
螞蟻金服P6面試
1、自我介紹、自己做的專案和技術領域
2、專案中的監控:那個監控指標常見的有哪些?
效能測試需要使用不同的工具,結合系統日誌,監控伺服器、應用等方面的多項指標。以下闡述監控指標、監控工具、瓶頸分析。
服務端監控指標
效能測試通常需要監控的指標包括:
伺服器 Linux(包括CPU、Memory、Load、I/O)。
資料庫:Mysql(快取命中、索引、單條SQL效能、資料庫執行緒數、資料池連線數)。
中介軟體:1.tomcat 2、nginx 3、memcache(包括執行緒數、連線數、日誌)。
網路: 吞吐量、吞吐率。
應用: jvm記憶體、日誌、Full GC頻率。
客戶端監控指標
LoadRunner:使用者執行情況、場景狀態、事務響應時間、TPS、吞吐量等。
測試機資源:CPU、Memory、網路、磁碟空間。
常用監控工具
Jstat
監控java 程序GC情況,判斷GC是否正常。
JConsole
監控java記憶體、javaCPU使用率、執行緒執行情況等,需要在JVM引數中進行配置。
JMap
監控java程式是否有記憶體洩漏,需要配合eclipse外掛或者MemoryAnalyzer來使用。
JProfiler
全面監控每個節點的CPU使用率、記憶體使用率、響應時間累計值、執行緒執行情況等,需要在JVM引數中進行配置。
Nmon
全面監控linux系統資源使用情況,包括CPU、記憶體、I/O等,可獨立於應用監控。
Probe
全面監控tomcat的執行緒、記憶體、JVM CPU 使用率、OS 和 JVM記憶體使用率、交換區使用率、每30秒內接收到的請求數目等等
Memadim
1. 伺服器引數監控:STATS、SETTINGS、ITEMS、SLABS、SIZES實時重新整理
2. 伺服器效能監控:GET、DELETE、INCR、DECR、CAS等常用操作命中率實時監控
3. 支援資料遍歷,方便對儲存內容進行監視
4. 支援條件查詢,篩選出滿足條件的KEY或VALUE
效能分析
分析資訊來源
5. 監控工具所採集的資訊。包括TPS、響應時間、使用者併發數、JVM記憶體、Full GC頻率、tomcat連線數,資料sql執行時間、memcache的命中率、nginx的連線數等。
6. 應用伺服器的日誌。包括錯誤日誌、超時日誌等。
7. 專案配合人員所提供的資訊。包括DBA提供的資料庫監控資訊、開發人員提供的程式碼邏輯資訊。
分析標準
1.通過效能指標的表現形式,分析效能是否穩定。比如:
2.響應時間是否符合效能預期,表現是否穩定。
3.應用日誌中,超時的概率,是否在可接受的範圍之內。
8. TPS維持在多大的範圍內,是否有波形出現,標準差有多少,是否符合預期。
9. 伺服器CPU、記憶體、load是否在合理的範圍內,等等。
分析工具
對於部分效能指標,可藉助自動分析工具,統計出資料的總體趨勢:
1、LoadRunner analysis 分析
LoadRunneranalysis是loadrunner的一個部件,用於將執行過程中所採集到的資料生成報表,主要用於採集TPS、響應時間、吞吐量、伺服器資源使用情況等變化趨勢。
2、Memory Analyzer分析
Memory Analyzer工具可以解析Jmap dump出來的記憶體資訊,查詢是否有記憶體洩漏。
3、nmon_analyser分析
nmon工具可以採集伺服器的資源資訊。列出CPU、MEM、網路、I/O等資源指標的使用情況。
4、MONyog分析
通過此工具我們能夠跟蹤到執行比較慢的sql語句,並且可以分析出sql語句執行時掃描的行數,使用的索引情況。
3、微服務涉及到的技術以及需要注意的問題有哪些?
微服務條目 技術 備註
服務開發 Springboot、Spring、SpringMVC
服務配置與管理 Netflix公司的Archaius、阿里的Diamond等
服務註冊與發現 Eureka、Consul、Zookeeper等
服務呼叫 REST、RPC、gRPC
服務熔斷器 Hystrix、Envoy等
負載均衡 Ribbon、Nginx等
服務介面呼叫(客戶端呼叫服務發簡單工具) Feign等
訊息佇列 kafka、RabbitMQ、ActiveMQ等
服務配置中心管理 SpringCloudConfig、Chef等
服務路由(API閘道器) Zuul等
服務監控 Zabbix、Nagios、Metrics、Spectator等
全鏈路追蹤 Zipkin、Brave、Dapper等
服務部署 Docker、OpenStack、Kubernetes等
資料流操作開發包 SpringCloud Stream(封裝與Redis,Rabbit、Kafka等傳送接收訊息)
事件訊息匯流排
SpringCloud Bus
使用微服務時的注意事項
在微服務架構帶了很多好處的同時,你需要認識到的很重要的一點,你正在進入分散式計算的世界。分散式計算總是一個複雜的課題,微服務也不例外。在開始使用微服務時,有幾件事你需要注意到。
複雜性增加
在微服務架構中,有很多可移動的元件,所以對服務的管理將變得更加複雜。相比於單節點應用的部署,你要部署成百上千的服務,還要讓它們在一起無縫的工作。這需要服務註冊和服務發現解決方案,以便一個新的或者更新的服務能夠讓自己被系統知道,能夠被其他服務檢測到。你也需要確保所有的服務都啟動並且在運行當中,沒有耗盡磁碟空間或者其他資源,並且保證足夠的效能。所有的服務通常都會需要負載均衡,並且使用同步或者非同步的訊息傳送來進行通訊。叢集管理和編排工具會幫助你解決一些問題,但是也需要你瞭解這些工具是如何進行工作的。在這系列部落格的第二部分,我們將更深入的瞭解叢集管理和編排如何幫助微服務進行工作的。
網路擁塞和延遲
微服務用來通訊的API使用的是標準協議,比如HTTP,所以網路成為重要因素。想象一下在一個應用中有數百個服務,通常一個請求就會跨多個不同的服務,不難看出,如果網路方面沒有給予足夠的重視的話,將會對應用的整體效能造成多大的影響。另一個經常被忽略的地方是資料的序列化和反序列化。有時,相同的資料從一個服務傳遞到另一個服務,它會被序列化和發序列化多次,從而大大增加了網路的延遲。有幾種模式可以使用,比如資料快取和服務,來限制請求的數量。對於序列化問題,你可以使用高效的序列化格式,並且在整個服務框架中使用這個共用的格式。這可能會在服務間傳遞資料時減少一些步驟,不需要再次序列化。
資料一致性
因為每一個微服務通常都會有它自己的狀態儲存,所以你必須要面臨分散資料所帶來的資料一致性和完整性挑戰。考慮下面的場景,訂單服務所引用的資料在另一個服務當中,比如產品目錄服務,你就需要維護該服務中的資料完整性。現在你在每個服務中都有一些相同的資料,必須要保證一致性;如果一個服務節點中的資料變更,其他節點中的資料必須一起進行變更。如果在產品目錄服務中的資料被刪除或者更新,比如有效產品項的數量,訂單服務就需要知道這種變化。處理這種一致性挑戰,以及諸如此類的資料一致性概念,可能很難得到正確的結果,但是幸運的是,這個問題已經被解決了。比如,你可以使用事件源或者通知服務之類的模式,將變化的資料釋出給已經訂閱這種變化和更新的資料消費服務。
容錯和彈性
微服務應用的特性之一是,即便在發生災難性故障時,它仍能夠實現容錯。由於在網路中存在很多微服務,因此,在微服務架構中,故障也更為普遍,也更具挑戰性。你可能想知道,這是怎麼發生的呢?因為微服務通常都執行在它們自己的程序或者容器當中,其他的微服務是不會直接影響到它的程序的。所以,一個壞的微服務怎麼會擊倒整個應用?我們來看個例子,如果一個微服務花費太長時間來進行相應,在服務呼叫中耗盡所有的執行緒資源,它就會引起整個呼叫鏈的級聯故障。對故障進行合適的處理,也會對應用正常執行時間的SLA產生影響。我們假設你的應用需要有99.9%的正常執行時間的SLA,也就是說每個月只允許大約44分鐘的停機。你的應用包含3個微服務,每個都提供99.9%的正常執行時間。每一個服務都有可能在不同的時間出現停止服務,你就會看到潛在的停機時間大約是132分鐘,明顯影響了整個應用正常執行時間的SLA。
要進行故障處理,讓你的應用實現容錯,你需要實現彈性模式,比如超時、重試、熔斷機制和隔離機制,這對於開發人員來說都是非常具有挑戰性的。
診斷
在微服務應用中,日誌和追蹤需要一個合理的策略。需要對日誌聚合和分析進行認真的思考,因為微服務應用中有成百上千個服務,生成了大量的日誌。此外,請求通常會跨越多個服務,所以,找到一種方法在整個系統中對請求進行標記非常重要,讓你能夠看清跨越所有服務的整個請求。這通常都是通過使用關聯或者傳遞給所有下游服務的活動ID來實現的,每一個服務都會將這個ID寫入它的日誌。由於服務是由不同的團隊開發的,所以確定一種統一的日誌格式也很重要。微服務應用的總體診斷與除錯是很有挑戰性的,必須在一開始就計劃好。在本系列的第三部分,我們將介紹一些診斷的最佳實踐。
版本控制
在單體系統中,呼叫一個介面的程式碼通常與介面的實現部署在一起。介面的中斷變更通常是在整合測試或者構建期間被捕獲。在微服務世界中,一個微服務介面的變更不需要呼叫它的微服務立即進行處理,因為他們可能有不同的釋出節奏。為了保證呼叫服務仍然能夠按照預期進行工作,需要整個團隊考慮並且認可服務版本控制技術。
DevOps
現金的DevOps,自動化和監控是微服務運營成功的關鍵。在生產環境中進行測試通常是一個目標,實現這個目標需要更多的強調監控,使我們能夠快速的檢測到異常和問題,並且根據需進行回滾。在自動化方面進行投資,使用諸如Blue-Green Deployment、Canaries、A/B Testing和特性標誌等工具和最佳實踐,非常重要。建立起一個定義良好的工作流,讓開發和運營一起工作,帶來敏捷、高質量的釋出,非常有挑戰性。本系列部落格的第三部分將對DevOps的流程進行更詳細的介紹。
4、註冊中心你瞭解了哪些?
微服務作為一項在雲中部署應用和服務的新技術已成為當下最新的熱門話題。現就微服務中註冊中心的選型做一下記錄。
當下實現微服務主要有兩種選擇,DUBBO和Spring Cloud,他們分別選擇zookeeper和eureka作為註冊中心。
一、什麼是CAP定理
在分散式系統領域有個著名的CAP定理:C——資料一致性,A——服務可用性,P——服務對網路分割槽故障的容錯性。這三個特性在任何分散式系統中不能同時滿足,最多同時滿足兩個。
二、Zookeeper
Zookeeper是著名Hadoop的一個子專案,很多場景下Zookeeper也作為Service發現服務解決方案。
很多場景下Zookeeper也作為Service發現服務解決方案。Zookeeper保證的是CP,即任何時刻對Zookeeper的訪問請求能得到一致的資料結果,同時系統對網路分割具備容錯性,但是它不能保證每次服務請求的可用性。從實際情況來分析,在使用Zookeeper獲取服務列表時,如果zookeeper正在選主,或者Zookeeper叢集中半數以上機器不可用,那麼將就無法獲得資料了。所以說,Zookeeper不能保證服務可用性。
誠然,對於大多數分散式環境,尤其是涉及到資料儲存的場景,資料一致性應該是首先被保證的,這也是zookeeper設計成CP的原因。
三、Eureka
Eureka本身是Netflix開源的一款提供服務註冊和發現的產品,並且提供了相應的Java封裝。Eureka保證的AP,在它的實現中,節點之間是相互平等的,部分註冊中心的節點掛掉也不會對叢集造成影響,即使叢集只剩一個節點存活,也可以正常提供發現服務。哪怕是所有的服務註冊節點都掛了,Eureka Clients上也會快取服務呼叫的資訊。這就保證了我們微服務之間的互相呼叫是足夠健壯的。
對於服務發現場景來說:針對同一個服務,即使註冊中心的不同節點儲存的服務提供者資訊不盡相同,也並不會造成災難性的後果。因為對於服務消費者來說,能消費才是最重要的——拿到可能不正確的服務例項資訊後嘗試消費一下,也好過因為無法獲取例項資訊而不去消費。
所以,對於服務發現而言,可用性比資料一致性更加重要——AP勝過CP。
5、consul 的可靠性你瞭解嗎?
6、consul 的機制你有沒有具體深入過?有沒有和其他的註冊中心對比過?
7、專案用 Spring 比較多,有沒有了解 Spring 的原理?AOP 和 IOC 的原理
8、Spring Boot除了自動配置,相比傳統的 Spring 有什麼其他的區別?
Spring Boot可以建立獨立的Spring應用程式;
內嵌瞭如Tomcat,Jetty和Undertow這樣的容器,也就是說可以直接跑起來,用不著再做部署工作了。
無需再像Spring那樣搞一堆繁瑣的xml檔案的配置;
可以自動配置Spring;
提供了一些現有的功能,如量度工具,表單資料驗證以及一些外部配置這樣的一些第三方功能;
提供的POM可以簡化Maven的配置;
9、Spring Cloud 有了解多少?
Spring Cloud是一個微服務框架,相比Dubbo等RPC框架, Spring Cloud提供的全套的分散式系統解決方案。
Spring Cloud對微服務基礎框架Netflix的多個開源元件進行了封裝,同時又實現了和雲端平臺以及和Spring Boot開發框架的整合。
Spring Cloud為微服務架構開發涉及的配置管理,服務治理,熔斷機制,智慧路由,微代理,控制匯流排,一次性token,全域性一致性鎖,leader選舉,分散式session,叢集狀態管理等操作提供了一種簡單的開發方式。
Spring Cloud 為開發者提供了快速構建分散式系統的工具,開發者可以快速的啟動服務或構建應用、同時能夠快速和雲平臺資源進行對接。
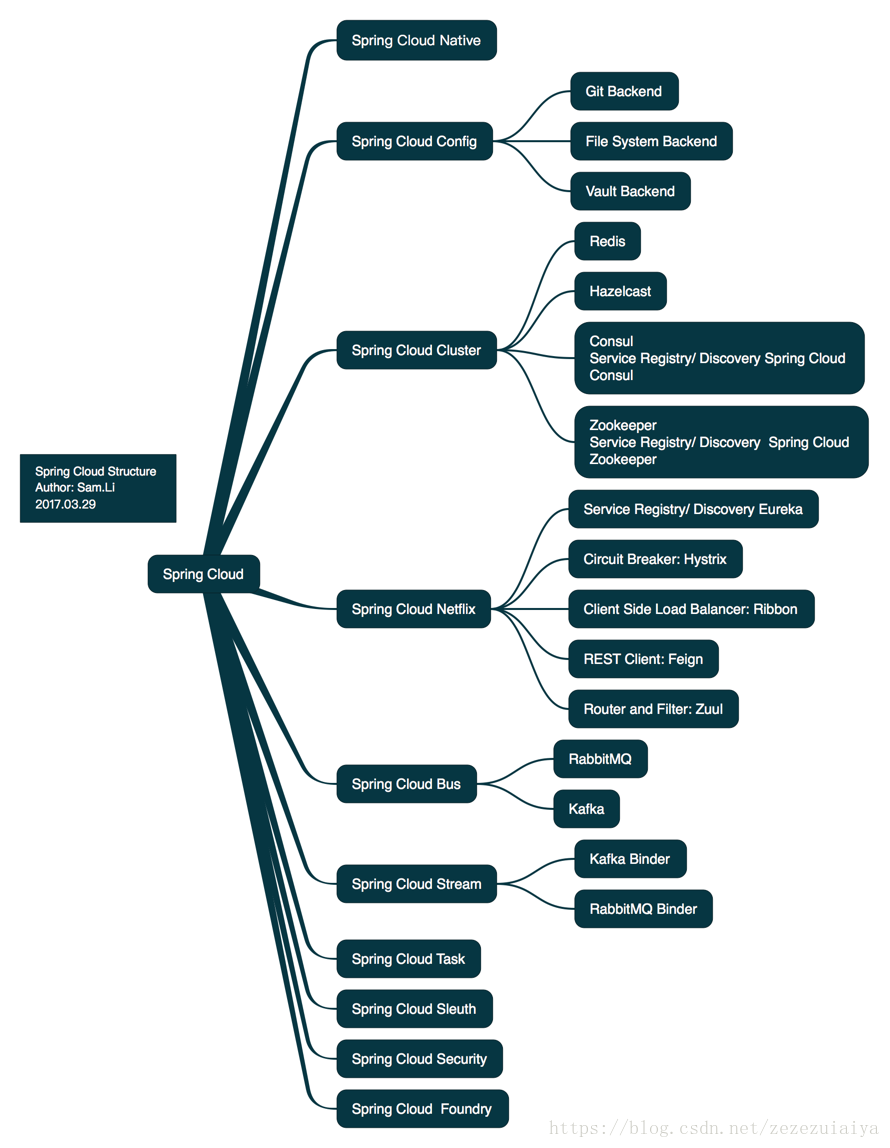
- Spring Cloud Config:配置管理工具,支援使用Git儲存配置內容,支援應用配置的外部化儲存,支援客戶端配置資訊重新整理、加解密配置內容等
- Spring Cloud Bus:事件、訊息匯流排,用於在叢集(例如,配置變化事件)中傳播狀態變化,可與Spring Cloud Config聯合實現熱部署。
- Spring Cloud Netflix:針對多種Netflix元件提供的開發工具包,其中包括Eureka、Hystrix、Zuul、Archaius等。
- Netflix Eureka:一個基於rest服務的服務治理元件,包括服務註冊中心、服務註冊與服務發現機制的實現,實現了雲端負載均衡和中間層伺服器的故障轉移。
- Netflix Hystrix:容錯管理工具,實現斷路器模式,通過控制服務的節點,從而對延遲和故障提供更強大的容錯能力。
- Netflix Ribbon:客戶端負載均衡的服務呼叫元件。
- Netflix Feign:基於Ribbon和Hystrix的宣告式服務呼叫元件。
- Netflix Zuul:微服務閘道器,提供動態路由,訪問過濾等服務。
- Netflix Archaius:配置管理API,包含一系列配置管理API,提供動態型別化屬性、執行緒安全配置操作、輪詢框架、回撥機制等功能。
- Spring Cloud for Cloud Foundry:通過Oauth2協議繫結服務到CloudFoundry,CloudFoundry是VMware推出的開源PaaS雲平臺。
- Spring Cloud Sleuth:日誌收集工具包,封裝了Dapper,Zipkin和HTrace操作。
- Spring Cloud Data Flow:大資料操作工具,通過命令列方式操作資料流。
- Spring Cloud Security:安全工具包,為你的應用程式新增安全控制,主要是指OAuth2。
- Spring Cloud Consul:封裝了Consul操作,consul是一個服務發現與配置工具,與Docker容器可以無縫整合。
- Spring Cloud Zookeeper:操作Zookeeper的工具包,用於使用zookeeper方式的服務註冊和發現。
- Spring Cloud Stream:資料流操作開發包,封裝了與Redis,Rabbit、Kafka等傳送接收訊息。
- Spring Cloud CLI:基於 Spring Boot CLI,可以讓你以命令列方式快速建立雲元件。
10、Spring Bean 的生命週期
11、HashMap 和 hashTable 區別?
1.Hashtable是執行緒安全的,它的每個方法中都加入了Synchronize方法
2.HashMap是繼承自AbstractMap類,而HashTable是繼承自Dictionary類。不過它們都實現了同時實現了map、Cloneable(可複製)、Serializable(可序列化)這三個介面
3.當需要多執行緒操作的時候可以使用執行緒安全的ConcurrentHashMap。ConcurrentHashMap雖然也是執行緒安全的,但是它的效率比Hashtable要高好多倍。因為ConcurrentHashMap使用了分段鎖,並不對整個資料進行鎖定
4.HashMap的get過程是先得到key的hash值,再把這個hash值與length-1按位與(取餘),得到table陣列的下標。取出這個下標值的key,與傳入的key比較,如果相同那就是這個了。如果不同呢,那就沿著這個單向連結串列向後找,直到找到或找到結束也找不到。這裡的length是有特點的,是2的n次方。
5.HashMap擴容機制是在put時,容量不夠用的時候。因為每個元素都是一個單向連結串列,所以map裡放的實際數量總是大於等於申請的空間。
6.HashMap可以接受null鍵值和值,而Hashtable則不能。
7.HashMap是非synchronized所以HashMap很快。
8.hashcode相同,所以兩個物件是相等的,HashMap將會丟擲異常,或者不會儲存它們。然後面試官可能會提醒他們有equals()和hashCode()兩個方法,並告訴他們兩個物件就算hashcode相同,但是它們可能並不相等。一些面試者可能就此放棄,而另外一些還能繼續挺進,他們回答“因為hashcode相同,所以它們的bucket位置相同,‘碰撞’會發生。因為HashMap使用連結串列儲存物件,這個Entry(包含有鍵值對的Map.Entry物件)會儲存在連結串列中。”這個答案非常的合理,雖然有很多種處理碰撞的方法,這種方法是最簡單的,也正是HashMap的處理方法
9.當一個map填滿了75%的bucket時候,和其它集合類(如ArrayList等)一樣,將會建立原來HashMap大小的兩倍的bucket陣列,來重新調整map的大小,並將原來的物件放入新的bucket陣列中。這個過程叫作rehashing,因為它呼叫hash方法找到新的bucket位置
。
10.當重新調整HashMap大小的時候,確實存在條件競爭,因為如果兩個執行緒都發現HashMap需要重新調整大小了,它們會同時試著調整大小。在調整大小的過程中,儲存在連結串列中的元素的次序會反過來,因為移動到新的bucket位置的時候,HashMap並不會將元素放在連結串列的尾部,而是放在頭部,這是為了避免尾部遍歷(tail traversing)。如果條件競爭發生了,那麼就死迴圈了。這個時候,你可以質問面試官,為什麼這麼奇怪,要在多執行緒的環境下使用HashMap呢?
12、Object 的 hashcode 方法重寫了,equals 方法要不要改?
13、Hashmap 執行緒不安全的出現場景
14、線上服務 CPU 很高該怎麼做?有哪些措施可以找到問題
15、JDK 中有哪幾個執行緒池?順帶把執行緒池講了個遍
16、SQL 優化的常見方法有哪些
17、SQL 索引的順序,欄位的順序
18、檢視 SQL 是不是使用了索引?(有什麼工具)
19、TCP 和 UDP 的區別?TCP 資料傳輸過程中怎麼做到可靠的?
20、說下你知道的排序演算法吧
21、查詢一個數組的中位數?
22、專案中你學到了什麼技術?(把三專案具體描述了很久)
23、微服務劃分的粒度
24、微服務的高可用怎麼保證的?
25、常用的負載均衡,該怎麼用,你能說下嗎?
26、閘道器能夠為後端服務帶來哪些好處?
27、Spring Bean 的生命週期
28、xml 中配置的 init、destroy 方法怎麼可以做到呼叫具體的方法?
29、反射的機制
30、Object 類中的方法
31、hashcode 和 equals 方法常用地方
32、物件比較是否相同
33、hashmap put 方法存放的時候怎麼判斷是否是重複的
34、Object toString 方法常用的地方,為什麼要重寫該方法
35、Set 和 List 區別?
36、ArrayList 和 LinkedList 區別
37、如果存取相同的資料,ArrayList 和 LinkedList 誰佔用空間更大?
38、Set 存的順序是有序的嗎?
39、常見 Set 的實現有哪些?
40、TreeSet 對存入對資料有什麼要求呢?
41、HashSet 的底層實現呢
42、TreeSet 底層原始碼有看過嗎?
43、HashSet 是不是執行緒安全的?為什麼不是執行緒安全的?
44、Java 中有哪些執行緒安全的 Map?
45、Concurrenthashmap 是怎麼做到執行緒安全的?
46、HashTable 你瞭解過嗎?
47、如何保證執行緒安全問題?
48、synchronized、lock
49、volatile 的原子性問題?為什麼 i++ 這種不支援原子性?從計算機原理的設計來講下不能保證原子性的原因
50、happens before 原理
51、cas 操作
52、lock 和 synchronized 的區別?
53、公平鎖和非公平鎖
54、Java 讀寫鎖
55、讀寫鎖設計主要解決什麼問題?
56、你專案除了寫 Java 程式碼,還有前端程式碼,那你知道前端有哪些框架嗎?
57、MySQL 分頁查詢語句
58、MySQL 事務特性和隔離級別
59、不可重複讀會出現在什麼場景?
60、sql having 的使用場景
61、前端瀏覽器地址的一個 http 請求到後端整個流程是怎麼樣?能夠說下嗎?
62、http 預設埠,https 預設埠
63、DNS 你知道是幹嘛的嗎?
64、你們開發用的 ide 是啥?你能說下 idea 的常用幾個快捷鍵吧?
65、程式碼版本管理你們用的是啥?
66、git rebase 和 merge 有什麼區別?
67、你們公司加班多嗎?