
機器學習演算法原理解析——整合
1. 整合學習(Ensemble learning)
基本思想:讓機器學習效果更好,如果單個分類器表現的很好,那麼為什麼不適用多個分類器呢?
通過整合學習可以提高整體的泛化能力,但是這種提高是有條件的:
- (1)分類器之間應該有差異性;
- (2)每個分類器的精度必須大於0.5;
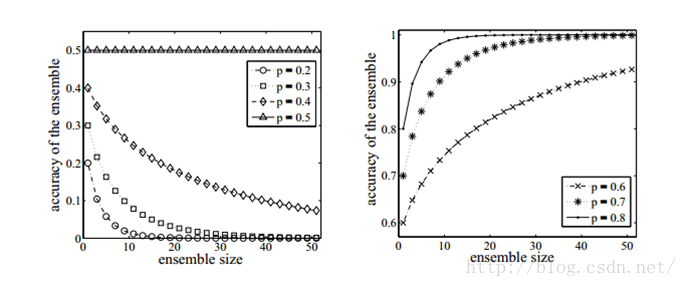
如果使用的分類器沒有差異,那麼整合起來的分類結果是沒有變化的。如下圖所示,分類器的精度p<0.5,隨著整合規模的增加,分類精度不斷下降;如果精度大於p>0.5,那麼最終分類精度可以趨向於1.
接下來需要解決的問題是如何獲取多個獨立的分類器呢?
我們首先想到的是用不同的機器學習演算法訓練模型,比如決策樹、KNN、神經網路、梯度下降、貝葉斯等等,但是這些分類器並不是獨立的,它們會犯相同的錯誤,因為許多分類器是線性模型,它們最終的投票不會改進模型的預測結果。
既然不同的分類器不適用,那麼可以嘗試將資料分成幾部分,每個部分的資料訓練一個模型。這樣做的優點是不容易出現過擬合,缺點是資料量不足導致訓練出來的模型泛化能力較差。
下面介紹三種比較實用的方法Bagging、Boosting和Stacking。
- 分類器間存在強依賴關係,必須序列生成的序列化方法,代表為Boosting;
- 分類器間不存在強依賴關係,可同時生成的並行化方法,代表為Bagging;
1.1 Bagging演算法(自舉匯聚法)
1.1.1 概述
全稱:boostrap aggregation(說白了就是並行訓練一堆分類器)
簡述:訓練多個分類器取平均
![]()
Bagging是通過組合隨機生成的訓練集而改進分類的整合演算法,是並行式整合學習最著名的代表。
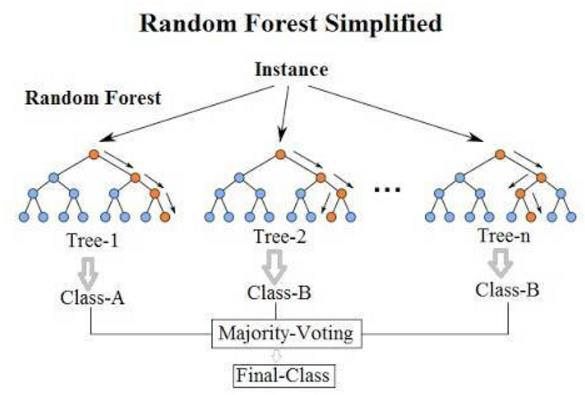
Bagging演算法最典型的代表就是隨機森林,如下圖所示。隨機森林,隨機指資料取樣隨機、特徵選擇隨機,森林指:很多個決策樹並行放在一起。
Bagging基本流程:
- 取樣出T個含m個訓練樣本的取樣集Tree-n(n=1、2、3...n),採用自助取樣法:給定包含m個樣本的資料集Tree-n(n=1、2、3...n),我們先隨機取出一個樣本放入取樣集中,再把該樣本放回初始資料集,使得下次取樣時該樣本仍有可能被選中,這樣經過m次隨機取樣操作,我們得到含有m個樣本的取樣集,初始樣本集有的樣本在取樣集裡面出現多次,有的則從未出現。初始訓練集中約有63.2%的樣本出現在取樣集中。重複操作,得到T個含m個訓練樣本的取樣集Tree-n(n=1、2、3...n);
- 基於每個取樣集Tree-n(n=1、2、3...n)訓練出一個基學習器Class-n(n=1、2、3、4...n);
- 將這些基學習器進行結合(分類任務使用簡單投票,迴歸任務使用簡單平均法)。
1.1.2 隨機森林優勢
- 它能夠處理很高緯度(feature很多)的資料,並且不用做特徵選擇;
- 在訓練完後,它能夠給出哪些feature比較重要;
- 容易做成並行化方法,速度比較快;
- 可以進行視覺化展示,便於分析。
1.1.3 模型
- KNN模型:KNN就不太適合,因為很難去隨機讓泛化能力變強!
- 樹模型:理論上越多的樹效果會越好,但實際上基本超過一定數量就差不多上下浮動了。
1.2 Boosting演算法(提升法)
簡述:從弱學習期開始加強,通過加權來進行訓練
![]()
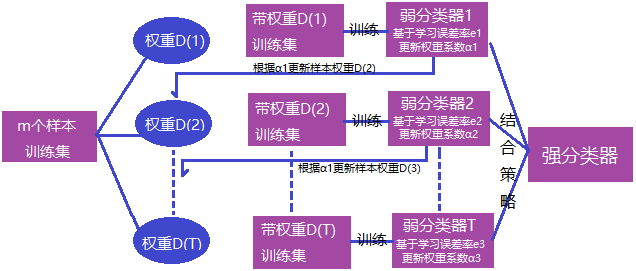
Boosting演算法是一種可將弱學習演算法提升成強學習器的演算法。基本思想:不同的訓練集是通過調整每個樣本對應的權重實現的,不同的權重對應不同的樣本分佈,而這個權重為分類器不斷增加對錯分樣本的重視程度。
Boosting演算法的工作機制類似:
- 首先賦予每個訓練樣本相同的初始化權重,在此訓練樣本分佈下訓練出一個弱分類器;
- 利用該弱分類器的表現對每個訓練樣本的權重進行調整,分類錯誤的樣本認為是分類困難樣本,權重增加,反之權重降低,得到一個新的樣本分佈;
- 基於調整後的新樣本分佈下再訓練一個新的弱分類器,並且更新樣本權重,重複以上過程T次,得到T個弱分類器,最終將這T個弱分類器進行加權結合。
Boosting演算法原理圖:
Boosting演算法典型代表:AdaBoost、Xgboost。AdaBoost演算法特點如下:
- 每次迭代改變的是訓練樣本的分佈,而不是重複取樣;
- 樣本分佈的改變取決於樣本是否被正確分類,是分類正確的樣本權值低,還是分類錯誤的樣本權值高(通常是邊界附近的樣本);
- 最終的結果是弱分類器(基分類器)的加權組合,權值表示該弱分類器的效能;
下面我們舉一個簡單的例子來看看AdaBoost的實現過程:
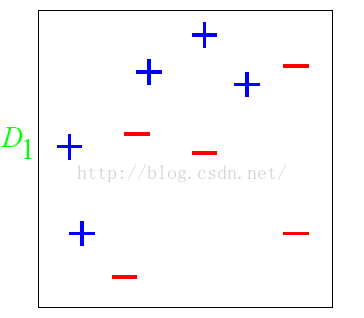
圖中,“+”和“-”分別表示兩種類別,在這個過程中,使用水平或者垂直的直線作為分類器。
第一步:根據分類的正確率,得到一個新的樣本分佈D2,一個子分類器h1,其中畫圈的樣本表示被分錯的,在右邊的圖中,比較大的“+”表示對該樣本做了加權;

圖中的ε1=0.3,表示的是錯誤率;α1=0.42,表示該分類器的權重,α1=1/2*ln(1- ε1/ ε1)
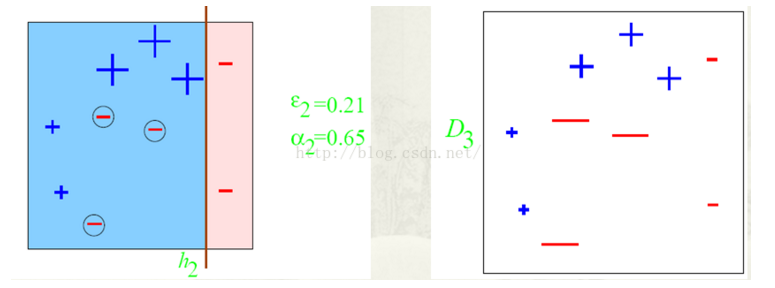
第二步:根據分類正確率,得到一個新的樣本分佈D3,一個子分類器h2;
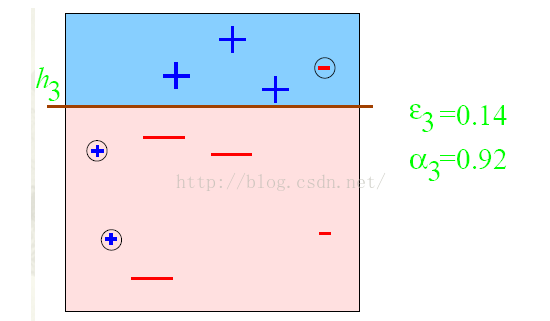
第三步:得到一個子分類器h3;
第四步:整合所有的子分類器;
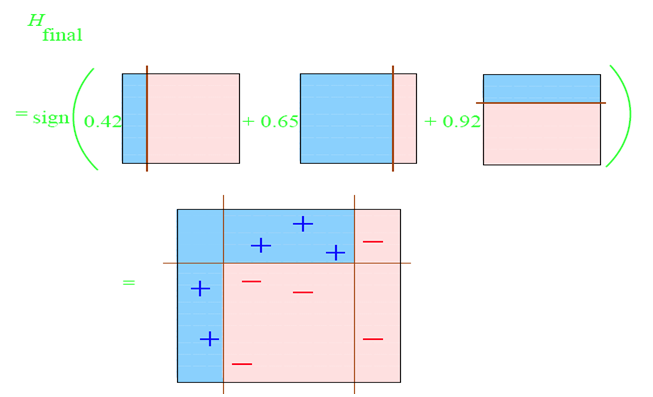
因此,可以得到整合的結果,從結果中看,即使簡單的分類器,組合起來也能獲得很好的分類效果。
AdaBoost演算法的兩個特性:(1)訓練錯誤率的上界,隨著迭代次數的增加,會逐漸下降;(2)即使訓練次數很多,也不會出現過擬合現象
AdaBoost的演算法流程如下:
步驟1. 首先,初始化資料的權值分佈,每一個訓練樣本最開始時都被賦予相同的權值:1/N
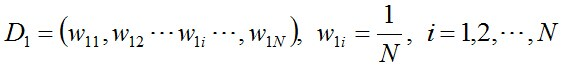
步驟2. 進行多輪迭代,用m=1,2,...M表示迭代的第多少輪
(a) 使用具有權值分佈Dm的訓練資料集學習,得到基本分類器(選取讓誤差率最低的閥值來設計基本分類器):
![]()
(b) 計算Gm(x)在訓練資料集上的分類誤差率
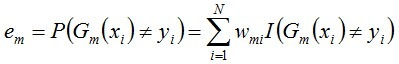
由上述式子可知,Gm(x)在訓練資料集上的分類誤差率em就是被Gm(x)誤分類樣本的權值之和。
(c) 計算Gm(x)的係數,am表示Gm(x)在最終分類器中重要程度(目的:得到基本分類器在最終分類器中所佔的比重):
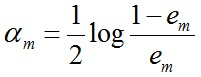
由上述式子可知,em<=1/2時,am>=0,且am隨著em的減小而增大,意味著分類誤差率越小的基本分類器在最終分類器中的作用越大。
(d) 更新訓練資料集的權值分佈(目的:得到樣本的新的權值分佈),用於下一輪迭代
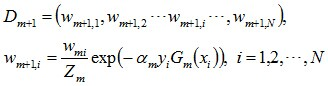
使得被基本分類器Gm(x)誤分類樣本的權值增大,而被正確分類樣本的權值減小。就這樣,通過這樣的方式,AdaBoost方法能“重點關注”或“聚焦”於那些較難分的樣本上。其中yi={+1,-1},Zm是規範化因子,使得Dm+1成為一個概率分佈。
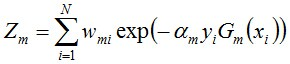
步驟3. 組合各個弱分類器
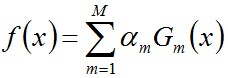
從而得到最終分類器,如下:
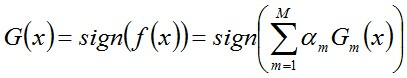
注:從偏差-方差分解的角度來看,Boosting主要關注降低偏差,因此Boosting能基於泛化能力相當弱的學習器構建出很強的整合。
1.3 Stacking演算法(瞭解即可)
簡述:聚合多個分類或迴歸模型(可以分階段來做)
堆疊:很暴力,拿來一堆直接上(各種分類器都來了),可以堆疊各種各樣的分類器(KNN,SVM,RF等等)
分階段:第一階段得出各自結果,第二階段再用前一階段結果訓練

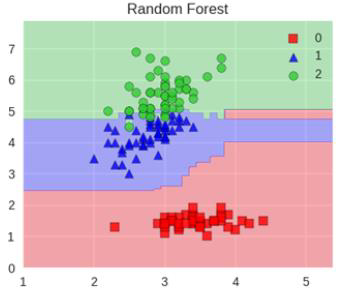
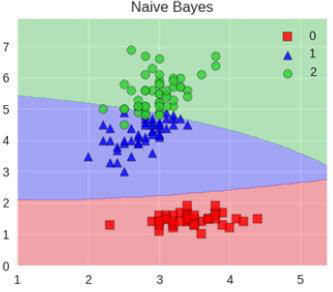
堆疊在一起確實能使得準確率提升,但是速度是個問題。
參考資料:
https://www.cnblogs.com/sddai/p/7647731.html
https://www.cnblogs.com/rgly/p/6519744.html