Pandas讀取excel資料——pearson相關性分析
阿新 • • 發佈:2018-11-11
利用Pandas和tushare進行一個簡單的資料讀取和分析
一丶Pandas的DataFrame操作方法
一個表格型資料,提供列名和不同的值,以及索引值
通過下面程式碼記錄一些DataFrame的方法
from pandas import Series,DataFrame
#一個字典資料
data={'nike':['hello','world','baby','love'],
'year':[2000,1526,11616,123],
'name':['bob','lucy','amy','andy']}
#將字典/列表 資料轉化為DataFrame 二丶資料抽取和儲存分析
這裡用到了一個庫tushare,裡面有很多的資料,連結地址為:
http://tushare.org/trading.html
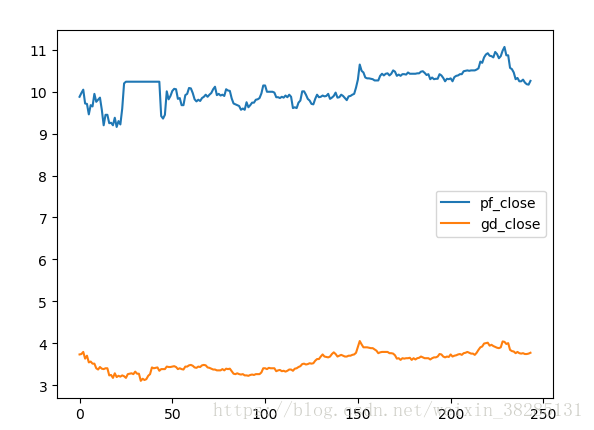
我們從這裡面抽取了浦發銀行和廣大銀行的資料,然後儲存和分析其相關性
import matplotlib.pyplot as plt
import numpy as np
import tushare as ts
from pandas import DataFrame,Series
s_pf='600000'#浦發銀行股票程式碼
s_gd='601818'#光大銀行股票程式碼
sdate='2017-01-01'#資料獲取開始日期
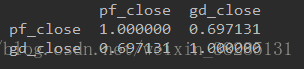
edate='2017-12-31'#資料獲取結束日期 輸出結果:
相關性接近0.7