
叢集間資料拷貝和Hadoop存檔對於小檔案處理
阿新 • • 發佈:2018-11-10
-
scp實現兩個遠端主機之間的檔案複製
scp -r hello.txt [email protected]:/user/atguigu/hello.txt // 推 push scp -r [email protected]:/user/atguigu/hello.txt hello.txt // 拉 pull scp -r [email protected]:/user/atguigu/hello.txt [email protected]:/user/atguigu //是通過本 地主機中轉實現兩個遠端主機的檔案複製;如果在兩個遠端主機之間 ssh 沒有配置的情況下 可以使用該方式。 -
使用discp命令實現兩個hadoop叢集之間的遞迴資料複製
[email protected] hadoop-2.7.2]$ bin/hadoop distcp hdfs://haoop102:9000/user/atguigu/hello.txt hdfs://hadoop103:9000/user/atguigu/hello.txt
Hadoop存檔
- hdfs儲存小檔案弊端
每個檔案均按照塊儲存,每個塊儲存在namenode的記憶體中,因此hadoop儲存小檔案會非常低效,因為大量的小檔案耗盡namenode中大部分記憶體,但是儲存小檔案所需要的磁碟容量和儲存這些檔案原始內容所需磁碟空間相對不會增加太多
例如:一個1Md的檔案大小按照128MB的塊儲存,實際使用的是1MB的磁碟空間,不是128MB
- 解決儲存小檔案的方法之一
Hadoop存到檔案或者HAR檔案,是一個更高效的檔案存檔工具**,它將檔案存入HDFS塊,**在較少namenode記憶體使用的同時.允許對檔案進行透明的訪問,具體:
Hadoop存檔檔案對內還是一個獨立檔案.對namenode而言.卻是一個整體,減少來了namenode的記憶體
實際就是小檔案合併,對於namenode是一個檔案
-
保證yarn程序的開啟
-
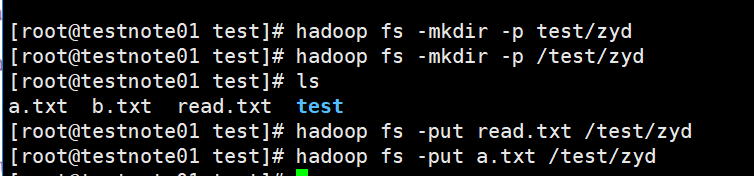
上傳幾個小檔案
3)歸檔檔案[[email protected]test]# hadoop archive -archiveName 116har.har -p /test/zyd /test
實際是一個mar程式

是一些索引


歸檔成一個叫做XXX.har的資料夾,該資料夾下有相應的資料檔案,Xx.har目錄是一個整體,該目錄看成一個歸檔的檔案即可
檢視歸檔
[[email protected] test]# hadoop fs -lsr /test/116har.har
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 3 root supergroup 0 2018-11-07 05:34 /test/116har.har/_SUCCESS
-rw-r--r-- 5 root supergroup 185 2018-11-07 05:34 /test/116har.har/_index
-rw-r--r-- 5 root supergroup 23 2018-11-07 05:34 /test/116har.har/_masterindex
-rw-r--r-- 3 root supergroup 6 2018-11-07 05:33 /test/116har.har/part-0
具體檢視
[[email protected] test]# hadoop fs -lsr har:///test/116har.har
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 3 root supergroup 6 2018-11-07 05:29 har:///test/116har.har/a.txt
-rw-r--r-- 3 root supergroup 0 2018-11-07 05:29 har:///test/116har.har/read.txt
解歸檔檔案
hadoop fs -cp har:///test/116har.har/read.txt /
相當於一個har:// 的歸檔協議