
Spark SQL入門
阿新 • • 發佈:2018-11-01
Spark SQL
將SQL語句轉為底層的Spark作業執行,支援大量資料分析演算法。
資料抽象DataFrame
載入資料來源生成結構化資料
DataFrame的建立
import org.apache.spark.sql.SparkSession import spark.implicits._ //將底層資料來源隱式轉為DataFrame val spark = SparkSession.builder().getOrCreate() val df = spark.read.json("file:///usr/local/spark.examples/src/main/resources/people.json")
DataFrame常用操作
df.show() //顯示資料表
df.printSchema() //列印模式
df.select(df("name"),df("age")).show() //查詢
df.filter(df("age")>20).show() //過濾
df.groupBy(df("age")) //分組聚合
df.sort(df("age")) //升序
df.rdd.saveAsTextFile("....") //儲存為檔案
RDD轉換為DataFrame
反射機制推斷RDD模式
txt檔案
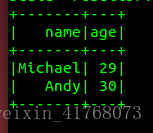
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder import org.apache.spark.sql.Encoder import org.apache.spark.sql.SparkSession import spark.implicits._ //將底層資料來源隱式轉為DataFrame case Person(name:String,age:Long) //定義要轉換成的DF類 val peopleDF = spark.sparkContext.textFile("file:///usr/local/spark.examples/src/main/resources/people.json").map(line => line.split(",")).map(attributes => Person(attributes(0),attributes(1).trim.toInt)).toDF //spark是上段程式碼的SparkSession物件,載入檔案成為RDD,分割",",RDD是一個個Array,把每個Array生成物件Person,轉為DF peopleDF.createOrReplaceTempView("people") //註冊為臨時表 val resultDF = spark.sql(“select name,age from people where age >20”) //使用SQL語句進行查詢 resultDF.show()
結果如下:
使用程式設計方式定義RDD模式
無法提前 cass class的情況
三個步驟
- 製作“表頭”
- 製作“表的記錄”
- 拼裝表頭和記錄
import org.apache.spark.sql.types._ import org.apache.spark.sql.Row //製作欄位 StructField 第一個引數數字段名,第二個是型別,第三個是是否可null val fields = Array(StructField("name",StringType,true), StructField("age",IntegerType,true)) val schema = StructType(fields) //製作成模式 //載入資料來源成為RDD ... //製作表中記錄 line =>Array => Row val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim.toInt)) //拼裝 val peopleDF = spark.createDataFrame(rowRDD, schema)
通過JDBC連線資料庫
//帶引數啟動spark-shell
./bin/spark-shell --jars /usr/local/spark/jars/mysql-connector-java-5.1.46/mysql-connector-java-5.1.46-bin.jar --driver-class-path /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.46-bin.jar
//讀
val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/spark").option("driver","com.mysql.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "hadoop").load()
//寫
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
//下面我們設定兩條資料表示兩個學生資訊
val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26","4 Guanhua M 27")).map(_.split(" "))
//下面要設定模式資訊
val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
//下面建立Row物件,每個Row物件都是rowRDD中的一行
val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
//建立起Row物件和模式之間的對應關係,也就是把資料和模式對應起來
val studentDF = spark.createDataFrame(rowRDD, schema)
//下面建立一個prop變數用來儲存JDBC連線引數
val prop = new Properties()
prop.put("user", "root") //表示使用者名稱是root
prop.put("password", "hadoop") //表示密碼是hadoop
prop.put("driver","com.mysql.jdbc.Driver") //表示驅動程式是com.mysql.jdbc.Driver
//下面就可以連線資料庫,採用append模式,表示追加記錄到資料庫spark的student表中
studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark", "spark.student", prop)