
I/O模型介紹
I/O介紹
I/O:
網路IO:本質是socket讀取
磁碟IO:每次IO,都要經由兩個階段:
第一步:將資料從磁碟檔案先載入至核心記憶體空間(緩衝區),等待資料準
備完成,時間較長
第二步:將資料從核心緩衝區複製到使用者空間的程序的記憶體中,時間較短I/O模型
Linux下的五種I/O模型
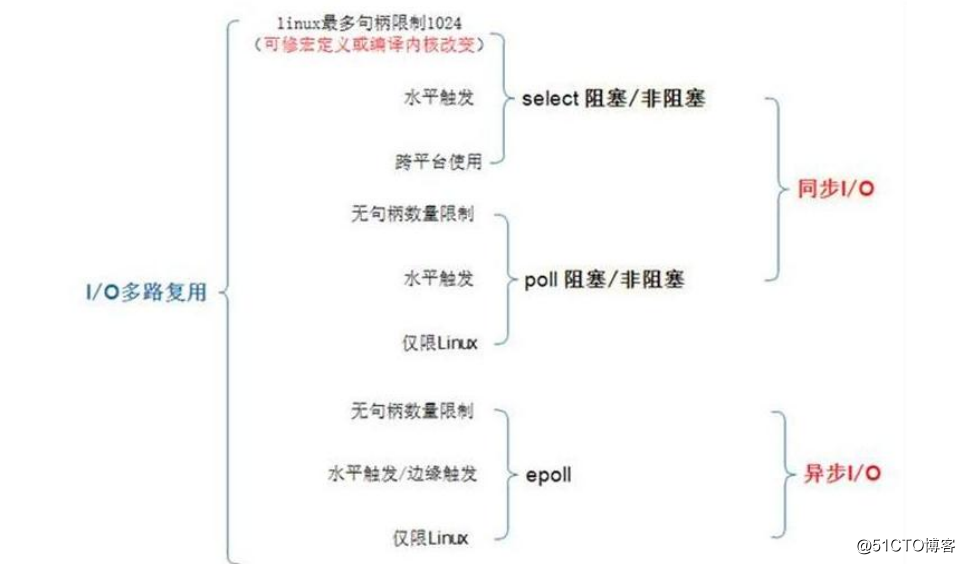
1)阻塞I/O(blocking I/O) 2)非阻塞I/O (nonblocking I/O) 3) I/O複用(select 和poll) (I/O multiplexing) 4)訊號驅動I/O (signal driven I/O (SIGIO)) 5)非同步I/O (asynchronous I/O (the POSIX aio_functions)) 前四種都是同步,只有最後一種才是非同步IO。
同步、非同步:
概念:訊息的通知機制
解釋:涉及到IO通知機制;所謂同步,就是發起呼叫後,被呼叫者處理訊息,必須等處理完才直接返回結果,沒處理完之前是不返回的,呼叫者主動等待結果;所謂非同步,就是發起呼叫後,被呼叫者直接返回,但是並沒有返回結果,等處理完訊息後,通過狀態、通知或者回調函式來通知呼叫者,呼叫者被動接收結果。阻塞、非阻塞:
概念:程式等待呼叫結果時的狀態 解釋:涉及到CPU執行緒排程;所謂阻塞,就是呼叫結果返回之前,該執行執行緒會被掛起,不釋放CPU執行權,執行緒不能做其它事情,只能等待,只有等到呼叫結果返回了,才能接著往下執行;所謂非阻塞,就是在沒有獲取呼叫結果時,不是一直等待,執行緒可以往下執行,如果是同步的,通過輪詢的方式檢查有沒有呼叫結果返回,如果是非同步的,會通知回撥。
經典故事案例:
人物:老張
道具:普通水壺(水燒開不響);響水壺(水燒開發出響聲)
案例:
1、同步阻塞:
老張在廚房用普通水壺燒水,一直在廚房等著(阻塞),盯到水燒開(同步);
2、非同步阻塞:
老張在廚房用響水壺燒水,一直在廚房中等著(阻塞),直到水壺發出響聲(非同步),老張知道水燒開了;
3、同步非阻塞:
老張在廚房用普通水壺燒水,在燒水過程中,就到客廳去看電視(非阻塞),然後時不時去廚房看看水燒開了沒 (輪詢檢查同步結果);
4、非同步非阻塞:
老張在廚房用響水壺燒水,在燒水過程中,就到客廳去看電視(非阻塞),當水壺發出響聲(非同步),老張就知道 水燒開了。
阻塞I/O模型:
簡介:程序會一直阻塞,直到資料拷貝完成
應用程式呼叫一個I/O函式,導致應用程式阻塞,等待資料準備好,如果資料沒有準備好,一直等待。。資料準備好,從核心拷貝到使用者空間,I/O函式返回成功。
阻塞I/O模型圖:在呼叫recv()/recvfrom()函式,發生在核心中等待資料和複製資料過程。 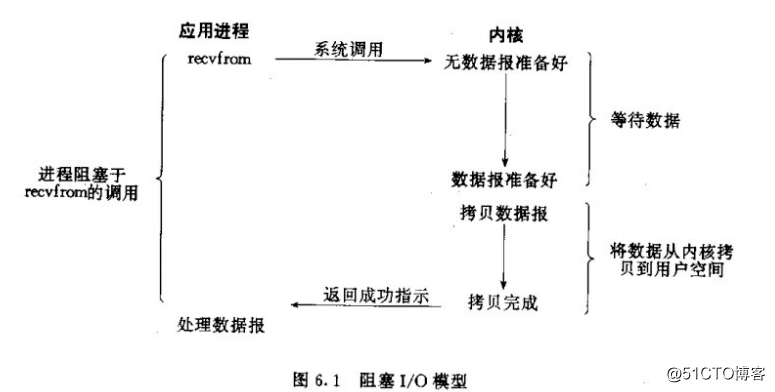
當呼叫recv()函式時,系統首先檢查是否有準備好的資料,如果資料沒有準備好,那麼系統就處於等待狀態,當資料準備好後,將資料從系統緩衝區複製到使用者空間,然後函式返回。在套接應用程式中,當呼叫recv()函式時,未必使用者空間就已經存在資料,那麼此時recv()函式處於等待狀態
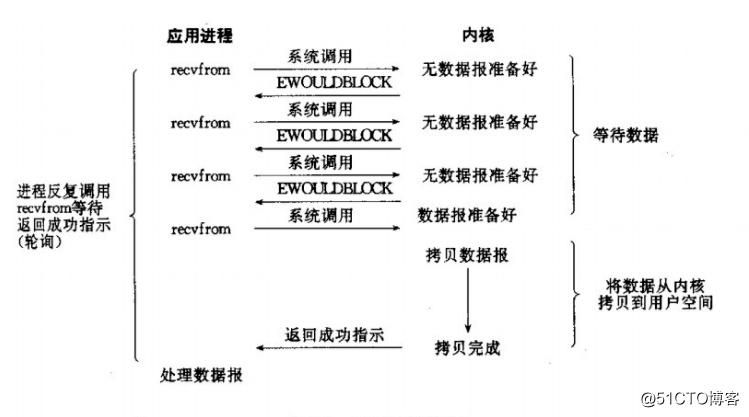
非阻塞I/O模型:
簡介:我們把一個套介面設定為非阻塞就是告訴記憶體,當所請求的I/O操作無法完成時,不要驚程序睡眠,而是返回一個錯誤,河陽I/O函式會不斷的測試資料是否準備好,沒有準備好,繼續測試,直到資料準備好為止。在測試的過程中會佔用大量的CPU時間。
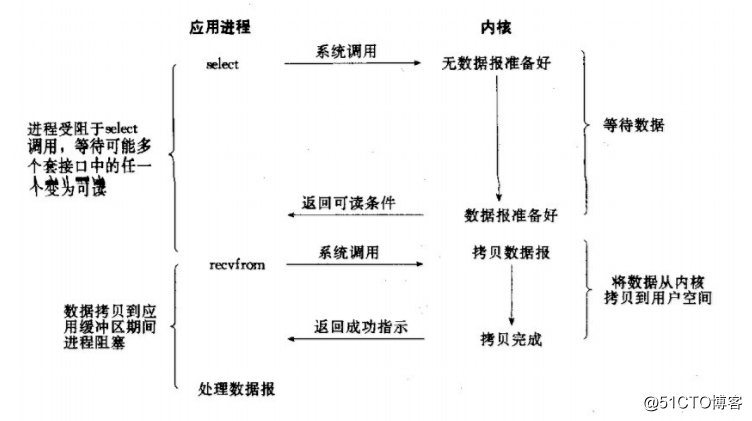
I/O複用模型:
inux提供select/poll,程序通過將一個或多個fd傳遞給select或poll系統呼叫,阻塞在select操作上,這樣,select/poll可以幫我們偵測多個fd是否處於就緒狀態。
select/poll是順序掃描fd是否就緒,而且支援的fd數量有限,因此它的使用受到了一些制約。
Linux還提供一個epoll系統呼叫,epoll使用基於事件驅動方式代替順序掃描,因此效能更高。當有fd就緒時,立即回撥函式rollback。
訊號驅動I/O
簡介:兩次呼叫,兩次返回
首先允許套介面進行訊號驅動I/O,並安裝一個訊號處理函式,程序繼續執行並不阻塞。昂資料準備好時,程序會收到一個SIGIO訊號,可以在訊號處理函式中呼叫I/O操作函式處理資料。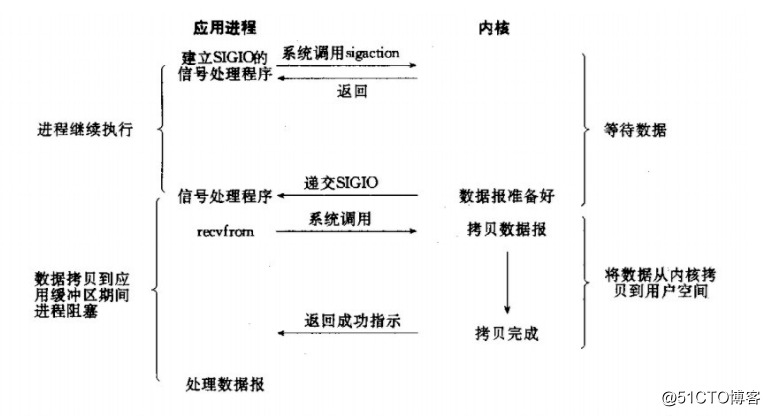
非同步I/O模型:
簡介:資料拷貝的時候程序無需阻塞
當一個非同步過程呼叫發出後,呼叫者不能立刻得到結果。實際處理這個呼叫的部件在完成後,通過狀態,通知和回撥通知呼叫者輸入輸出操作。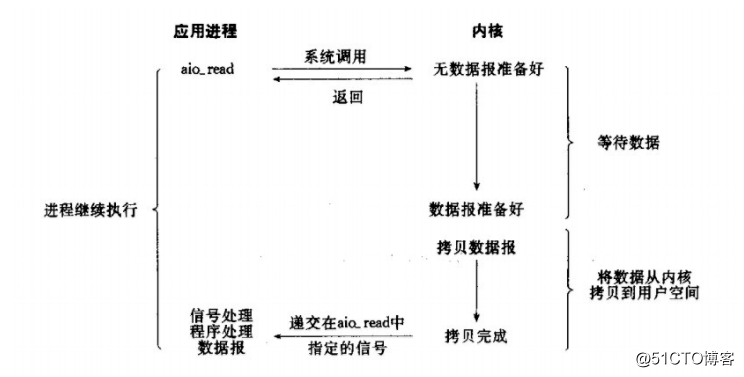
I/O多路複用技術
I/O程式設計中,需要處理多個客戶端接入請求時,可以利用多執行緒或者I/O多路複用技術進行處理。
正如前面的簡介,I/O多路複用技術通過把多個I/O的阻塞複用到同一個select的阻塞上,從而使得系統在單執行緒的情況下可以同時處理多個客戶端請求。
與傳統的多執行緒模型相比,I/O多路複用的最大優勢就是系統開銷小,系統不需要建立新的額外執行緒,也不需要維護這些執行緒的執行,降低了系統的維護工作量,節省了系統資源。
主要的應用場景:
伺服器需要同時處理多個處於監聽狀態或多個連線狀態的套接字。
伺服器需要同時處理多種網路協議的套接字。
支援I/O多路複用的系統呼叫主要有select、pselect、poll、epoll。
而當前推薦使用的是epoll,優勢如下:
支援一個程序開啟的socket fd不受限制。
I/O效率不會隨著fd數目的增加而線性下將。
使用mmap加速核心與使用者空間的訊息傳遞。
epoll擁有更加簡單的API。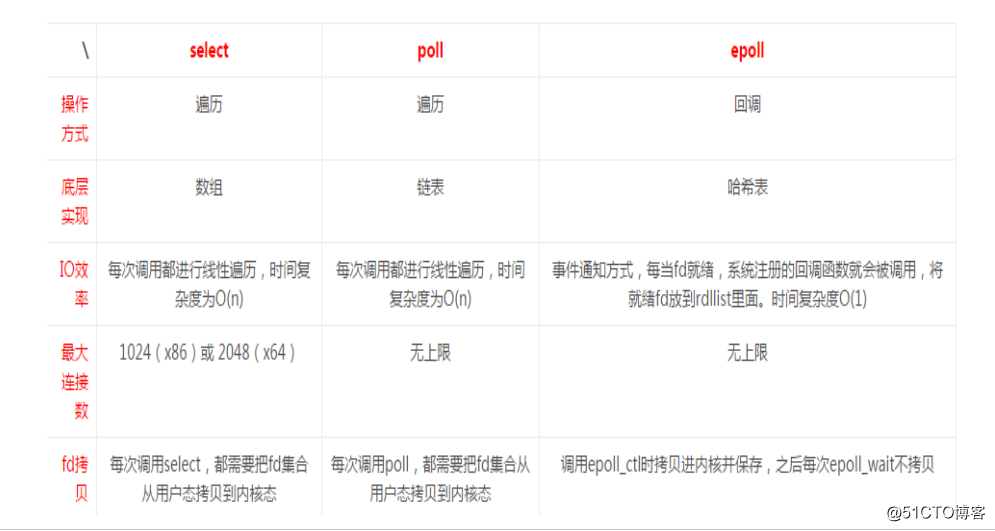
select/poll/epoll
Select:POSIX所規定,目前幾乎在所有的平臺上支援,其良好跨平臺支援也是它的一個優點,本質上是通過設定或者檢查存放fd標誌位的資料結構來進行下一步處理
缺點
1 單個程序能夠監視的檔案描述符的數量存在最大限制,在Linux上一般為1024,可以通過修改巨集定義FD_SETSIZE,再重新編譯核心實現,但是這樣也會造成效率的降低
2 單個程序可監視的fd數量被限制,預設是1024,修改此值需要重新編譯核心
3 對socket是線性掃描,即採用輪詢的方法,效率較低
4 select 採取了記憶體拷貝方法來實現核心將 FD 訊息通知給使用者空間,這樣一個用來存放大量fd的資料結構,這樣會使得使用者空間和核心空間在傳遞該結構時複製開銷大poll
1 本質上和select沒有區別,它將使用者傳入的陣列拷貝到核心空間,然後查詢每個fd對應的裝置狀態
2 其沒有最大連線數的限制,原因是它是基於連結串列來儲存的
3 大量的fd的陣列被整體複製於使用者態和核心地址空間之間,而不管這樣的複製是不是有意義
4 poll特點是“水平觸發”,如果報告了fd後,沒有被處理,那麼下次poll時會再次報告該fd
5 邊緣觸發:只通知一次epoll:
在Linux 2.6核心中提出的select和poll的增強版本
1 支援水平觸發LT和邊緣觸發ET,最大的特點在於邊緣觸發,它只告訴程序哪
些fd剛剛變為就需態,並且只會通知一次
2 使用“事件”的就緒通知方式,通過epoll_ctl註冊fd,一旦該fd就緒,核心
就會採用類似callback的回撥機制來啟用該fd,epoll_wait便可以收到通知優點:
1 沒有最大併發連線的限制:能開啟的FD的上限遠大於1024(1G的記憶體能監聽
約10萬個埠),具體檢視/proc/sys/fs/file-max,此值和系統記憶體大小相關
2 效率提升:非輪詢的方式,不會隨著FD數目的增加而效率下降;只有活躍可
用的FD才會呼叫callback函式,即epoll最大的優點就在於它只管理“活躍”
的連線,而跟連線總數無關
3 記憶體拷貝,利用mmap(Memory Mapping)加速與核心空間的訊息傳遞;即
epoll使用mmap減少複製開銷