
Wannafly挑戰賽26 B-冥土追魂(列舉)
思路來源
優秀的組長噠噠噠
https://www.nowcoder.com/acm/contest/view-submission?submissionId=36142802
(紅名白膜法師%%%)(程式碼風格真的好,不得不服QAQ)
題解
第一個人選擇第i行,第二個人選擇這行最大的值,問第二個人的客觀收益是多少。
所以如果第二個人能取一行,第一個人就直接選和最小的行。
因為第二個人肯定是從這行最大的開始挑,以此類推。
挑完了之後只剩小的,此時再選這行,就限制了第二個人的收益。
在n*m的圖裡,選k個,
k/m是可以選完整的行的個數,但是k%m就不一定了。
事實上,我們能選k/m個完整的行,直接選那些全行sum最小的行就好了。
但很不幸,這個直接的思想,不完全正確。
比如,學長給了一個樣例
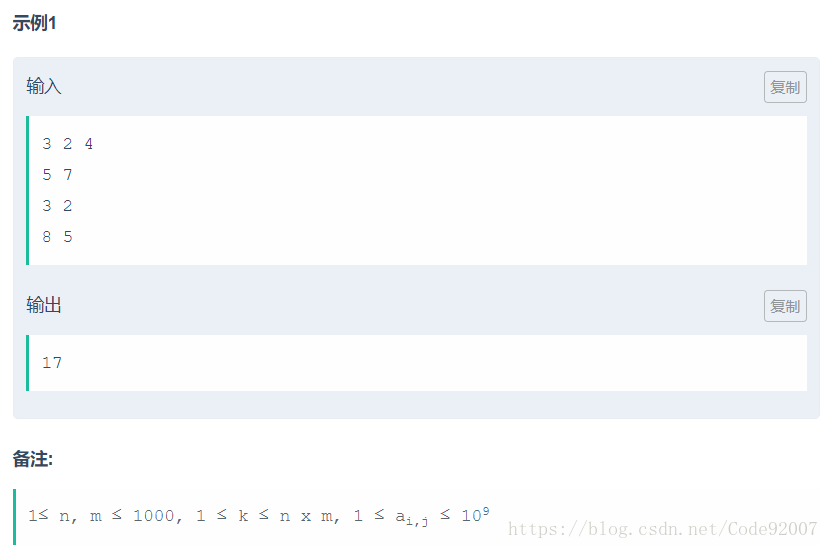
2 3 4 (n m k)
7 6 6
20 1 1
諸如此類,如果我們先選7 6 6這行,那麼就一定會選到20,總收益39。
所以應該選20 1 1這行,再選一個7,總收益29。
別多想了,列舉。
先列舉哪一行是餘數行,
這一行最大的k%m個,被選走,
再選擇剩下的k/m個和最小的行即可。
一點小證明
一行開始取之後,這行順著取全取完m個數,一定比不同行分著取湊齊m個數更優。
因為從大到小降序,後面取的越來越小,而別的行先取是取大的。
這裡舉一個例子,n=2,m=6,k=6。
a1 a2 a3 a4 a5 a6 降序
b1 b2 b3 b4 b5 b6 降序
且a1+a2+a3+a4+a5+a6<b1+b2+b3+b4+b5+b6
即我們選a這行比選b這行更優
我們可以發現,
a1 a2 a3 a4 a5 a6(1)
b1 b2 b3 b4 b5 b6(2)
若想取a1 b1 b2 b3 b4 b5,
則可以構造一個a1 b1 b2 b3 b4 b5(3)
若可取,應該有b6<a1,否則(1)最大值都比(2)小。
那我們取(3),不如取(2);
取(2),不如取(1)。
看不懂口胡的話,嚴謹證明一下,
現在取a1到a6最優,設存在至少一種方式比它更優
不妨取a1 b1 b2 b3 b4 b5,
則有a1+b1+b2+b3+b4+b5<a1+a2+a3+a4+a5+a6,
則b1+b2+b3+b4+b5+b6<a2+a3+a4+a5+a6+b6①,
以下分兩種情況,
若b6<=a1,則b1+b2+b3+b4+b5+b6<a1+a2+a3+a4+a5+a6,與a的和最小矛盾;
若b6>a1,b最小值比a最大值還要大,
從而有b1+b2+b3+b4+b5>a1+a2+a3+a4+a5>a2+a3+a4+a5+a6,
即a1+a2+a3+a4+a5+a6還是最小,
所以,不該取a1 b1 b2 b3 b4 b5
對任意一種構造方式,都有其對應構造證明。
因此,可以說明,一取應該取一行。
ans初始化0x7f7f7f7f才1e10 又為自己WA了幾發 原來8e18都不會越界
程式碼
#include <iostream>
#include <algorithm>
#include <cstring>
#include <cstdio>
#include <cmath>
#include <set>
#include <map>
#include <vector>
#include <stack>
#include <queue>
#include <functional>
const double INF=0x3f3f3f3f;
const int maxn=1e5+10;
const int mod=1e9+7;
const int MOD=998244353;
const double eps=1e-7;
typedef long long ll;
#define vi vector<int>
#define si set<int>
#define pli pair<ll,int>
#define pi acos(-1.0)
#define pb push_back
#define mp make_pair
#define lowbit(x) (x&(-x))
#define sci(x) scanf("%d",&(x))
#define scll(x) scanf("%lld",&(x))
#define sclf(x) scanf("%lf",&(x))
#define pri(x) printf("%d",(x))
#define rep(i,j,k) for(int i=j;i<=k;++i)
#define per(i,j,k) for(int i=j;i>=k;--i)
#define mem(a,b) memset(a,b,sizeof(a))
using namespace std;
int n,m,k;
ll a[1005],sum[1005][1005],ans,tmp;//第i行取到第幾個
struct node
{
ll sum;
int pos;
};
node q[1005];
bool cmp(node a,node b)
{
return a.sum<b.sum;
}
bool qaq(ll a,ll b)
{
return a>b;
}
int main()
{
ans=8e18;
//printf("%lld\n",ans);
scanf("%d%d%d",&n,&m,&k);
rep(i,0,n-1)
{
rep(j,0,m-1)scanf("%lld",&a[j]);
sort(a,a+m,qaq);
rep(j,0,m-1)
{
if(!j)sum[i][j]=a[j];
else sum[i][j]=sum[i][j-1]+a[j];
}
q[i].pos=i;
q[i].sum=sum[i][m-1];
}
sort(q,q+n,cmp);
int num=k/m;
if(k%m==0)
{
ans=0;
rep(j,0,num-1)ans+=q[j].sum;
}
else
{
rep(i,0,n-1)
{
int pos=i;
tmp=0;
rep(j,0,n-1)
{
if(pos==q[j].pos)
{
tmp+=sum[pos][k%m-1];
break;
}
}
int cnt=0;
rep(j,0,n-1)
{
if(pos==q[j].pos)continue;
tmp+=q[j].sum;cnt++;
if(cnt==num)break;
}
ans=min(ans,tmp);
}
}
printf("%lld\n",ans);
return 0;
}