
DataFrame的groupby()函式
阿新 • • 發佈:2018-11-01
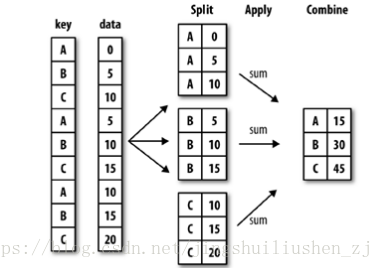
groupby()是一個分組函式,對資料進行分組操作的過程可以概括為:split-apply-combine三步:
1.按照鍵值(key)或者分組變數將資料分組。
2.對於每組應用我們的函式,這一步非常靈活,可以是python自帶函式,可以是我們自己編寫的函式。
3.將函式計算後的結果聚合。
舉例:
df = pd.DataFrame({'key1':list('aabba'),
'key2': ['one','two','one','two','one'],
'data1': [8,6,2,4,3],
'data2' 輸出:
data1 data2 key1 key2
0 8 6 a one
1 6 9 a two
2 2 5 b one
3 4 2 b two
4 3 -7 a one
下面這兩句效果是一樣的。
df.groupby('key1',as_index=False).mean()
df.groupby(['key1'],as_index=False).mean()
輸出:
key1 data1 data2
0 注意groupby之後的資料型別,它不再是一個dataframe,而是一個GroupBy物件,我們後面函式的任何操作都是基於這個物件的。
剛剛我們只是用了key1進行了分組,我們也可以使用兩個分組變數:
df.groupby(['key1','key2']).mean()
print '-----------------'
df.groupby(['key1','key2'],as_index=False).mean()
輸出:
data1 data2
key1 key2
a one 5.5 從上面可以看出,as_index=False與預設的True的區別來,加入as_index=False 屬性是"SQL-style"的分組輸出。
實際上分組鍵可以是任何長度適當的陣列
states=np.array(['Ohio','California','California','Ohio','Ohio'])
years=np.array([2005,2005,2006,2005,2006])
print df['data1'].groupby([states,years]).mean()
把data1列按照states和years分組,輸出:
California 2005 6
2006 2
Ohio 2005 6
2006 3
注意,像下面這麼寫是錯誤的:
print df['data1'].groupby(['key1']).mean()
如果前面是df[‘data1’]的形式,後面要這樣寫:
print df['data1'].groupby(df['key1']).mean()
輸出:
key1
a 5.666667
b 3.000000
Name: data1, dtype: float64
這麼寫也是可以的,輸出和上面一樣:
print df.groupby(['key1'])['data1'].mean()