every one(所有人)巧妙使用#define
#define MY_MODE S_IRUSR|SIWUSR|S_IXUSR
#define GROUP_MODE S_IRGRP|S_IWGRP|S_IXGRP當我們打開一個存在的文件,mode_t mode定義為0即可。
int fd=open("foo.txt",O_WRONLY,0);想要在一個已存在文件後面添加一些數據:
int fd=open("foo.txt",O_WRONLY|O_APPEND,0);想要創建一個新文件:
int fd=open("foo.txt",O_WRONLY|O_CREAT|O_TRUNC,MY_MODE);
//這行代碼代表,創建一個新文件(如果已存在,截斷它!)User有讀寫和可執行權限打開一個文件後,一定要記得關閉!
#include <unistd.h>
int close(int fd);10.3 讀和寫文件
應用程序都是通過調用read和write函數來執行輸入和輸出的。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t n);
//若成功則返回讀到的字節數,EOF則返回0,出錯為-1。read函數從描述符為fd的當前文件位置拷貝最多n個字節到buf。
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t n);write函數從buf拷貝最多n個字節到fd的當前文件位置。- 某些情況的時候,
read和write傳送的字節比應用程序要求的要少,這些“不足”並不代表錯誤。出現這種情況的原因有以下幾個:- 讀時遇到
EOF:假設該文件從要求位置開始只有20字節,而函數要求50字節的片進行讀取,這樣就會導致read的返回值為20,此後的read將通過返回不足值0來發出EOF信號。 - 從終端讀文本行。如果打開文件是與終端關聯(如鍵盤和顯示器),那麽每個
read函數將一次傳送一個文本行返回的不足值等於問本行的大小。 - 讀和寫網絡套接字。如果打開的文件對應網絡套接字,那麽內部緩沖約束和較長的網絡延遲會引起
read和write返回不足值。 - 對
Unix 管道(pipe)調用read和write時,也有可能出現不足值。
- 讀時遇到
除了EOF,在讀寫磁盤文件的時候,不會遇到不足值。
如果想創建可靠的(健壯的)諸如web服務器這樣的網路應用,就必須通過反復調用read和write處理不足值,直到所有字節都傳送完畢。
10.4 用RIO包健壯地讀寫
Robust I/O包(RIO 包)會自動處理不足值。在像網絡程序這樣容易出現不足值的引用中,RIO包提供了方便、健壯和高效的I/O。
學習RIO主要是因為,在開發網絡應用中使用了RIO包,並且通過學習後對Unix I/O會有更深入的了解。
RIO提供了兩類不同的函數:- 無緩沖的輸入輸出函數:直接在存儲器和文件之間傳送數據,沒有應用級緩沖。對將二進制數據讀寫到網絡和從網絡讀寫二進制數據尤其有用。
- 通過調用
rio_readn和rio_writen函數,應用程序可以在存儲器和文件之間直接傳送數據。
#include "csapp.h" ssize_t rio_readn(int fd, void *usrbuf, size_t n); ssize_t rio_writen(int fd, void *usrbuf, size_t n); //若成功返回傳送的字節數,若EOF則返回0,出錯返回-1。 - 通過調用
- 帶緩沖的輸入函數:這些函數允許你高效的從文件中讀取文本行和二進制數據。
- 一個文本行就是一個由換行符結尾的ASCII碼字符序列。
- 一個包裝函數(
rio_readlineb)從內部讀緩沖區拷貝一個文本行,當緩沖區變空,會自動調用read重新填滿緩沖區。
#include "csapp.h" void rio_readinitb(rio *rp, int fd); ssize_t rioreadlineb(rio_t *rp, void *usrbuf, size_t maxlen);- 每打開一個描述符都會調用一次
rio_readinitb函數,它將描述符fd和地址rp處的一個類型為rio_t的讀緩沖區聯系起來。
10.5 讀取文件元數據
文件的元數據是指文件的信息,通過調用stat和fstat函數實現。
#include <unistd.h>
#include <sys/stat.h>
int stat(const char *filename, struct stat *buf);
int fstat(int fd, struct stat *buf);
//若成功返回值為0,出錯返回-1。調用stat函數會把參數中提到的文件填寫到stat數據結構中。
stat數據結構:
struct stat {
mode_t st_mode; //文件對應的模式,文件,目錄等
ino_t st_ino; //inode節點號
dev_t st_dev; //設備號碼
dev_t st_rdev; //特殊設備號碼
nlink_t st_nlink; //文件的連接數
uid_t st_uid; //文件所有者
gid_t st_gid; //文件所有者對應的組
off_t st_size; //普通文件,對應的文件字節數
time_t st_atime; //文件最後被訪問的時間
time_t st_mtime; //文件內容最後被修改的時間
time_t st_ctime; //文件狀態改變時間
blksize_t st_blksize; //文件內容對應的塊大小
blkcnt_t st_blocks; //偉建內容對應的塊數量
};想要查看文件的某部分信息,直接按照數據結構的對應格式打印成員即可,如stat.ino_t。
10.6 共享文件
- 內核用三個相關的數據結構來表示打開的文件:
- 描述符表(descriptor table)每個進程都有它獨立的描述符表,它的表項是由進程打開的文件描述符來索引的。每個打開的描述符表項指向文件表中的一個表項。
- 文件表(file table) 打開文件的描述符表項指向問價表中的一個表項。所有的進程共享這張表。每個文件表的表項組成包括由當前的文件位置、引用計數(既當前指向該表項的描述符表項數),以及一個指向v-node表中對應表項的指針。關閉一個描述符會減少相應的文件表表項中的應用計數。內核不會刪除這個文件表表項,直到它的引用計數為零。
- v-node表(v-node table)同文件表一樣,所有的進程共享這張v-node表,每個表項包含stat結構中的大多數信息,包括st_mode和st_size成員。
看下圖:
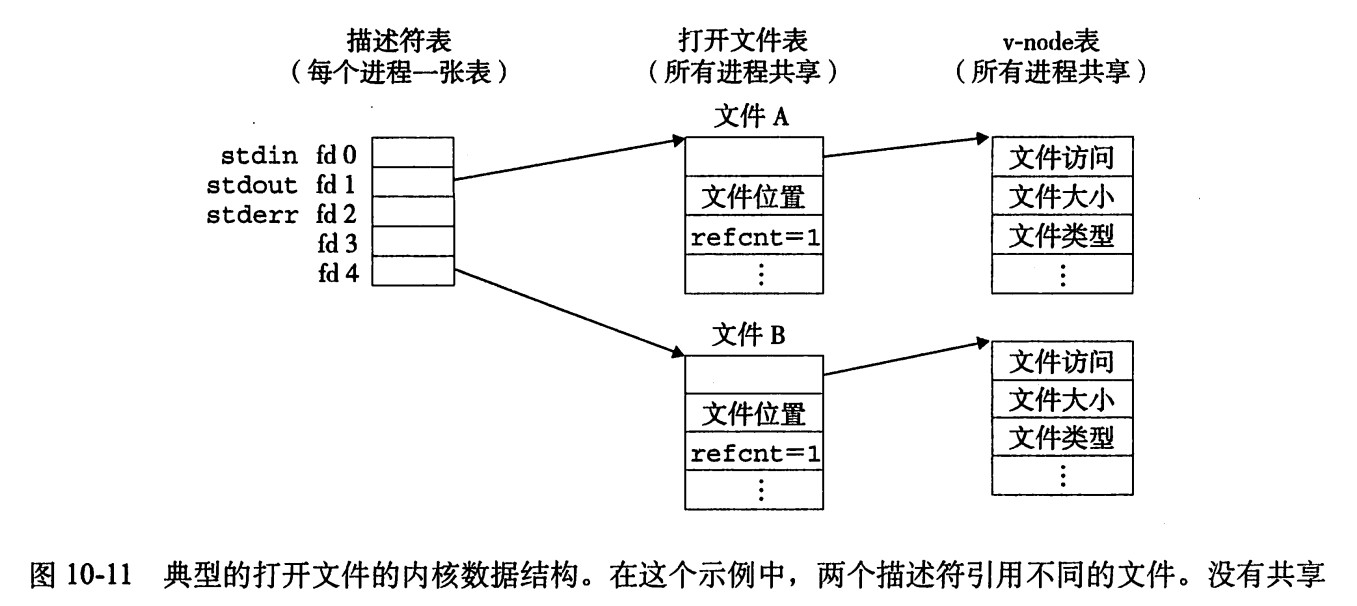
描述符1和4通過不同的打開文件表表項來引用兩個不同的文件。這是典型的情況,沒有共享文件,並且每個描述符對應一個不同的文件。
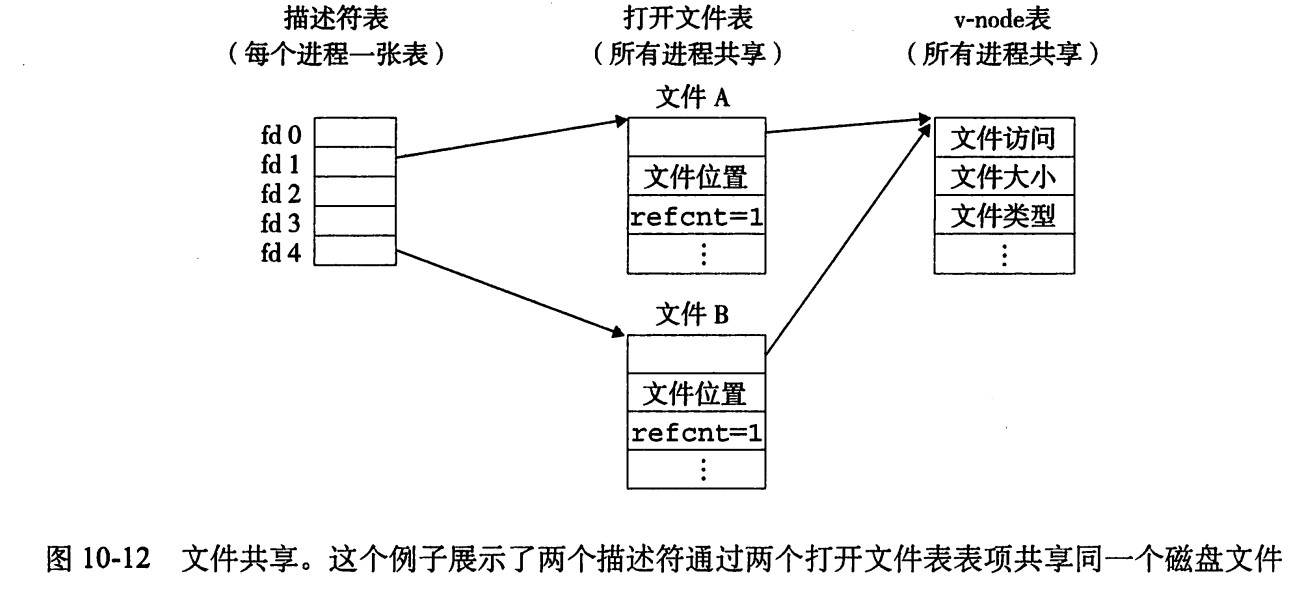
多個描述符也可以通過不同的文件表表項來應用同一個文件。如果同一個文件被open兩次,就會發生上面的情況。關鍵思想是每個描述符都有它自己的文件位置,所以對不同描述符的讀操作可以從文件的不同位置獲取數據。
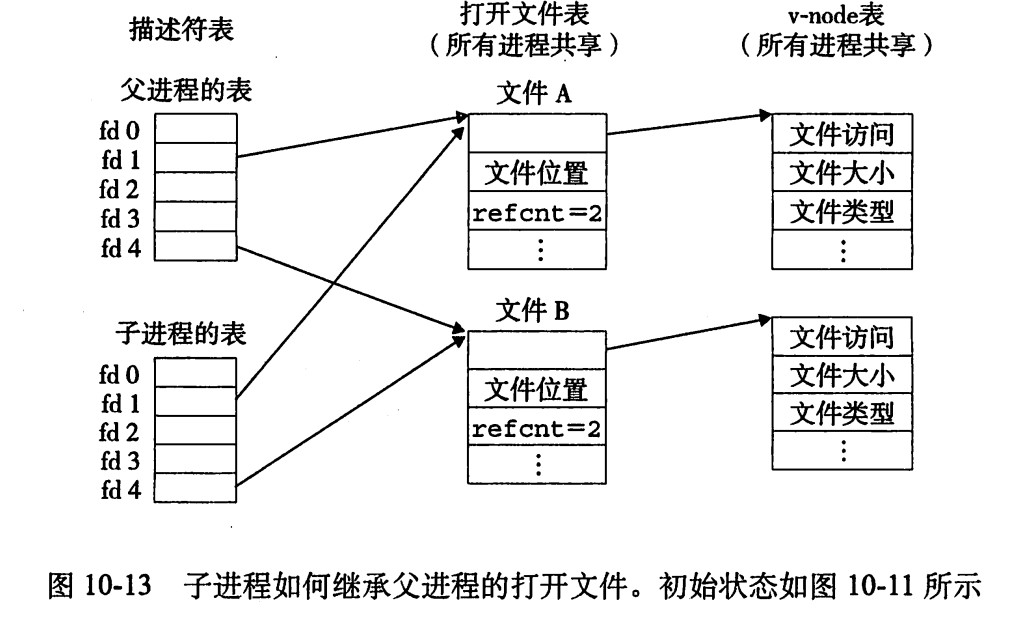
父子進程也是可以共享文件的,在調用
fork()之前,父進程如第一張圖,然後調用fork()之後,子進程有一個父進程描述符表的副本。父子進程共享相同的打開文件表集合,因此共享相同的文件位置。一個很重要的結果就是,在內核刪除相應文件表表項之前,父子進程必須都關閉了他們的描述符。
10.7 I/O重定向
重定向的一個標誌就是 >。比如之前上課老師執行過的
who > user其實就是外殼加載和執行完who程序,將應有的屏幕輸出(或者可以理解為終端的printf)重定向到user這個文件中。
重定向是如何工作的呢?一種方式是使用dup2函數
#include <unistd.h>
int dup2(int oldfd, int newfd);通過兩個參數old和new應該也猜出來了,dup2函數將描述符表表項oldfd拷貝到newfd,覆蓋描述newfd以前的內容,也就是說,如果newfd是之前打開過的描述符,那麽newfd會被關閉,再執行oldfd到newfd的拷貝。
10.8 標準I/O
標準I/O庫提供了Unix I/O的較高級別的替代。
- 標準I/O庫將一個打開的文件模型化為一個流。對於一個程序而言,一個流就是一個指向
FILE類型的結構的指針。- 類型為
FILE的流是對文件描述符和流緩沖區的抽象。流緩沖區的目的和RIO讀緩沖區的一樣:就是使開銷較高的UNIX I/O系統調用的數量盡可能的小。 - 庫中有打開和關閉文件的函數
fopen和fclose,讀和寫字節的函數fread和fwrite、讀和寫字符串的函數fgets和fputs,以及復雜格式化的I/O函數scanf和printf。
- 類型為
小結
Unix提供的系統級函數較少,應用程序在使用的時候反而會比較少的使用Unix I/O函數,而使用RIO包。標準I/O庫就是在Unix I/O的基礎上實現的,對於大多數應用程序而言,更簡單,是優於Unix I/O的選擇。然而,因為標準I/O和網絡文件不兼容,在網絡應用程序中會選擇使用Unix I/O。
教材學習中的問題和解決過程
- 問題1:以前常用
FILE類型來打開、讀寫文件,學習了系統級I/O後,open和fopen的區別到底在哪裏? - 問題1解決方案:
首先先了解兩個文件系統: - 緩沖文件系統
- 在內存開辟一個“緩沖區”,為程序中的每一個文件使用。
- 當執行讀文件的操作時,從磁盤文件將數據先讀入內存“緩沖區”,裝滿後再從內存“緩沖區”依此讀入接收的變量。
- 執行寫文件的操作時,先將數據寫入內存“緩沖區”,待內存“緩沖區”裝滿後再寫入文件。
- 非緩沖文件系統
- 緩沖文件系統是借助文件結構體指針來對文件進行管理,通過文件指針來對文件進行訪問,既可以讀寫字符、字符串、格式化數據,也可以讀寫二進制數據。
- 非緩沖文件系統依賴於操作系統,通過操作系統的功能對文件進行讀寫,是系統級的輸入輸出,不設文件結構體指針,只能讀寫二進制文件,但效率高、速度快。
fopen是ANSIC標準中的C語言庫函數,在不同的系統中應該調用不同的內核API,返回的是文件流,且是可移植的,fopen可以理解為封裝的函數。open主要用來打開設備文件,linux系統函數還是open。fopen和open最主要的區別是fopen在用戶態下就有了緩存,在進行read和write的時候減少了用戶態和內核態的切換,而open則每次都需要進行內核態和用戶態的切換;表現為,如果順序訪問文件,fopen系列的函數要比直接調用open系列快;如果隨機訪問文件open要比fopen快。
代碼調試中的問題和解決過程
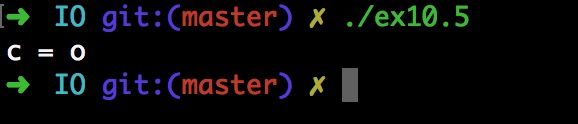
問題1:在完成10.5練習題的時候,幾經深思熟慮得出輸出應該是
c = o,結果一運行結果是c = f,不服輸的我去看了答案,發現是c = o,檢查程序後發現少寫了一個Read。
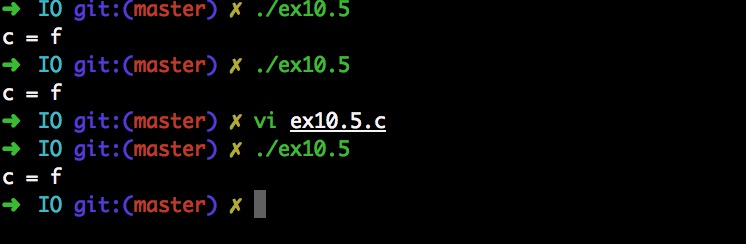
問題1解決方法:少寫
Read描述符自然停留在上次Read的f字母上,就算復制了描述符也沒用,必須Read(fd1)才能體會dup2函數的作用。
代碼托管
結對及互評
本周結對學習情況
20155313
結對學習內容
學習進度條
| 代碼行數(新增/累積) | 博客量(新增/累積) | 學習時間(新增/累積) | 重要成長 | |
|---|---|---|---|---|
| 目標 | 5000行 | 30篇 | 400小時 | |
| 第一周 | 195/195 | 1/1 | 10/10 | |
| 第三周 | 314/706 | 1/2 | 15/25 | |
| 第五周 | 254/960 | 2/4 | 10/35 | |
| 第七周 | 24/1759 | 2/6 | 15/50 | |
| 第九周 | 1207/2966 | 2/8 | 15/65 | |
| 第十一周 | 1207/2966 | 2/10 | 15/65 | |
| 第十三周 | 419/3385 | 3/13 | 16/81 | |
| 第十四周 | 104/3489 | 1/14 | 15/96 |
計劃學習時間:12小時
實際學習時間:15小時
參考資料
- 《深入理解計算機系統V3》學習指導
- fopen和open的區別
2017-2018-1 20155201 《信息安全系統設計基礎》第十四周學習總結