
Python爬蟲_資料儲存
文章目錄
HTML正文抽取
HTML正文儲存主要分為兩種格式:JSON和CSV
儲存為JSON
需求:抽取小說標題、章節、章節名稱和連結
首先使用Requests訪問http://seputu.com/,獲取HTML文件內容,並列印文件內容
import requests
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)" 分析該網頁HTML結構,確定要抽取標記的位置,其中標題和章節都被包含在<dir class = “muln” 標記下,標題位於其中的《dir class = “muln-title”》下的《h2》中,章節位於其中的《dir class = “box”》下的《a》中
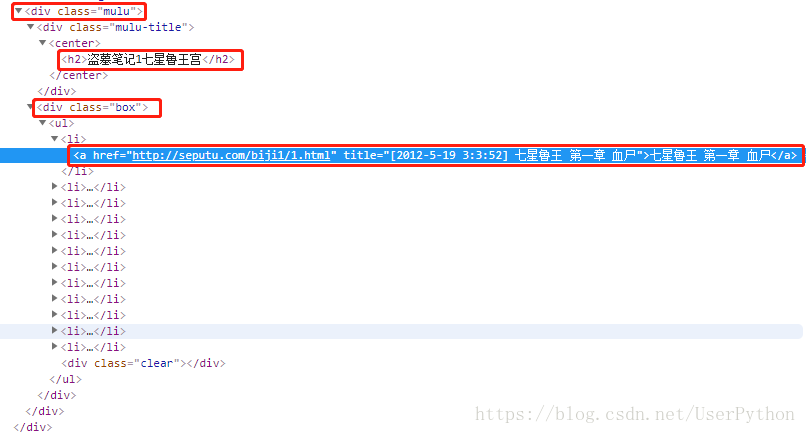
import - 已成功獲取標題、章節,接下來將資料儲存為JSON
import requests
from bs4 import BeautifulSoup
import json
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
headers = {"User-Agent" : user_agent}
r = requests.get("http://seputu.com/", headers = headers)
#指定使用utf-8解析文件
r.encoding = "utf-8"
#列印文件內容
# print(r.text)
soup = BeautifulSoup(r.text, "html.parser", from_encoding="utf-8")#其中"html.parser"是python標準庫預設解析器
content = []
# 找出所有含有mulu的文件
for mulu in soup.find_all(class_="mulu"):
# print(mulu) #檢視
# 獲取h2標籤Tag
h2 = mulu.find("h2")
# print(h2) #檢視
if h2 != None:
h2_title = h2.string #獲取h2中的文字標題
# print(h2_title) #檢視
list = []
# 在每個mulu中獲取章節名稱及其連結標籤a
for a in mulu.find(class_="box").find_all("a"):
href = a.get("href") # 從a標籤中獲取每個章節的連線
# print(href) #檢視
box_title = a.get("title") # 從a標籤中獲取章節名稱
# print(box_title) # 檢視
list.append({"href" : href, "box_title" : box_title})
content.append({"title" : h2_title, "content" : list})
with open("UserPython.json", "w", encoding="utf-8") as fp:
json.dump(content, fp=fp, indent=4, ensure_ascii= False)
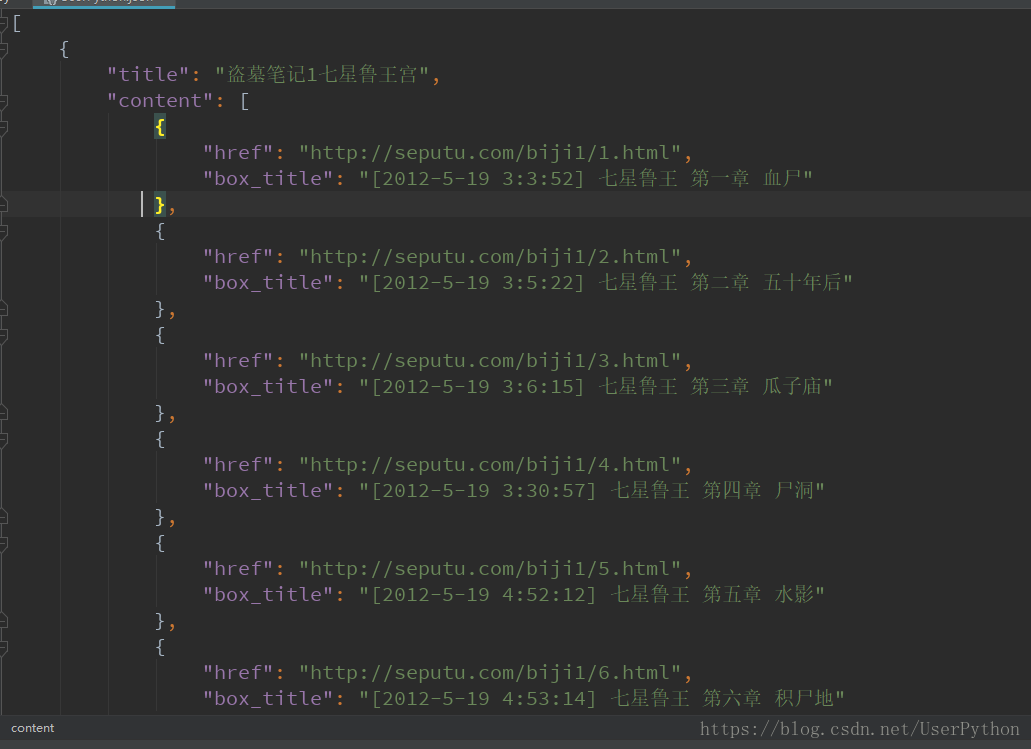
儲存為CSV
CSV(稱為逗號分隔值,有時也稱為字元分隔值,因為分隔符也可以不是逗號),其文字以純文字形式儲存表格資料(數字和文字)。純文字意味著該檔案是一個字元序列,不含必須像二進位制數字那樣被解讀的資料
CSV檔案由任意數目的記錄組成,記錄間以某種換行符分隔;每條記錄由欄位組成,欄位間的分隔符是其他字元或字串,最常見的是逗號或製表符。通常,所有記錄都有完全相同的欄位序列。CSV檔案示例如下
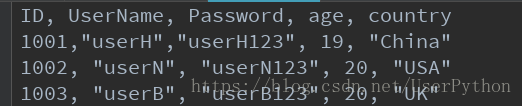
python使用CSV庫來讀寫CSV檔案。要將上面CSV檔案的示例內容寫成csvTest.csv檔案,需要用到Writer物件,程式碼如下
import csv
headers = ["ID", "UserName", "Password", "Age", "Country"]
rows = [(1001,"userH","userH123", 19, "China"),
(1002, "userN", "userN123", 20, "USA"),
(1003, "userB", "userB123", 20, "UK")]
with open("csvTest.csv", "w") as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(rows)
裡面的rows列表中的資料元組也可以是字典資料
import csv
headers = ["ID", "UserName", "Password", "Age", "Country"]
rows = [{"ID" : 1001, "UserName" : "userH", "Password" : "userH123", "Age" : 19, "Country" : "China"},
{"ID" : 1002, "UserName" : "userN", "Password" : "userN123", "Age" : 20, "Country" : "USA"},
{"ID" : 1003, "UserName" : "userB", "Password" : "userB123", "Age" : 20, "Country" : "UK"}]
with open("csvTest.csv", "w") as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
f_csv.writerows(rows)
上面的程式碼中,row會是一個表列,因此,為了訪問某個欄位,你需要使用索引,如row[0]訪問ID,row[3]訪問Age。由於這種索引訪問通常會引起混淆,因此可以考慮使用命名元組。示例如下
import csv
from collections import namedtuple
with open("csvTest.csv") as f:
f_csv = csv.reader(f)
headings = next(f_csv)
Row = namedtuple("Row", headings)
for r in f_csv:
row = Row(*r)
print(row.UserName, row.Password)
# print(row)
#########################################
userH userH123
userN userN123
userB userB123
它允許使用列名如row.UserName和row.Password代替下標訪問。需要注意的是這個只有列名合法的Python識別符號的時候才生效
除了使用命名組之外,另外一個解決辦法就是讀取到一個字典序列中,示例如下
import csv
with open("csvTest.csv") as f:
f_csv = csv.DictReader(f)
for row in f_csv:
print(row["UserName"], row["Password"])
# print(row.get("UserName"), row.get("Password"))
###########################
userH userH123
userN userN123
userB userB123
這樣就可以使用列名去訪問每一行的資料了。如row[“UserName”]或者row.get(“UserName”)
多媒體檔案抽取
儲存媒體檔案主要有兩種方式:只獲取檔案的URL連結,或者直接將媒體檔案下載到本地。這裡主要介紹urllib模組提供的urlretrieve()方法。urlretrieve()方法直接將遠端資料下載到本地,方法原型如下
urlretrieve(url, filename=None, reporthook=None, data=None)
引數說明:
filename:引數filename指定了儲存的本地路徑(如果引數未指定,urllib會生成一個臨時檔案儲存資料)
reporthook:引數reporthook是一個回撥函式。當連線上伺服器以及相應的資料塊傳輸完畢時會觸發該回調函式,我們可以利用這個回撥函式來顯示當前的下載進度
data:引數data指post到伺服器的資料,該方法返回一個包含兩個元素的(filename,headers)元組,filename表示儲存到本地的路徑,headers表示伺服器的響應頭
實踐:提取天堂圖片網的圖片(http://www.ivsky.com/tupian/ziranfengguang/)
需求:提取當前網址中的圖片連結,並將圖片下載到指定目錄
import urllib.request
from lxml import etree
import requests
def Schedule(blocknum, blocksize, totalsize):
"""
:blocknum: 已經下載的資料塊
:blocksize: 資料塊的大小
:totalsize: 遠端檔案的大小
"""
per = 100.0*blocknum*blocksize/totalsize
if per > 100:
per = 100
print("當前下載進度:%d" % per)
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
headers = {"User-Agent" : user_agent}
r = requests.get("http://www.ivsky.com/tupian/ziranfengguang/", headers = headers)
#使用lxml解析網頁
html = etree.HTML(r.text)
img_urls = html.xpath(".//img/@src") #先找到所有的img
i = 0
for img_urls in img_urls:
urllib.request.urlretrieve(img_urls,r'E:\Photo\img%s.jpg'%i, Schedule)
i += 1
❤️ 先將當前網址的img標記中的src屬性提取出來,交給urllib.request.urlretrieve函式去下載,自動回撥Schedule函式,顯示當前下載的進度
Email提醒
當爬蟲在執行過程中遇到異常或者伺服器遇到問題,可以通過Email及時向自己報告
傳送郵件的協議是STMP,Python內建對SMTP的支援,可以傳送純文字郵件、HTML郵件以及帶附件的郵箱。Python對SMTP支援有smtplib和email兩個模組,email負責構造郵件,smtplib負責傳送郵件
將郵箱的SMTP開啟後,我們來構造一個純文字郵件:
from email.mime.text import MIMEText
msg = MIMETest(“Python爬蟲執行異常,異常資訊為遇到HTTP 403”, “plain”, “utf-8”)
構造MIMEText物件時需要3個引數:
郵件正文:如"Python爬蟲執行異常,異常資訊為遇到HTTP 403"
MIME的subtype,傳入“plain”表示純文字,最終的MIME就是“text/plain”
設定編碼格式,UTF-8編碼保證多語言相容性
接著設定郵件的發件人、收件人和郵件主題等資訊,並通過SMTP傳送出去,程式碼如下
from email.mime.text import MIMEText
from email.header import Header
from email.utils import parseaddr, formataddr
import smtplib
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr((Header(name, "utf-8").encode(),addr))
#發件人地址
from_addr = "[email protected]"
#郵箱密碼
password="passwd"
#收件人地址
to_addr = "[email protected]"
#163網易郵箱伺服器地址
smtp_server = "smtp.163.com"
#設定郵箱資訊
msg = MIMEText("Python爬蟲執行異常,異常資訊為遇到HTTP 403", "plain", "utf-8")
msg["From"] = _format_addr("一號爬蟲<%s>" % from_addr)
msg["To"] = _format_addr("管理員<%s>" % to_addr)
msg["Subject"] = Header("一號爬蟲執行狀態", "utf-8").encode()
#傳送郵件
server = smtplib.SMTP(smtp_server, 25)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()
有時候我們傳送的可能不是純文字,需要傳送HTML郵件,將異常網頁資訊傳送出去。在構造MIMEText物件時,把HTML字串傳進去,再把第二個引數由“plain”改為“html”就可以了,示例如下
msg = MIMEText('<html><body><h1>Hello python</h1>' +
'<p>異常網頁<a href = "http://www.hhhh.com">...</p>' +
'</body></html>', "html", "utf-8")