
Spark學習之Spark Shuffle
阿新 • • 發佈:2018-11-11
文章目錄
一、什麼是Spark Shuffle?
1、Shuffle中文意思就是“洗牌”,在Spark中Shuffle的目的是為了保證每一個key所對應的value都會匯聚到同一個節點上去處理和聚合。
2、在Spark中,什麼情況下會發生shuffle?
reduceByKey、groupByKey、sortByKey、countByKey、join等操作。
3、Spark中的Shuffle包括兩種:
- HashShuffle
- SortShuffle
二、HashShuffle執行原理
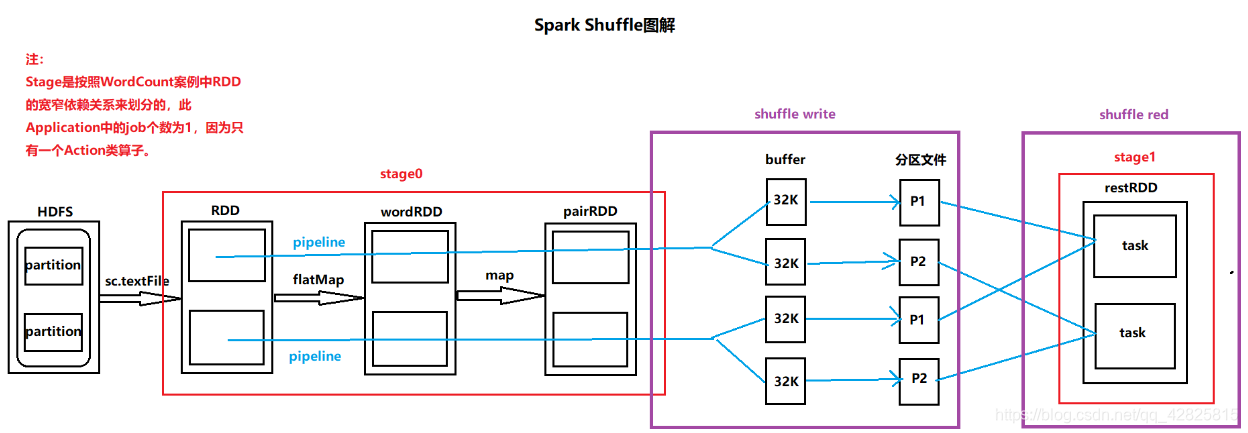
Shuffle Write階段:
由於Stage後面緊跟了另一個Stage,所以資料落地會發生在Shuffle Write階段。為了將分割槽中資料相同的key寫入一個分割槽檔案中,需要將task計算結果的key的hashcode值與Reduce task個數取模,從而確定將結果寫入哪個分割槽檔案中,這樣即可保證相同的key在一個分割槽檔案中。為了加快向磁碟寫檔案的速度,需要事先設定一個buffer作為快取,每個buffer的大小是32K。
Shuffle Red階段:
Reduce task從上個Stage的task節點中拉取屬於自己的分割槽檔案,這樣即可保證每一個Key所對應的Value都會在同一個節點上。拉取的過程屬於現拉現用。
三、Shuffle可能面臨的問題?
由上圖可知:磁碟小檔案(分割槽檔案)的個數=m(map task num)*r(reduce task num)
當磁碟小檔案過多時,帶來的問題有:
- write階段會建立大量寫檔案的物件
- read階段拉取資料需要進行多次網路傳輸
- read階段會建立大量讀檔案的物件
- 讀寫物件過多造成JVM記憶體不足,從而導致記憶體溢位
為了解決磁碟小檔案過多,Spark中推出了合併機制來減少磁碟小檔案。
合併機制:
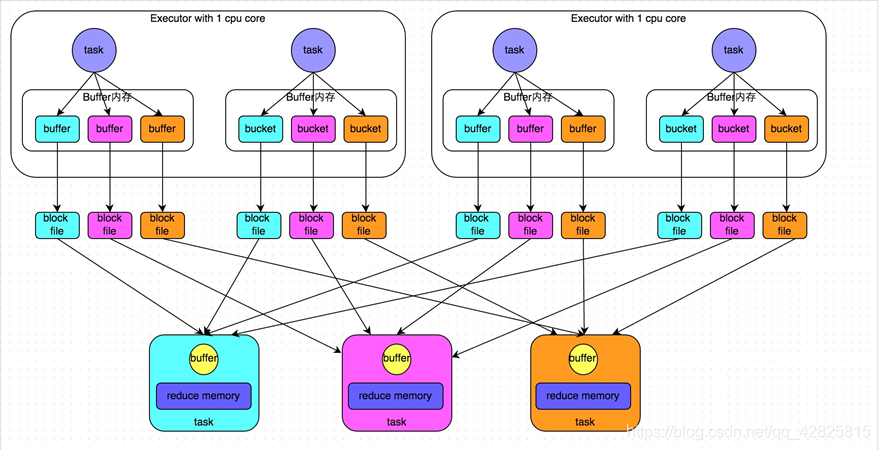
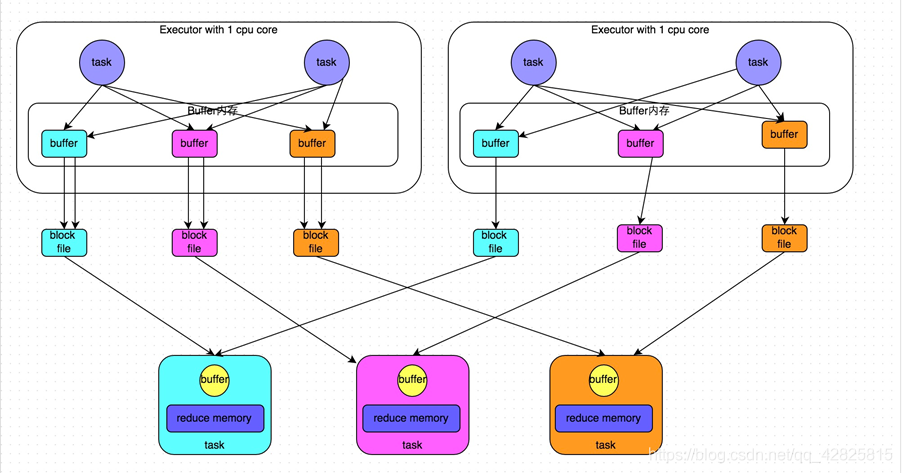
倘若Executor只有一個core,所以每次只能有一個task執行,當第一個task執行完成後,第二個task會複用第一個task所建立的buffer和磁碟檔案,從而減少磁碟檔案的個數。
合併前:
合併後:
四、如何優化解決問題?
五、SortShuffle執行原理
未完待續。。。