
機器學習演算法的評價指標
機器學習演算法的評價指標
關於作者
作者小碩一枚,研究方向為機器學習與自然語言處理,歡迎大家關注我的個人部落格https://wangjie-users.github.io/,相互交流,一起學習成長。
前言
機器學習的目標是使得我們模型的泛化能力足夠強,因此我們需要有衡量模型泛化能力的評價標準。對不同種類的機器學習問題,評價標準不一樣。迴歸問題常用均方誤差(MSE)、絕對誤差(MAE)等評價指標,分類問題評價指標則較多,如下圖所示。本文主要講解分類問題的評價指標。

二分類問題中常用的概念
首先解釋幾個二分類問題中常用的概念:True Positive, False Positive, True Negative, False Negative。它們是根據真實類別與預測類別的組合來區分的。
假設有一批測試樣本,只包含正例和反例兩種類別。則有:
- 預測值正例,記為P(positive)
- 預測值為反例,記為N(Negative)
- 預測值與真實值相同,記為T(True)
- 預測值與真實值相反,記為F(False)

上圖左半部分表示預測為正例,右半部分預測類別為反例;樣本中的真實正例類別在上半部分,下半部分為真實的反例。 - TP: 預測類別為正,真實類別也為正例;
- FP:預測類別為正例,真實類別為反例;
- FN:預測為反例,真實類別為正例;
- TN:預測為反例,真實類別也為正例;
精確率(precision)
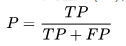
精確率是針對我們模型預測的結果而言的,它表示的是預測為正的樣本中有多少是真正的正樣本;
故分子為TP,而預測為正有兩種可能:真正(TP)和假正(FP),即為分母。
召回率(recall)
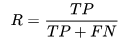
召回率是針對原始樣本而言的,表示樣本中的正例有多少被預測正確了,故分母應表示所有的原始樣本;
F1值
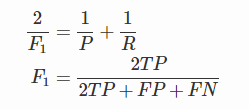
F1值是精確率和召回率的調和均值,當P和R值都高時,F1值也會高。
ROC、AUC
ROC全稱是“受試者工作特徵”(Receiver Operating Characteristic)。對於計算ROC,有三個重要概念:TPR,FPR,截斷點。
TPR即 True Positive Rate,表示真實的正例中,被預測正確的比例,即TPR = TP/(TP+FN);
FPR即 False Positive Rate, 表示真實的反例中,被預測正確的比例,即FPR = FP/(TN+FP);
很多ML演算法是為test樣本產生一個概率預測,然後將這個概率預測值與一個分類閾值(threhold)進行比較,若大於閾值則分為正類,反之為負類。這裡的閾值就是截斷點
截斷點取不同的值,TPR和FPR的計算結果也不同。將截斷點不同取值下對應的TPR和FPR結果作圖得到的曲線,就是ROC曲線。橫軸是FPR,縱軸是TPR。
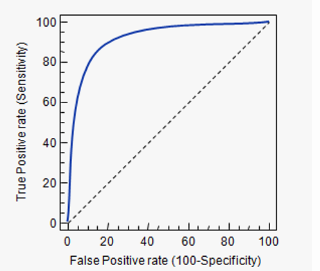
若比較兩個演算法的優劣,可以看哪個曲線能把另一個完全包住;或者計算曲線的面積,即AUC的值。
ROC經常用於樣本類別不均衡的二分類問題。
sklearn實現roc、auc
from sklearn.metrics import roc_curve, auc
fpr, tpr, th = roc_curve(test_Y, pred_y) # 得到一組fpr、tpr的值
roc_auc = auc(fpr, tpr) # 計算auc的值