
人臉性別和年齡識別
阿新 • • 發佈:2018-11-10
本文是對age-gender-estimation專案的詳細講解,它給出了使用keras進行性別和年齡識別的完整流程。
資料
採用的資料集為imdb-wiki,這是一個包含 20,284名人的460,723張以及維基百科上imdb的 62,328張共計523,051 張人臉影象的資料集,是目前開源的資料集中量級最大的,它給出了影象中人物的性別和出生時間、照片的拍攝時間等資訊。原始的圖片很大,分成了9個部分共計100多G,而裁剪出人臉的圖片比較小,只有3G多,因此大家使用的基本都是wiki.tar.gz,不需要註冊,直接就可以下載,這點很良心,省去了很多下載話費的時間。
解壓後的目錄為100個子資料夾,每個子資料夾再儲存圖片檔案。

不過由於是採用matlab的mat格式檔案儲存的,實際用起來還要做一些轉化。裡面還含有一些噪聲,比如性別標記為NAN,年齡算出來不對等,我寫了一些程式碼來對這些資訊進行過濾和統計
import os import numpy as np from scipy.io import loadmat from datetime import datetime from tqdm import tqdm import matplotlib.pyplot as plt def calc_age(taken, dob): birth = datetime.fromordinal(max(int(dob) - 366, 1)) # assume the photo was taken in the middle of the year if birth.month < 7: return taken - birth.year else: return taken - birth.year - 1 def get_meta(mat_path, db): meta = loadmat(mat_path) full_path = meta[db][0, 0]["full_path"][0] dob = meta[db][0, 0]["dob"][0] # Matlab serial date number gender = meta[db][0, 0]["gender"][0] photo_taken = meta[db][0, 0]["photo_taken"][0] # year face_score = meta[db][0, 0]["face_score"][0] second_face_score = meta[db][0, 0]["second_face_score"][0] age = [calc_age(photo_taken[i], dob[i]) for i in range(len(dob))] return full_path, dob, gender, photo_taken, face_score, second_face_score, age def load_data(mat_path): d = loadmat(mat_path) return d["image"], d["gender"][0], d["age"][0], d["db"][0], d["img_size"][0, 0], d["min_score"][0, 0] def convert2txt(mat_path="imdb.mat",db="imdb"): lines=[] min_score=1.0 full_path, dob, gender, photo_taken, face_score, second_face_score, age = get_meta(mat_path,db) genders=[0,0] ages=[] for i in range(101): ages.append(0) for i in tqdm(range(len(full_path))): #if face_score[i] < min_score: #continue #if (~np.isnan(second_face_score[i])) and second_face_score[i] > 0.0: #continue if ~(0 <= age[i] <= 100): continue if np.isnan(gender[i]): continue g=int(gender[i]) genders[g]+=1 ag=int(age[i]) ages[ag]+=1 #print(i,gender[i],age[i]) line=full_path[i][0]+" "+str(g)+" "+str(ag) lines.append(line) with open("gt.txt","w")as f: for line in lines: f.write(line+"\n") print("genders",genders[0],genders[1]) print("age:") for i in range(101): print(i,ages[i]) plt.plot(np.linspace(0, 101,101),ages) plt.savefig("plot.png") plt.show() if __name__=="__main__": convert2txt()
結果如下:
性別比(男:女)=188746:262834
年齡分佈:
0 29 1 149 2 165 3 50 4 77 5 221 6 237 7 440 8 590 9 873 10 1071 11 1705 12 1736 13 2337 14 2114 15 2727 16 2856 17 3391 18 4122 19 5563 20 7784 21 8294 22 8769 23 9813 24 11478 25 12151 26 13299 27 12937 28 13778 29 14600 30 16356 31 16255 32 15374 33 15096 34 14704 35 15056 36 15139 37 14063 38 14417 39 13729 40 11068 41 11831 42 10501 43 10160 44 8917 45 10238 46 8200 47 7151 48 6688 49 6117 50 5783 51 5485 52 4816 53 4148 54 4211 55 3482 56 3096 57 3057 58 3290 59 3267 60 2709 61 2324 62 2129 63 2318 64 1889 65 1883 66 1273 67 1395 68 1147 69 1256 70 1052 71 926 72 809 73 701 74 585 75 590 76 593 77 490 78 362 79 467 80 267 81 250 82 196 83 164 84 196 85 121 86 70 87 111 88 72 89 31 90 69 91 13 92 17 93 15 94 9 95 6 96 12 97 3 98 4 99 2 100 3
畫成圖如下:
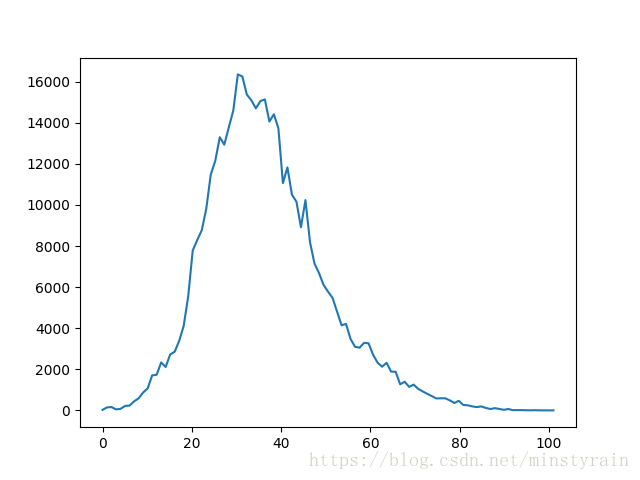
不難看出30-50歲之間的圖片最多 ,這也是主流的分佈。
具體到age-gender-estimation專案,可以簡單的通過
./download.sh下載,然後使用
python3 create_db.py --output data/imdb_db.mat --db imdb --img_size 64
將資料集轉換為需要的格式,這個格式主要是清理無效標籤,省的每次都再重複做,程式碼和我上面給出的差不多,不再贅述。
模型
使用的模型為WiderResnet
通過Netron可視化出來是

可以看出是由6個殘差模型拼起來的,不過輸出部分有兩個輸出,一個是性別的2,另一個是年齡的101
訓練
訓練部分也比較簡單,生成了資料檔案後直接使用
python3 train.py --input data/imdb_db.mat就可以了,如果還想使用資料增強,可以加上--aug
python3 train.py --input data/imdb_db.mat --augdemo
想看訓練好的效果可以執行
python3 demo.py