
pytorch系列 -- 9 pytorch nn.init 中實現的初始化函式 uniform, normal, const, Xavier, He initialization
本文內容:
1. Xavier 初始化
2. nn.init 中各種初始化函式
3. He 初始化
torch.init https://pytorch.org/docs/stable/nn.html#torch-nn-init
1. 均勻分佈
torch.nn.init.uniform_(tensor, a=0, b=1)
服從~
2. 正太分佈
torch.nn.init.normal_(tensor, mean=0, std=1)
服從~
3. 初始化為常數
torch.nn.init.constant_(tensor, val)
初始化整個矩陣為常數
val
4. Xavier
基本思想是通過網路層時,輸入和輸出的方差相同,包括前向傳播和後向傳播。具體看以下博文:
- 為什麼需要Xavier 初始化?
文章第一段通過sigmoid啟用函式講述了為何初始化?
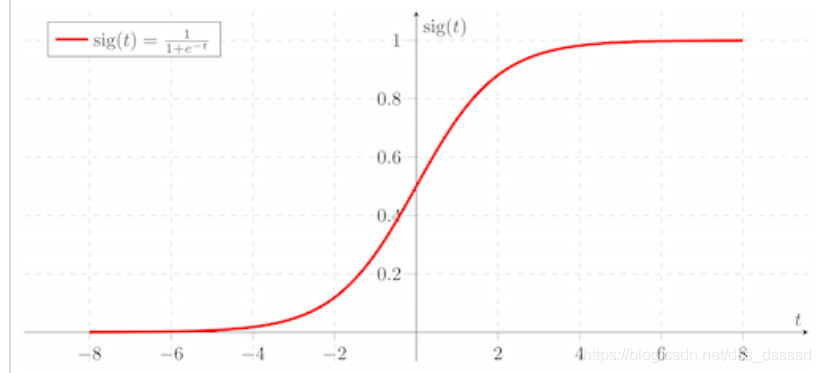
簡答的說就是:
- 如果初始化值很小,那麼隨著層數的傳遞,方差就會趨於0,此時輸入值 也變得越來越小,在sigmoid上就是在0附近,接近於線性,失去了非線性
- 如果初始值很大,那麼隨著層數的傳遞,方差會迅速增加,此時輸入值變得很大,而sigmoid在大輸入值寫倒數趨近於0,反向傳播時會遇到梯度消失的問題
其他的啟用函式同樣存在相同的問題。
https://prateekvjoshi.com/2016/03/29/understanding-xavier-initialization-in-deep-neural-networks/
所以論文提出,在每一層網路保證輸入和輸出的方差相同。
2. xavier初始化的簡單推導
https://blog.csdn.net/u011534057/article/details/51673458
對於Xavier初始化方式,pytorch提供了uniform和normal兩種:
torch.nn.init.xavier_uniform_(tensor, gain=1)均勻分佈 ~
其中, a的計算公式:torch.nn.init.xavier_normal_(tensor, gain=1)正態分佈~
其中std的計算公式:
5. kaiming (He initialization)
Xavier在tanh中表現的很好,但在Relu啟用函式中表現的很差,所何凱明提出了針對於Relu的初始化方法。
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification He, K. et al. (2015)
該方法基於He initialization,其簡單的思想是:
在ReLU網路中,假定每一層有一半的神經元被啟用,另一半為0,所以,要保持方差不變,只需要在 Xavier 的基礎上再除以2
也就是說在方差推到過程中,式子左側除以2.
pytorch也提供了兩個版本:
-
torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’), 均勻分佈 ~
其中,bound的計算公式:
-
torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’), 正態分佈~
其中,std的計算公式:
兩函式的引數:
-
a:該層後面一層的啟用函式中負的斜率(預設為ReLU,此時a=0) -
mode:‘fan_in’ (default) 或者 ‘fan_out’. 使用fan_in保持weights的方差在前向傳播中不變;使用fan_out保持weights的方差在反向傳播中不變
針對於Relu的啟用函式,基本使用He initialization,pytorch也是使用kaiming 初始化卷積層引數的