
Incremental Learning of Object Detectors without Catastrophic Forgetting詳解
Incremental Learning of Object Detectors without Catastrophic Forgetting詳解
最近由於專案的需要在研究incremental learning在目標檢測方面的應用,剛好讀到了INRIA在2007年的一篇paper,採用蒸餾loss的方法來做incremental learning的,所以寫這篇部落格記錄下來。
概述
不懂什麼叫incremental learning或者是catastrophic forgetting的可以參考知乎這個連結,王乃巖介紹的非常完善,自己也學到了不少。
CNN用於目標檢測任務的缺陷——類別遺忘:假設CNN模型A為在一個物體檢測訓練集1上訓練得到的效能較好的檢測器,現在有另外一個訓練集2,其中物體類別與1不同,使用訓練集2在A的基礎上進行fine-tune得到模型B,模型B在訓練集2中的類別上可以達到比較好的檢測結果,但是在訓練集1中的類別上檢測效能就會大幅度下降;
本文目的:緩解CNN用於目標檢測任務的類別遺忘,在訓練集1中原始圖片不可得以及新圖片中不包含訓練集1中存在的類別的標註的情況下,在訓練集2上fine-tune模型A得到模型B,可以同時在訓練集1和2中的類別上獲得較好的檢測效能;
本文核心:在fine-tune模型A得到模型B的過程中提出一個新的損失函式,用於同時考慮網路在新的類別上的預測效能以及原始類別在新模型B和舊模型A上的響應差異,LOSS=新類別檢測LOSS+舊類別在模型A和模型B上的差異LOSS。
方法的核心:平衡新類別預測(即交叉熵損失)與新的蒸餾損失之間的相互作用的損失函式,其將原始和新網路的舊類別的響應之間的差異最小化。
網路結構
作者也提出:解決這個新增分類的問題可以再模型A上增加對新類別的預測分支,隨即初始化該分支後,用新類別資料fine-tune這個分支,但是這樣做會導致一個問題,此時得到的網路對原來N個類別的檢測效能會大幅下降。所以作者提出了一種新的loss,既能夠檢測出新的類,同時也能保證在舊的類的檢測準確率不會下降。網路結構如下:

Network A:It contains a frozen copy of the original detector。作用:1)檢測原始類別的bbox;2)蒸餾proposals並計算蒸餾loss;
Network B:用於對新增分類B的網路,結合模型A最終可以預測出新的類和舊的類;
作者指出:選擇fast-rcnn而非選擇faster-rcnn,因為faster-rcnn中有RPN層,其對類別有一定的敏感性,因為RPN可被訓練且共享卷積,,不利於最後蒸餾loss的計算,所以作者選基於edgeboxes的fast-rcnn,因為其類別對proposal不敏感。
在作者的這個fast-rcnn中,將vgg16替換為resnet50,並在最後一層stride!= 1的卷積層前加入了RoI pooling層,然後在接上剩下的卷積層和兩層FC連線每個類別的得分輸出和迴歸輸出,使用該主幹網路訓練用於檢測類別集合1的模型A。
loss_cls層評估分類代價。由真實分類u對應的概率決定:
=−log
=−log
loss_bbox評估檢測框定位代價。比較真實分類對應的預測引數
和真實平移縮放參數為
的差別:
=
g(
−
)
g為Smooth L1誤差,對outlier不敏感:
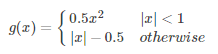
總代價為兩者加權和,如果分類為背景則不考慮定位代價:
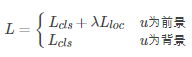
這個詳細的可以參考fast-rcnn原paper,這裡不詳說。
訓練方法
首先訓練一個fast-rcnn的網路結構使其能夠檢測原本的資料集
,這個網路結構記為A(
)。所以我們現在的目標是曾傑一個新的類資料集
。
我們對先前訓練得到的網路A(
)做兩份copies:一個凍結的網路通過蒸餾loss對原來的
進行檢測識別;另外一個B(
)被擴充用來檢測新的分類
(在元資料中未出現或未被標註)。我們建立一個新的FC層用來只對新的分類檢測,然後將其output和原來的的輸出做concat,即:根據新增加的類別數對網路A進行擴充套件,即增加全連線層的輸出個數,得到初始化的Network B網路。新的層是採用和先前的網路A一樣的初始化方式進行隨機初始化的。現在我們的目標就是:訓練一個網路能夠僅僅使用新的資料,最後能夠識別出新增分類和舊分類的網路。
作者指出蒸餾loss是為了“keeping all the answers of the network the same or as close as possible”。如果我們訓練網路B(
)不做蒸餾的話,這個網路的效能在原來的類上將會急劇下降,這就是所謂的catastrophic forgetting(災難性遺忘)。Even if no object is detected by A(CA), the unnormalized logits (softmax input) carry enough information to “distill” the knowledge of the old classes from A(
) to B(
).
細節
對於每一個訓練圖片,隨機從128個RoI中選取64的背景得分最低的RoI,並分別得到其通過模型A後在舊的類別集合上的得分和迴歸目標,同樣得到其在通過模型B後在舊的類別集合上的得分和迴歸目標。
Loss函式包括logits(即softmax的input)和迴歸的outputs:
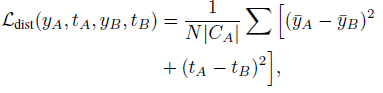
N:用於蒸餾的RoIs的數量(文章選的64)
|
|:原始資料的類別數
:bounding box regression outputs
蒸餾logits不使用任何的smoothing,因為大多數的proposals已經經歷了smoothing在分數的分佈上。在我們的試驗中,在初始階段,新的和舊的網路的引數基本一致,所以沒必要smoothing來穩定其訓練。
所以總的損失函式定義如下:
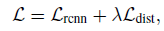
取樣策略
作者實驗發現:選擇非背景proposal進行蒸餾學習相比隨機選擇proposal進行蒸餾學習得到的網路更檢測效能更好。
其他的作者做的一些實驗本文就不在這裡敘述了。隨後獻上paper和作者的程式碼。