
資料分析之可反覆與獨立樣本的T-Test分析
阿新 • • 發佈:2018-11-17
資料分析之獨立樣本的T-Test分析
比較兩個獨立樣本資料之間是否有顯著性差異,將實驗資料與標準資料對照,檢視
實驗結果是否符合預期。T-Test在生物資料分析。實驗資料效果驗證中非經常見的數
據處理方法。http://www.statisticslectures.com/tables/ttable/ - T-table查詢表
獨立樣本T-test條件:
1. 每一個樣本相互獨立沒有影響
2. 樣本大致符合正態分佈曲線
3. 具有同方差異性
單側檢驗(one-tail Test)與雙側檢驗(Two-Tail Test)
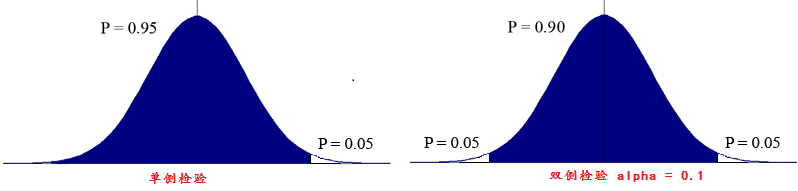
基本步驟:
1.雙側檢驗, 條件宣告 alpha值設定為0.05
依據t-table, alpha = 0.05, df = 38時, 對於t-table的值為2.0244
2. 計算自由度(Degree of Freedom)
Df = (樣本1的總數 + 樣本2的總數)- 2
3. 宣告決策規則
假設計算出來的結果t-value的結果大於2.0244或者小於-2.0244則拒絕
4. 計算T-test統計值
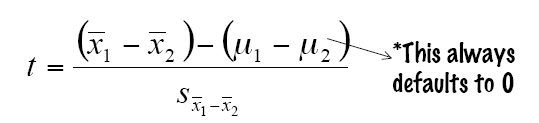
5. 得出結論
假設計算結果在雙側區間之內,說明兩組樣本之間沒有顯著差異。
可反覆樣本的T-Test計算
相同一組資料在不同的條件下得到結果進行比對,發現是否有顯著性差異,最常見
的對一個人在飲酒與不飲酒條件下駕駛車輛測試,非常easy得出酒精對駕駛員有顯著
影響
演算法實現:
對獨立樣本的T-Test計算最重要的是計算各自的方差與自由度df1與df2
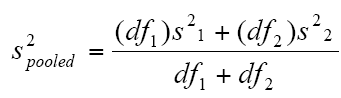
對可反覆樣本的對照t-test計算
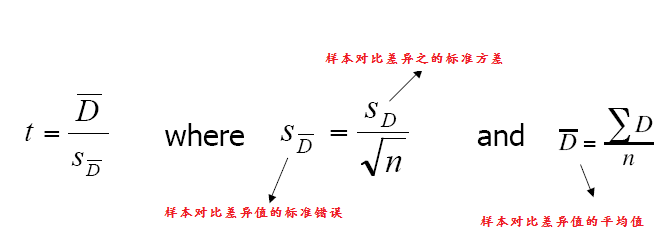
程式實現:
測試程式:package com.gloomyfish.data.mining.analysis; public class TTestAnalysisAlg { private double alpahValue = 0.05; // default private boolean dependency = false; // default public TTestAnalysisAlg() { System.out.println("t-test algorithm"); } public double getAlpahValue() { return alpahValue; } public void setAlpahValue(double alpahValue) { this.alpahValue = alpahValue; } public boolean isDependency() { return dependency; } public void setDependency(boolean dependency) { this.dependency = dependency; } public double analysis(double[] data1, double[] data2) { double tValue = 0; if (dependency) { // Repeated Measures T-test. // Uses the same sample of subjects measured on two different // occasions double diffSum = 0.0; double diffMean = 0.0; int size = Math.min(data1.length, data2.length); double[] diff = new double[size]; for(int i=0; i<size; i++) { diff[i] = data2[i] -data1[i]; diffSum += data2[i] -data1[i]; } diffMean = diffSum / size; diffSum = 0.0; for(int i=0; i<size; i++) { diffSum += Math.pow((diff[i] -diffMean), 2); } double diffSD = Math.sqrt(diffSum / (size - 1.0)); double diffSE = diffSD / Math.sqrt(size); tValue = diffMean / diffSE; } else { double means1 = 0; double means2 = 0; double sum1 = 0; double sum2 = 0; // calcuate means for (int i = 0; i < data1.length; i++) { sum1 += data1[i]; } for (int i = 0; i < data2.length; i++) { sum2 += data2[i]; } means1 = sum1 / data1.length; means2 = sum2 / data2.length; // calculate SD (Standard Deviation) sum1 = 0.0; sum2 = 0.0; for (int i = 0; i < data1.length; i++) { sum1 += Math.pow((means1 - data1[i]), 2); } for (int i = 0; i < data2.length; i++) { sum2 += Math.pow((means2 - data2[i]), 2); } double sd1 = Math.sqrt(sum1 / (data1.length - 1.0)); double sd2 = Math.sqrt(sum2 / (data2.length - 1.0)); // calculate SE (Standard Error) double se1 = sd1 / Math.sqrt(data1.length); double se2 = sd2 / Math.sqrt(data2.length); System.out.println("Data Sample one - > Means :" + means1 + " SD : " + sd1 + " SE : " + se1); System.out.println("Data Sample two - > Means :" + means2 + " SD : " + sd2 + " SE : " + se2); // degree of freedom double df1 = data1.length - 1; double df2 = data2.length - 1; // Calculate the estimated standard error of the difference double spooled2 = (sd1 * sd1 * df1 + sd2 * sd2 * df2) / (df1 + df2); double Sm12 = Math.sqrt((spooled2 / df1 + spooled2 / df2)); tValue = (means1 - means2) / Sm12; } System.out.println("t-test value : " + tValue); return tValue; } public static void main(String[] args) { int size = 10; System.out.println(Math.sqrt(size)); } }
package com.gloomyfish.dataming.study;
import com.gloomyfish.data.mining.analysis.TTestAnalysisAlg;
public class TTestDemo {
public static double[] data1 = new double[]{
35, 40, 12, 15, 21, 14, 46, 10, 28, 48, 16, 30, 32, 48, 31, 22, 12, 39, 19, 25
};
public static double[] data2 = new double[]{
2, 27, 38, 31, 1, 19, 1, 34, 3, 1, 2, 3, 2, 1, 2, 1, 3, 29, 37, 2
};
public static void main(String[] args)
{
TTestAnalysisAlg tTest = new TTestAnalysisAlg();
tTest.analysis(data1, data2);
tTest.setDependency(true);
double[] d1 = new double[]{2, 0, 4, 2, 3};
double[] d2 = new double[]{8, 4, 11, 5, 8};
// The critical value for a one-tailed t-test with
// df=4 and α=.05 is 2.132
double t = tTest.analysis(d1, d2);
if(t > 2.132 || t < -2.132)
{
System.err.println("Very Bad!!!!");
}
}
}