
一、線性模型
1.線性迴歸
對包含$d$個屬性描述的資料${\bf{x}} = \{ {x_1},{x_2},...,{x_d}\}$,建立一個加權線性模型,$f({\bf{x}}) = {\omega _1}{x_1} + {\omega _2}{x_2} + ... + {\omega _d}{x_d} + b$,儘可能預測地準確對應的標籤值$y$,各權重$\omega$直觀表達了各屬性在預測中的重要性,因此線性模型有很好的可解釋性。
我們先考慮最簡單的情況,$d=1$。線性迴歸試圖學得$f(x_i) = {\omega }^T {x_i}+ b$,使得$f(x_i) \simeq {y_i}$。如何衡量這兩個之間的差別呢?均方誤差是迴歸任務中最常用的效能度量,因此我們可以試圖讓均方誤差最小化,
\[\begin{array}{*{c}}
{({\omega ^*},{b^*}) = \mathop {\arg \min }\limits_{\omega ,b} \sum\limits_{i = 1}^m {{{\left( {f({x_i}) - {y_i}} \right)}^2}} }\\
{ = \mathop {\arg \min }\limits_{\omega ,b} \sum\limits_{i = 1}^m {{{\left( {{\omega ^T}{x_i} + b - {y_i}} \right)}^2}} }
\end{array}\]
均方誤差有非常好的幾何意義,對應了歐氏距離。基於均方誤差最小化來進行求解的方法成為“最小二乘法”。線上性迴歸中,最小二乘法就是試圖找到一條直線,使所有樣本到直線上的歐式距離之和最小。
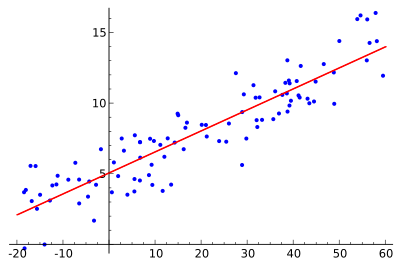
求解$\omega$和$b$使$E(\omega ,b) = \sum\limits_{i = 1}^m {{{\left( {{\omega ^T}{x_i} + b - {y_i}} \right)}^2}} $最小化的過程,稱之為線性迴歸模型的最小二乘“引數估計”。由於$E(\omega ,b) $是凸函式,令$\omega$和$b$的偏導為零,可以求其最優解的閉式解。
。。。待補充
更一般的情況,針對資料集$D = \{ ({{\bf{x}}_1},{y_1}),({{\bf{x}}_2},{y_2}),...,({{\bf{x}}_m},{y_m})\} $,其中${{\bf{x}}_i} = \{ {x_{i1}},{x_{i2}},...,{x_{id}}\} $,包含d維特徵。試圖學得$f({{\bf{x}}_i}) = {{\bf{\omega }}^T}{{\bf{x}}_i} + b$,使得$f({\bf{x}_i}) \simeq {y_i}$,這稱之為“多元線性迴歸”。類似用最小二乘法求得$\bf{\omega}$和$b$最優解的閉式解,但涉及矩陣逆計算,要複雜很多。
。。。待補充
線性迴歸模型的一般形式為:
\[y = {{\bf{\omega }}^T}{\bf{x}} + b\]
如果我們的資料是成指數變化的,那麼可以把線性迴歸模型擴充套件為:
\[\ln y = {{\bf{\omega }}^T}{\bf{x}} + b\]
更一般的,考慮單調可微函式$g(\bullet)$,將線性迴歸模型的預測值與真實標記聯絡起來,那麼線性迴歸模型擴充套件為:
\[y = {g^{ - 1}}({{\bf{\omega }}^T}{\bf{x}} + b)\]
2. logistic迴歸
那怎麼把線性迴歸模型擴充套件到分類模型中呢,找一個單調可微函式,將線性迴歸模型的預測值與真實類別聯絡起來。
考慮二分類問題,單位階躍函式是理想的分類函式,若預測值大於0則為{1}正類,小於0則為{0}負類,等於0則可任意判別。但是這樣的階躍函式不連續,不是可微的。因此我們利用對數機率函式(logistic function)來近似單位階躍函式。
\[y = \frac{1}{{1 + {e^{ - z}}}}\]
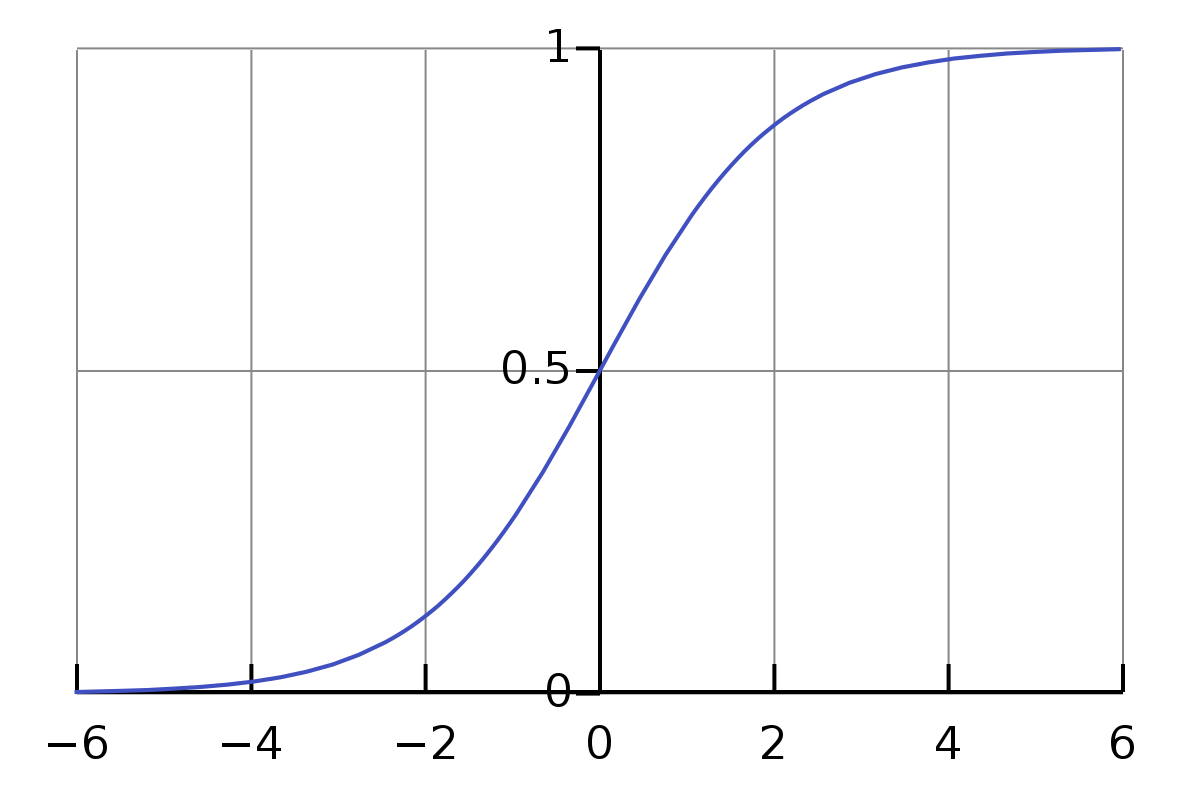
將z值轉化成一個接近於0或1的y值。
\[\ln \frac{y}{{1 - y}} = {{\bf{\omega }}^T}{\bf{x}} + b\]
\[\ln \frac{{p(y = 1|x)}}{{p(y = 0|x)}} = {{\bf{\omega }}^T}{\bf{x}} + b\]
該模型是在用線性迴歸模型的預測值去逼近真實標記的對數($\ln$)機率($\frac{y}{1 + y}$),其對應的模型成為“logistic迴歸”。
視y為類後驗概率估計$p(y=1|x)$,有:
\[y = p(y = 1|x) = \frac{1}{{1 + {e^{ - {{\bf{\omega }}^T}{\bf{x}} - b}}}}\]
\[y = p(y = 1|x) = \frac{1}{{1 + {e^{ {{\bf{\omega }}^T}{\bf{x}} + b}}}}\]
極大似然估計的思想為:對於所有的抽樣樣本,使它們聯合概率達到最大的係數便是統計模型最優的係數。
給定資料集D,logistic迴歸模型最大化“對數似然”
\[l({\bf{w}},b) = \sum\limits_{i = 1}^m {\ln p({y_i}|{{\bf{x}}_i};{\bf{w}},b)} \]
為了便於討論,令$\bf{\beta}= ({\bf{w}};b)$,$\widehat{\bf{x}}= (\bf{x};1)$,對數似然等價為最小化
\[l({\bf{\beta }}) = \sum\limits_{i = 1}^m {( - {y_i}{{\bf{\beta }}^T}{{\widehat {\bf{x}}}_i} + \ln (1 + {e^{{{\bf{\beta }}^T}{{\widehat {\bf{x}}}_i}}}))} \]
可根據經典數值優化演算法如梯度下降法等求得其$\bf{\beta }$的最優解,
\[{{\bf{\beta }}^*} = \mathop {\arg \min }\limits_{\bf{\beta }} l({\bf{\beta }})\]
logistic迴歸演算法
輸入:訓練集$D = \{ ({{\bf{x}}_1},{y_1}),({{\bf{x}}_2},{y_2}),...,({{\bf{x}}_m},{y_m})\} $;
學習率$\alpha$;
終止條件$\varepsilon$.
過程:
1:令$\bf{\beta}= ({\bf{w}};b)$,$\widehat{\bf{x}}= (\bf{x};1)$
2:針對$l({\bf{\beta }}) = \sum\limits_{i = 1}^m {( - {y_i}{{\bf{\beta }}^T}{{\widehat {\bf{x}}}_i} + \ln (1 + {e^{{{\bf{\beta }}^T}{{\widehat {\bf{x}}}_i}}}))} $
利用隨機梯度下降法求最優解${{\bf{\beta }}^*} = \mathop {\arg \min }\limits_{\bf{\beta }} l({\bf{\beta }})$
3:初始化$\bf{\beta}_0$
4:repeat
5:從訓練集D中隨機挑選一個數據${\bf{x}_i}, y_i$
6:以學習率$\alpha$的速度朝梯度下降的方向更新引數$\bf{\beta}$
7:end for
8:until $\Delta {\bf{\beta }} \le \varepsilon $
輸出:logistic迴歸模型引數$\bf{w},b$
參考:
機器學習西瓜書 周志華