
如何通過人工智能“避開”內容安全的“坑”?

網易雲易盾CTO朱浩齊
在《AI安全分論壇》,網易雲易盾CTO朱浩齊受邀出席,並分享了《人工智能在內容安全的應用實踐》主題內容。
隨著政策的收緊,“內容安全”成為各大平臺、網站的“心病”。2017年以來,因為內容安全問題而被勒令下架、停播、整改的事件相信各位還歷歷在目。伴隨著人工智能的快速發展,以往依靠人工審核的傳統方式已經無法滿足龐大體量的平臺、網站的需求。
那麽如何依靠人工智能避開“內容安全”的坑?以下讓我們一探究竟。
人工智能技術的初步應用
隨著網絡強國戰略思想、加強網絡內容建設等指導思想的推出和強化,內容安全已經成為互聯網企業生存和發展的生命線。朱浩齊表示,國家多次強調互聯網不是法外之地,利用網絡散布×××材料、進行人身***、兜售非法物品等言行要堅決管控,因此絕不能任其大行其道。
然而,傳統的內容技術已難以滿足企業日益增長的安全需求,就拿圖像來說,傳統的×××識別技術為例,就經常會存在誤判、錯判、漏判等情況。
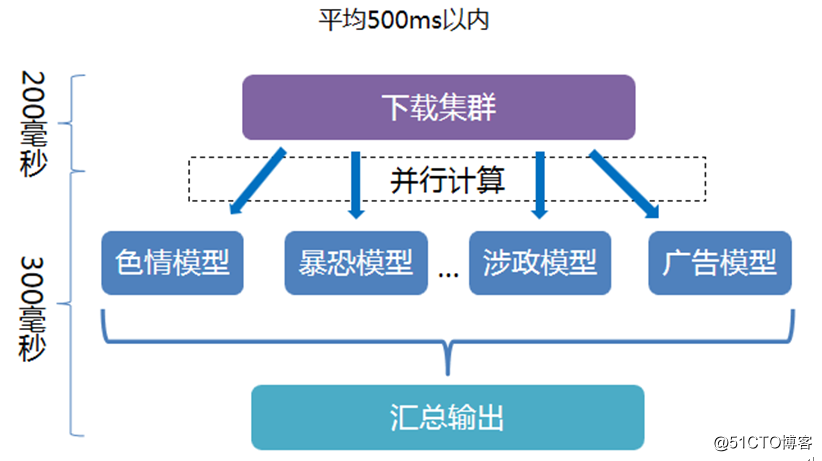
而基於深度學習模型的圖像分類,則可以實現更高的準確率,以及圖像、內容文本實時處理。實時圖像處理的背後是這樣的一個技術架構在支撐:下載集群和並行計算,然後再經過×××模型、暴恐模型、涉政模型、廣告模型等判斷處理,然後給出結果處理。這一套流程下來,平均時長僅在500ms以內。
在文本內容識別上,之前的傳統技術存在著各種各樣的問題:
變化多:垃圾變種形式多樣,內容重復率低;規則系統需要及時維護龐大的規則庫才能較好的攔截,人工審核量巨大。
內容短:1~2句話居多,詞匯量少;常規的文本分類模型不適用。
多語義:部分敏感詞有多重語義;容易誤判正常語境下的內容
詞序敏感:同樣的詞在不同詞序下會有不同的語義;現有方法無法較好地處理這種問題。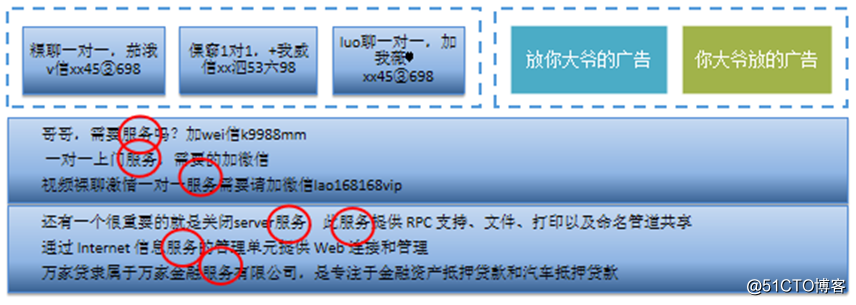
而人工智能技術的應用則可以進行準確實時的文本處理,包括垃圾內容變種智能識別與修正、多意義上下文短文本垃圾檢測、Deep Learning垃圾檢測等。
具體是: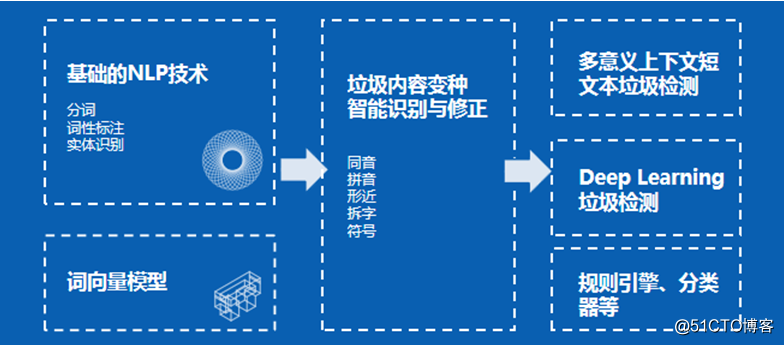
-
垃圾內容變種智能識別與修正,能夠結合上下文,智能識別同音、拼音、形近、拆字、符號等變形內容。
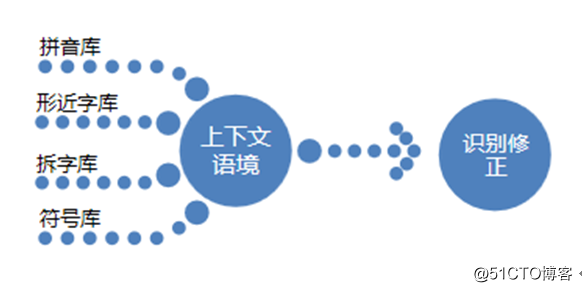
通過事先收錄的拼音庫、形近字庫、拆字庫、符號庫等字典,找出有變種嫌疑的內容,再結合上下文語境信息,使用Machine Learning技術判斷是否變種並進行修正。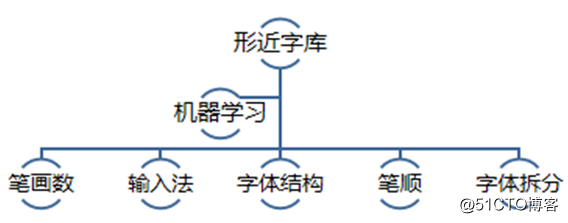
漢字有幾萬個,人工收集形近字耗時耗力,而且不全面。通過算法計算漢字的相似度,快速找出所有的形近字,再進行人工確認,保證精準度。
同樣一個“威”信,一個是“威”信的變種,一個不是,必須結合上下文語境進行判斷。多意義上下文短文本垃圾檢測,使用語義向量的方法識別垃圾語境,再結合垃圾關鍵詞識別短文本垃圾,有效解決詞匯量少、多義詞等技術難點。
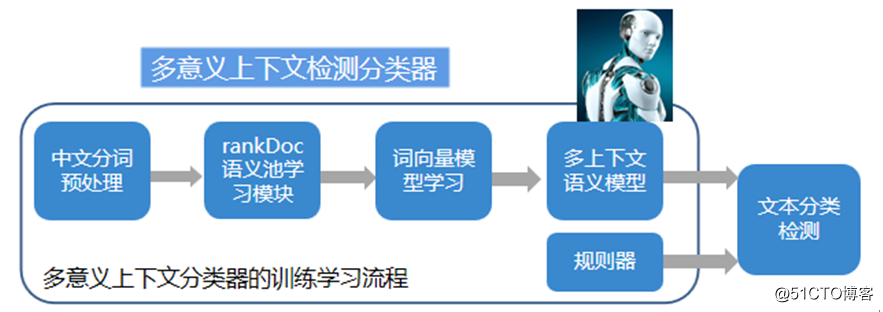
在這部分,基於深度學習模型的圖像分類,易盾會使用自主研發的rankDoc算法自動挖掘出不同垃圾類別的數據集。另外,還會在不同垃圾類別的數據集上分別學習詞向量模型,利用這些模型,結合機器學習方法在不同垃圾類別數據集上挖掘出每個詞對應的上下文信息。
此外在檢測時,對包含敏感詞的文本會根據上下文信息和人工定制的規則,判斷敏感詞是否為垃圾語義,並進一步給出全文的檢測結果。
檢測樣例如下所示: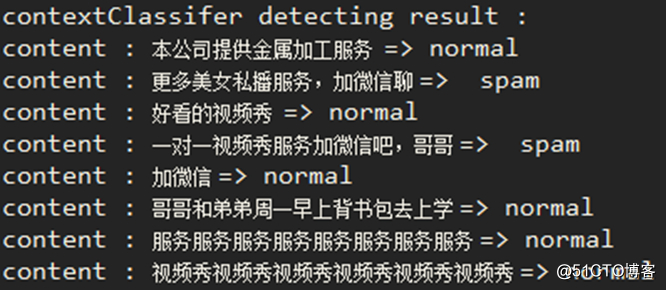
Deep Learning垃圾檢測,在語義向量、詞性識別等NLP技術的基礎上,利用RNN解決詞序敏感問題。
易盾對人工智能技術的再優化和探索
但是僅依靠現有的人工智能技術是難以保證百分之百的內容安全的,幹擾、特征小、尺度等因素下,昵稱、頭像、彈幕、打招呼、圖床、足跡等等無孔不入的垃圾信息不斷侵蝕著內容安全系統。因此,只有不斷進化才能在技術層面加強防禦實力。
為此,網易雲易盾在人工智能技術的定制、算法、工程等方面進行了繼續優化。
首先是提供了更為精細粒度的分類模型,篩選內容具體到6大類、20+場景、80+小類,在違規審查上更為嚴苛。此外,建立了人-物交互檢測網絡,關註人體有關部位及其附近物體,提取關鍵線索信息,能夠較好地識別出“人-動作-物體”三元組信息。
如上所示,人-物交互檢測模型在場景理解上的表現,包括視覺註意力機制(attention)、視覺關系檢測(visual relationship detection)以及“人-物”交互檢測(human-object interactions)。
通過持續的對抗訓練,網易雲易盾基於深度學習模型的圖像分類技術不僅可以解決微小擾動對於神經網絡的欺騙,而且可以對模型上線流程、對抗樣本進行準確的穩定性評估。
圖片來源:Beyond Adversarial Learning-Data Scaling Attacks in Deep Learning Applications
此外,音頻處理也是其中的重要影響因素。圖像分類技術能夠基於不同的語音場景分類,對語音事件進行檢測和識別,並且返回文本進行文本過濾。
基於以上的功能,網易雲易盾還做了定制化的模型,根據業務需要,將圖像處理分為預處理、模型、策略三階段。預處理階段輸入圖像特征分析或質量分析後,會根據需要進入基礎服務階段或定制服務階段。模型階段下,基礎分類網絡下數據將根據圖像全局特征網略、一般網絡、局部特征淺層網略進行模型整合和目標檢測,定制分類網絡則直接進入目標檢測。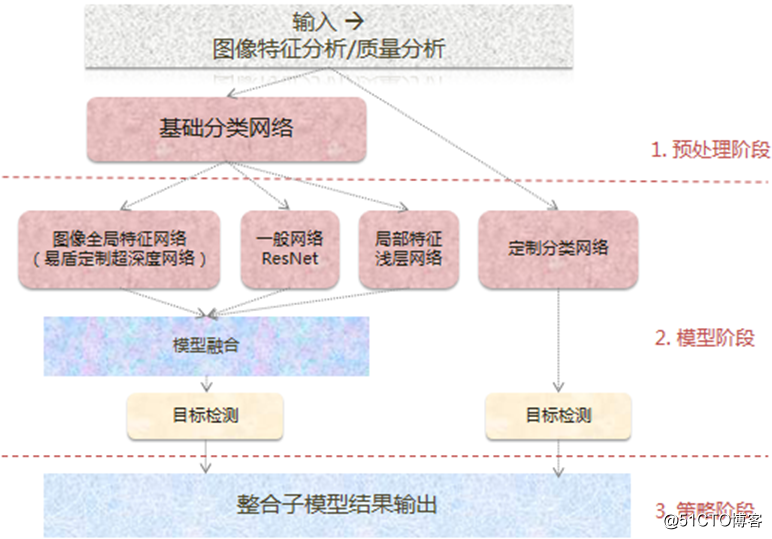
此外,網易雲易盾也在語種識別、處理效率、安全標準提升、審核團隊運營等方面不斷實現能力提升,包括增加或即將增加藏語、維語、泰語、印度語等語種識別;提升直播、短視頻的處理效率;密切配合監管部門,不斷完善內容安全標準;並且不斷優化審核系統、培養審核團隊。
未來
未來,網易雲易盾內容安全服務會遵守跨媒體智能、用戶行為分析、高度定制化模型的技術路線,致力於實現更為精準高效的服務體系,滿足不同企業的業務所需:
跨媒體智能:理解文本、圖片、視頻、音頻的內容後再進行安全分析;
用戶行為分析:收集更全面的用戶行為數據,配合用戶內容數據進行審核過濾;
高度定制化模型:緊貼監管部門政策法規、滿足客戶實際需求。
“作為網易雲旗下的一站式安全服務,網易雲易盾堅持提供可靠的內容安全服務。”分享最後,朱浩齊談到,未來他們將繼續認真打磨細節,保持足夠的耐心來持續叠代產品,將這種工匠精神發揚光大。此外,“業務仍然重於技術”,技術會進步,業務才是核心。
網易雲易盾依托團隊20年的技術積累及對網易數十條業務線的保障經驗,擁有海量特征庫和成熟的安全機制,並結合超強雲計算及人工智能技術,形成對遊戲、金融、電商、娛樂等場景化解決方案,目前已服務集團內外上千家客戶。
點擊免費體驗網易雲易盾內容安全解決方案。
如何通過人工智能“避開”內容安全的“坑”?