
Spark任務排程
一、spark任務排程知識點
1、Spark中的一些專業術語
1.1、任務相關
Application:使用者寫的應用程式(DriverProgram +ExecutorProgram)。
Job:一個action類運算元觸發的操作。
stage:一組任務,例如:map task。
task:(thread)在叢集執行時,最小的執行單元。
1.2、資源相關
Mstaer:資源管理主節點。
Worker:資源管理從節點。
Executor:執行任務的程序。
ThreadPool:執行緒池(存在於Executor程序中)
2、RDD的依賴關係
2.1、窄依賴
父RDD與子RDD,partition之間的關係是一對一,這種依賴關係不會有shuffle(父RDD不知道有幾個子RDD,但是子RDD一定知道他的父RDD)
2.2、寬依賴
父RDD與子RDD是一對多,一般都會導致shuffle。預設情況下,groupByKey返回的RDD的分割槽數與父RDD是一致的,如果再使用groupByKey的時候,傳入一個int型別的值,此時返回的RDD的分割槽數就是這個值
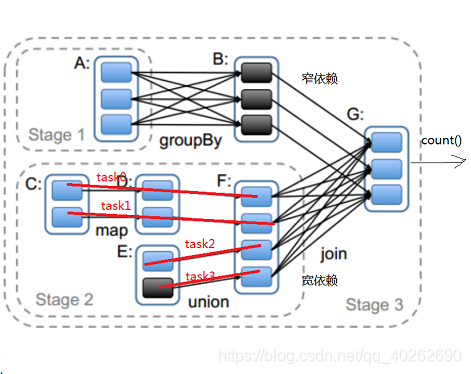
2.3、寬窄依賴的作用
將一個個job切割成一個個stage,stage與stage之間是寬依賴,stage內部是窄依賴
2.4、為什麼我們需要把job切割成stage?
答:把job切割成stage之後,stage內部就可以很容易的劃分出一個個的task任務(用一條線把task內部有關聯的子RDD與父RDD串聯起來),然後就可把task放到管道中運行了。
二、任務排程流程
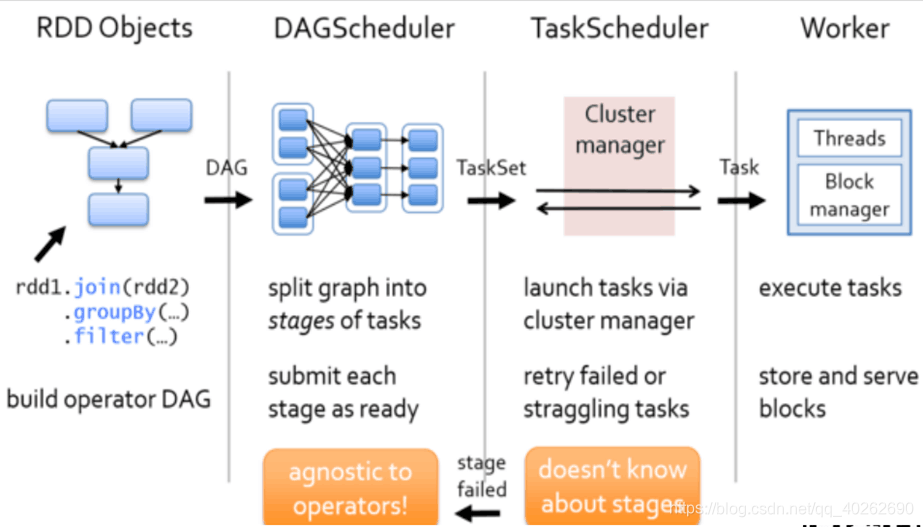
1、根據RDD的寬窄依賴關係將DAG有向無環圖切割成一個個stage將切割的stage封裝到TaskSet=stage 然後將一個個taskSet給taskSccheduler
2、taskScheduler拿到task以後,會遍歷整個集合,拿到每一個task然後去呼叫HDFS上的某一個方法,然後獲取資料的位置,依據資料的位置來分發task到worker節點的Executor程序中的執行緒池中執行
3、taskSchedule會實時跟蹤每一個task執行情況,若執行失敗ts會重試提交task,不會無休止重試,預設重試3次
4、重試3次仍然失敗,(每次重試提交的stage,已經成功執行 的不會再次分發到Executor程序執行,只是重試失敗的)那麼task所在的stage就失敗了,此時taskSchedule向DAGScheduler彙報,當前stage失敗,此時DS會重試提交stage(straggling task)
5、如果DS重試4次仍然失敗,那麼stage所在的job就失敗了,job失敗是不會進行重試的
三、問題思考
3.1、stage中的每一個task(管道計算模式)會在什麼時候落地磁碟?
1、如果stage後面是跟的是action類運算元
saveAsText:將每一個管道計算結果寫入到指定目錄。
collect:將每一個管道計算結果拉回到Driver端記憶體中。
count:將每一個管道計算結果,統計記錄數,返回給Driver。
2、如果stage後面是跟的是stage
在shuffle write階段會寫磁碟。(為什麼在shuffle write階段寫入磁碟?防止reduce task拉取檔案失敗,拉取失敗後可以直接在磁碟再次拉取shuffle後的資料)
3.2、Spark在計算的過程中,是不是特別消耗記憶體?
不是。Spark是在管道中計算的,而管道中不是特別耗記憶體。即使有很多管道同時進行,也不是特別耗記憶體。
3.3、什麼樣的場景最耗記憶體?
使用控制類運算元的時候耗記憶體,特別是使用cache時最耗記憶體。
3.4、如果管道中有cache邏輯,他是如何快取資料的?
有cache時,會在一個task執行成功時(遇到action類運算元時),將這個task的執行結果快取到記憶體中。
3.5、RDD(彈性分散式資料集),為什麼他不儲存資料還叫資料集?
雖然RDD不具備儲存資料的能力,但是他具備操作資料的能力。
3.6、如果有1T資料,單機執行需要30分鐘,但是使用Saprk計算需要兩個小時(4node),為什麼?
1、發生了計算傾斜。大量資料給少量的task計算。少量資料卻分配了大量的task。
2、開啟了推測執行機制。
解決方案:關閉推測執行,後期更新如何解決資料傾斜
3.7、掉隊(掙扎)任務?
大部分任務成功,部分未執行成功
TS遇到掙扎任務,他會重試,此時TS會重新提交一個掙扎的task一模一樣的task到叢集中執行,掙扎的task不會被kill掉,讓他倆在叢集中比賽執行,誰先執行完畢,以誰的結果為準(推測執行機制)
推測執行的標準 100ms 1.5 75%
可通過修改配置資訊配置
spark.task.maxFailures TS重試失敗的次數 預設3次
spark.stage.maxConsecutiveAttempts DS重試的次數 預設4次
spark.speculation.interval 100ms 推測執行機制
spark.speculation.multiplier 1.5
含義:每隔100ms計算一次叢集是否有掙扎的任務,100task,76task執行完畢,24個未執行完畢,計算這24個task的已經執行時間的中位數,然後將中位數*1.5=時間,拿到這個最終計算出來的時間,檢視哪一些task超時,那麼,此時的task就是掙扎的task
當所有的task的75%以上全部執行完畢,那麼才會每隔100ms計算
3.8、對於ETL(資料清洗流程)型別的資料,開啟推測執行、重試機制,對於最終的執行結果會不會有影響?
有影響,最終資料庫中會有重複資料。
解決方案:
1、關閉各種推測、重試機制。
2、設定一張事務表。