
Spark 中 map 與 flatMap 的比較
通過一個實驗來看Spark 中 map 與 flatMap 的區別。
步驟一:將測試資料放到hdfs上面
hadoopdfs -put data1/test1.txt /tmp/test1.txt
該測試資料有兩行文字:

步驟二:在Spark中建立一個RDD來讀取hdfs檔案/tmp/test1.txt

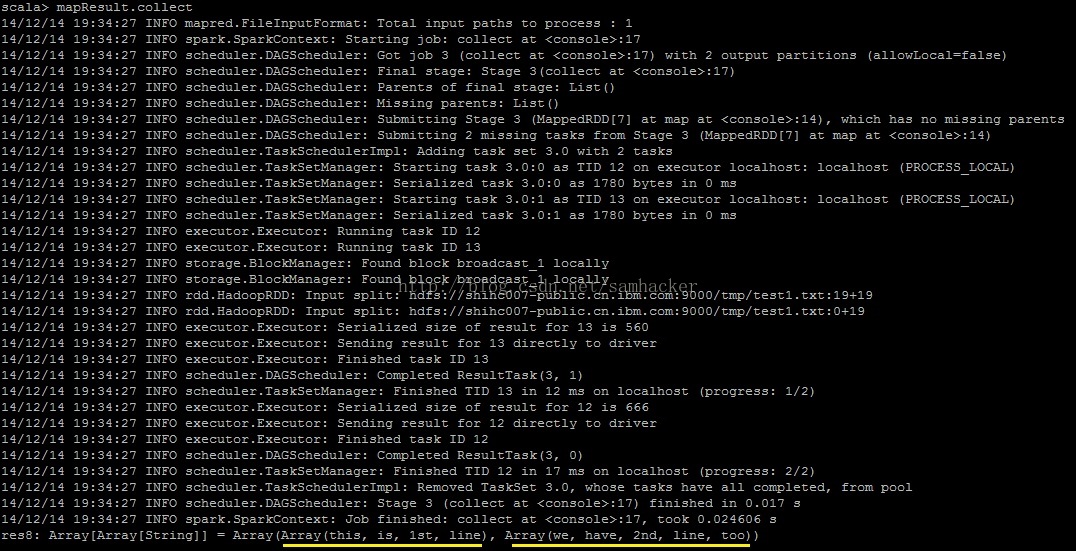
步驟三:檢視map函式的返回值
得到map函式返回的RDD:

檢視map函式的返回值——檔案中的每一行資料返回了一個數組物件
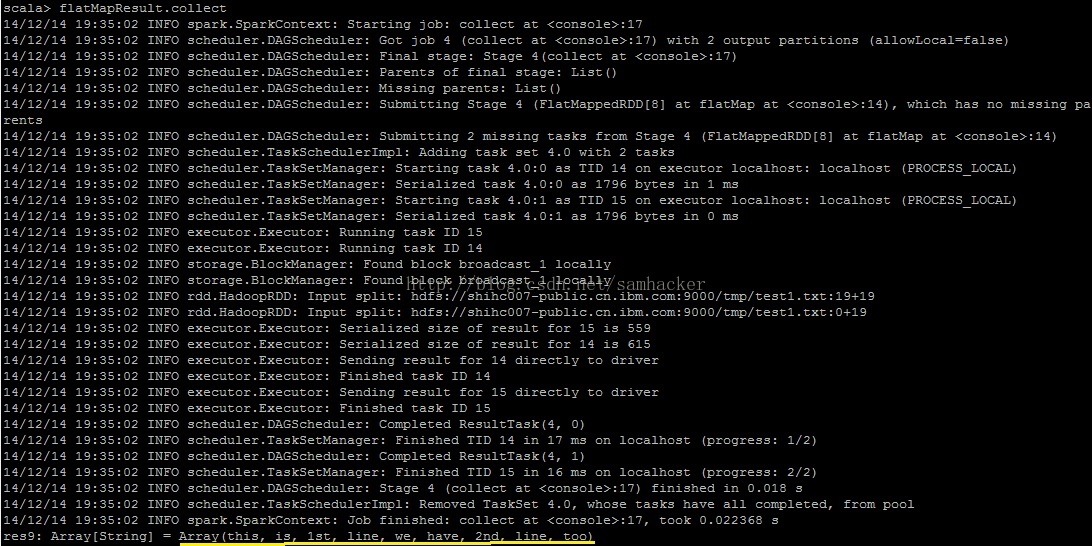
步驟四:檢視flatMap函式的返回值
得到flatMap函式返回的RDD:

檢視flatMap函式的返回值——檔案中的所有行資料僅返回了一個數組物件
總結:
- Spark 中 map函式會對每一條輸入進行指定的操作,然後為每一條輸入返回一個物件;
- 而flatMap函式則是兩個操作的集合——正是“先對映後扁平化”:
操作1:同map函式一樣:對每一條輸入進行指定的操作,然後為每一條輸入返回一個物件
操作2:最後將所有物件合併為一個物件
相關推薦
Spark 中 map 與 flatMap 的比較
通過一個實驗來看Spark 中 map 與 flatMap 的區別。 步驟一:將測試資料放到hdfs上面 hadoopdfs -put data1/test1.txt /tmp/test1.txt 該測試資料有兩行文字: 步驟二:在Spark
Spark中map與flatMap
必須 ret iter ext within serve 函數 range fail map將函數作用到數據集的每一個元素上,生成一個新的分布式的數據集(RDD)返回 map函數的源碼: def map(self, f, preservesPartitioning=Fal
spark中map與mapPartitions區別
part print map spark 偽代碼 一個 數據 最終 partition 在spark中,map與mapPartitions兩個函數都是比較常用,這裏使用代碼來解釋一下兩者區別 import org.apache.spark.{SparkConf, Spar
Spark之中map與flatMap的區別
一直不太明白spark之中map與flatMap之間的區別。map的作用很容易理解就是對rdd之中的元素進行逐一進行函式操作對映為另外一個rdd。flatMap的操作是將函式應用於rdd之中的每一個元素,將返回的迭代器的所有內容構成新的rdd。通常用來切分單詞。 區別1: flatM
Spark中map和flatMap的區別
Map和flatMap的區別 Transformation 含義 map(func) 返回一個新的RDD,該RDD由每一個輸入元素經過func函式轉換後組成 flatMap(func) 類似於map,但是每一個輸入元素可以被對映為0或多個輸出
spark中map和flatmap之間的區別
map()是將函式用於RDD中的每個元素,將返回值構成新的RDD。 flatmap()是將函式應用於RDD中的每個元素,將返回的迭代器的所有內容構成新的RDD,這樣就得到了一個由各列表中的元素組成的RDD,而不是一個列表組成的RDD。 有些拗口,看看例子就明白了。 val
Spark學習筆記 --- Spark中Map和FlatMap轉換的區別
wechat:812716131 ------------------------------------------------------ 技術交流群請聯絡上面wechat ----------------------------------------------
spark 中map 和flatmap 的區別
需求背景: 統計相鄰兩個單詞出現的次數。 val s="A;B;C;D;B;D;C;B;D;A;E;D;C;A;B" s: String = A;B;C;D;B;D;C;B;D;A;E;D;C;A;B val data=sc.parallelize(Seq(s)
RxJava 中的map與flatMap
1、map和flatMap都是接受一個函式作為引數(Func1) 2、map函式只有一個引數,引數一般是Func1,Func1的<I,O>I,O模版分別為輸入和輸出值的型別,實現Func1的call方法對I型別進行處理後返回O型別資料3、flatMap函式也只有
spark RDD操作map與flatmap的區別
以前總是分不清楚spark中flatmap和map的區別,現在弄明白了,總結分享給大家,先看看flatmap和map的定義。 map()是將函式用於RDD中的每個元素,將返回值構成新的RDD。 flatmap()是將函式應用於RDD中的每個元素,將返回的迭代器的所有內容構成
spark RDD 的map與flatmap區別說明
HDFS到HDFS過程看看map 和flatmap的位置Flatmap 和map 的定義 map()是將函式用於RDD中的每個元素,將返回值構成新的RDD。flatmap()是將函式應用於RDD中的每個元素,將返回的迭代器的所有內容構成新的RDD例子:val rdd = sc
大數據spark中ml與mllib 的區別你分清了嗎?
科技 ;大數據;spark 大數據學習過程中一個重要的環節就是spark,但是在spark中有很多的知識點,很多人都傻傻分不清楚,其中,最易搞混的就是ml與mllib的區別,所以我們不妨來詳細的了解一下二者的區別。 如果你想了解大數據的學習路線,想學習大數據知識以及需要免費的學習資料可以加群:784789
Verilog中函式與任務比較
http://blog.163.com/taofenfang_05/blog/static/64214093201181692057682/ 任務和函式只能實現組合邏輯,而對時序邏輯無能為力。 1 任務 任務就是一段封裝在“task-endtask”之間的程式
java8中 map和flatmap的共同點和區別,以及兩者的例項解析
在函式式語言中,函式作為一等公民,可以在任何地方定義,在函式內或函式外,可以作為函式的引數和返回值,可以對函式進行組合。由於指令式程式設計語言也可以通過類似函式指標的方式來實現高階函式,函式式的最主要的好處主要是不可變性帶來的。沒有可變的狀態,函式就是引用透明(Referen
JAVA中Long與Integer比較容易犯的錯誤
今天使用findbugs掃描專案後發現很多高危漏洞,其中非常常見的一個是比較兩個Long或Integer時直接使用的==來比較。 其實這樣是錯誤的。 因為Long與Ineger都是包裝型別,是物件。 而不是普通型別long與int , 所以它們在比較時必須都應該用equ
Spark中Map、Shulffe、Reduce的含義解釋
初入spark門,會出現這些名詞,半年了我表示都沒有很名錶這些詞的意思,在具體工作中指代什麼環節。今天看了這個部落格突然頓悟....摘下重點。1.Map階段讀取源表的資料,Map輸出時候以Join on條件中的列為key,如果Join有多個關聯鍵,則以這些關聯鍵的組合作為ke
Java 中 Map與JavaBean之間的相互轉化
在做匯入的時候,遇到了需要將map物件轉化 成javabean的問題,也就是說,不清楚javabean的內部欄位排列,只知道map的 key代表javabean的欄位名,value代表值。 那現在就需要用轉化工具了。是通用的哦! 首先來看 JavaBean 轉化成Ma
fastjson中Map與JSONObject互換,List與JOSNArray互換的實現
在開發過程中經常用到Map,與List轉換成json返回前臺的情況,找了一些實現方法,在此記錄,方便以後查詢。 1、//將map轉換成jsonObject JSONObject itemJSONObj = JSONObject.parseObject(JSON.t
JAVA中Long與Integer 比較的誤區
今天使用findbugs掃描專案後發現很多高危漏洞,其中非常常見的一個是比較兩個Long或Integer時直接使用的==來比較。 其實這樣是錯誤的。 因為Long與Ineger都是包裝型別,是物件。 而不是普通型別long與int , 所以它們在比較時必須都應該用eq
java中Integer與int比較淺談
今天看到一個面試題 測試程式碼如下 public class test { @Test public void test(){ Integer a = 300 ; Integer b = 300; int c = 300; System.out.println(a == b); System.out.pri