
案例學python——案例一:抓圖
阿新 • • 發佈:2018-11-17
最近專案不那麼緊張,有時間來研究一下Python,先前斷斷續續的自學了一段時間,有些淺基礎。剛好在碼雲上看到比較適合的案例,跟著案例再往前走一波。
案例一:爬蟲抓圖
開發工具:PyCharm 指令碼語言:Python 3.7.1 開發環境:Win10 爬取網站:妹子圖
# Win下直接裝的 python3 pip install bs4、pip install requests # Linux python2 python3 共存 pip3 install bs4、pip3 install requests
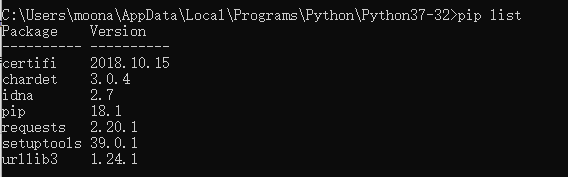
pip list 檢視庫
導庫說明
# 匯入requests庫 匯入目的:負責傳送網路請求 import requests # 匯入檔案操作庫OS 匯入目的:讀寫 import os # bs4全名BeautifulSoup,是編寫python爬蟲常用庫之一,主要用來解析html標籤。 效能據說可能差了點,入門級湊合著用吧。 import bs4 from bs4 import BeautifulSoup # 基礎類庫 import sys # Python 3.x 解決中文編碼問題 import importlib importlib.reload(sys)
先上原始碼:
#coding=utf-8 #!/usr/bin/python # 匯入requests庫 import requests # 匯入檔案操作庫 import os import bs4 from bs4 import BeautifulSoup import sys import importlib importlib.reload(sys) # 給請求指定一個請求頭來模擬chrome瀏覽器 global headers headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} # 爬圖地址 mziTu = 'http://www.mzitu.com/' # 定義儲存位置 global save_path save_path = 'G:\BeautifulPictures' # 建立資料夾 def createFile(file_path): if os.path.exists(file_path) is False: os.makedirs(file_path) # 切換路徑至上面建立的資料夾 os.chdir(file_path) # 下載檔案 def download(page_no, file_path): global headers res_sub = requests.get(page_no, headers=headers) # 解析html soup_sub = BeautifulSoup(res_sub.text, 'html.parser') # 獲取頁面的欄目地址 all_a = soup_sub.find('div',class_='postlist').find_all('a',target='_blank') count = 0 for a in all_a: count = count + 1 if (count % 2) == 0: print("內頁第幾頁:" + str(count)) # 提取href href = a.attrs['href'] print("套圖地址:" + href) res_sub_1 = requests.get(href, headers=headers) soup_sub_1 = BeautifulSoup(res_sub_1.text, 'html.parser') # ------ 這裡最好使用異常處理 ------ try: # 獲取套圖的最大數量 pic_max = soup_sub_1.find('div',class_='pagenavi').find_all('span')[6].text print("套圖數量:" + pic_max) for j in range(1, int(pic_max) + 1): # print("子內頁第幾頁:" + str(j)) # j int型別需要轉字串 href_sub = href + "/" + str(j) print(href_sub) res_sub_2 = requests.get(href_sub, headers=headers) soup_sub_2 = BeautifulSoup(res_sub_2.text, "html.parser") img = soup_sub_2.find('div', class_='main-image').find('img') if isinstance(img, bs4.element.Tag): # 提取src url = img.attrs['src'] array = url.split('/') file_name = array[len(array)-1] # print(file_name) # 防盜鏈加入Referer headers = {'Referer': href} img = requests.get(url, headers=headers) # print('開始儲存圖片') f = open(file_name, 'ab') f.write(img.content) # print(file_name, '圖片儲存成功!') f.close() except Exception as e: print(e) # 主方法 def main(): res = requests.get(mziTu, headers=headers) # 使用自帶的html.parser解析 soup = BeautifulSoup(res.text, 'html.parser') # 建立資料夾 createFile(save_path) # 獲取首頁總頁數 img_max = soup.find('div', class_='nav-links').find_all('a')[3].text # print("總頁數:"+img_max) for i in range(1, int(img_max) + 1): # 獲取每頁的URL地址 if i == 1: page = mziTu else: page = mziTu + 'page/' + str(i) file = save_path + '\\' + str(i) createFile(file) # 下載每頁的圖片 print("套圖頁碼:" + page) download(page, file) if __name__ == '__main__': main()
程式碼分析:
if __name__ == '__main__': main()
這段程式碼啥意思呢?
if __name__ == '__main__'的意思是:當.py檔案被直接執行時,if __name__ == '__main__'之下的程式碼塊將被執行;當.py檔案以模組形式被匯入時,if __name__ == '__main__'之下的程式碼塊不被執行。
如果沒有這段程式碼 主方法main()也就無法被直接執行,可以簡單先理解為啟動主方法的入口。
然後我們再看主方法
# 主方法
def main():
res = requests.get(mziTu, headers=headers)
// 我們可以從這個物件res中獲取所有我們想要的資訊 下行res.text 就是當前頁面的html資訊 具體看對應API
# 使用自帶的html.parser解析
soup = BeautifulSoup(res.text, 'html.parser')
//html字串建立BeautifulSoup物件 此處可以soup.title soup.title.name soup.title.string soup.a['href'] soup.p['class'] 不嫌事多,你可以打印出來看看,具體看對應API
# 建立資料夾
createFile(save_path) //建立目標資料夾,作用當然用來存爬到的資源
# 獲取首頁總頁數
img_max = soup.find('div', class_='nav-links').find_all('a')[3].text
# print("總頁數:"+img_max)
for i in range(1, int(img_max) + 1):
# 獲取每頁的URL地址
if i == 1:
page = mziTu
else:
page = mziTu + 'page/' + str(i)
file = save_path + '\\' + str(i)
createFile(file)
# 下載每頁的圖片
print("套圖頁碼:" + page)
download(page, file)
核心程式碼
res = requests.get(mziTu, headers=headers) soup = BeautifulSoup(res.text, 'html.parser')以上兩段程式碼我們基本上拿到了以下html資訊的全部

# 獲取首頁總頁數 img_max = soup.find('div', class_='nav-links').find_all('a')[3].text
第一步:soup.find('div',class='nav-links')取到class='nav-links'的div
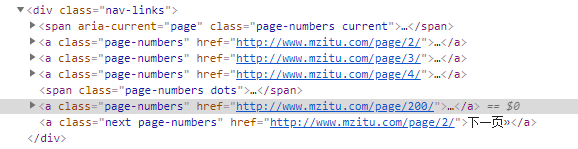
第二步:.find_all('a') 在該div內取全部的<a></a>標籤 為一個數組

第三步:.find_all('a')[3] 取第四個<a></a>標籤 陣列下標從0開始

第四步:.find_all('a')[3].text 取得頁碼總數 也就是 200
for i in range(1, int(img_max) + 1): # 獲取每頁的URL地址 if i == 1: page = mziTu else: page = mziTu + 'page/' + str(i) file = save_path + '\\' + str(i) createFile(file) # 下載每頁的圖片 print("套圖頁碼:" + page) download(page, file)
這段理解起來很簡單
第一步:建立存放資料夾 此處save_path="G:\BeautifulPictures\num" num=[1,200] 程式執行後,此目錄有源源不斷的圖片紛至杳來。
第二步:拼接原始檔(每一張圖片)路徑?目標是此,但此處具體到每一頁(路徑是:http://www.mzitu.com/page/num num=[1,200]),還沒深入到每一個專題。要想具體到每一張只能繼續往下爬,此處可移步download(page,file)方法。
例如現在num=4 經過download()方法就可以具體到每一張圖片了 下面分析download()方法
# 下載檔案 def download(page_no, file_path): global headers res_sub = requests.get(page_no, headers=headers) # 解析html soup_sub = BeautifulSoup(res_sub.text, 'html.parser') # 獲取頁面的欄目地址 all_a = soup_sub.find('div',class_='postlist').find_all('a',target='_blank') count = 0 for a in all_a: count = count + 1 if (count % 2) == 0: print("內頁第幾頁:" + str(count)) # 提取href href = a.attrs['href'] print("套圖地址:" + href) res_sub_1 = requests.get(href, headers=headers) soup_sub_1 = BeautifulSoup(res_sub_1.text, 'html.parser') # ------ 這裡最好使用異常處理 ------ try: # 獲取套圖的最大數量 pic_max = soup_sub_1.find('div',class_='pagenavi').find_all('span')[6].text print("套圖數量:" + pic_max) for j in range(1, int(pic_max) + 1): # print("子內頁第幾頁:" + str(j)) # j int型別需要轉字串 href_sub = href + "/" + str(j) print(href_sub) res_sub_2 = requests.get(href_sub, headers=headers) soup_sub_2 = BeautifulSoup(res_sub_2.text, "html.parser") img = soup_sub_2.find('div', class_='main-image').find('img') if isinstance(img, bs4.element.Tag): # 提取src url = img.attrs['src'] array = url.split('/') file_name = array[len(array)-1] # print(file_name) # 防盜鏈加入Referer headers = {'Referer': href} img = requests.get(url, headers=headers) # print('開始儲存圖片') f = open(file_name, 'ab') f.write(img.content) # print(file_name, '圖片儲存成功!') f.close() except Exception as e: print(e)
假設num=4 ,此時
page_no='http://www.mzitu.com/page/4'
經過request.get(),傳送get請求,再被BeautifulSoup解析我們就拿到了下面的html程式碼
res_sub = requests.get(page_no, headers=headers) # 解析html soup_sub = BeautifulSoup(res_sub.text, 'html.parser')
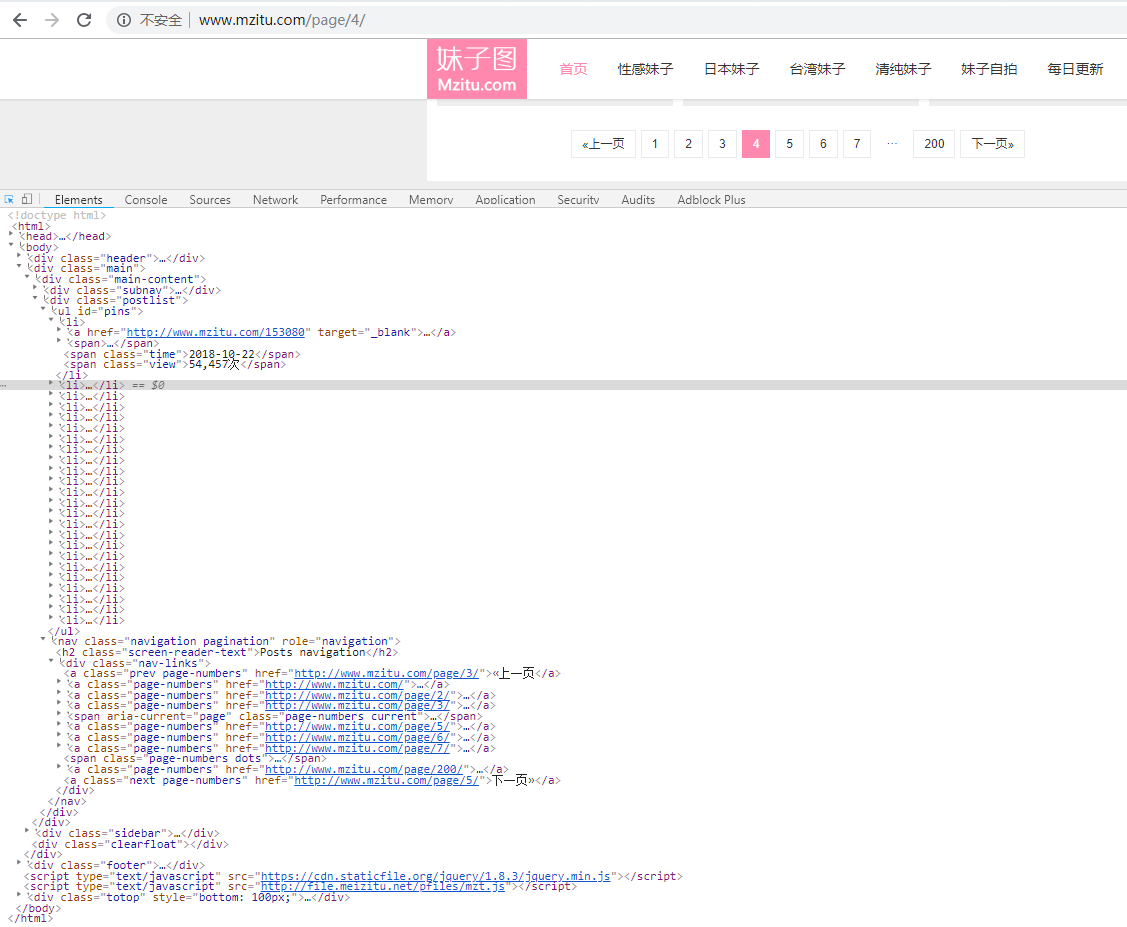
然後我們很容易看到我們的目標檔案是,id='pins'下的所有<a></a>標籤,如下圖。此herf只具體到每一個小姐姐的第一張照片,還不能具體到小姐姐的每一張照片。沒關係,點選連結進去,再看看。
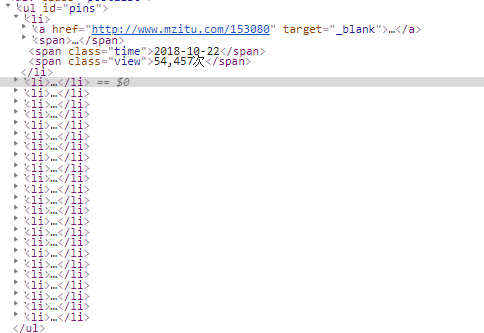
此時我們再看
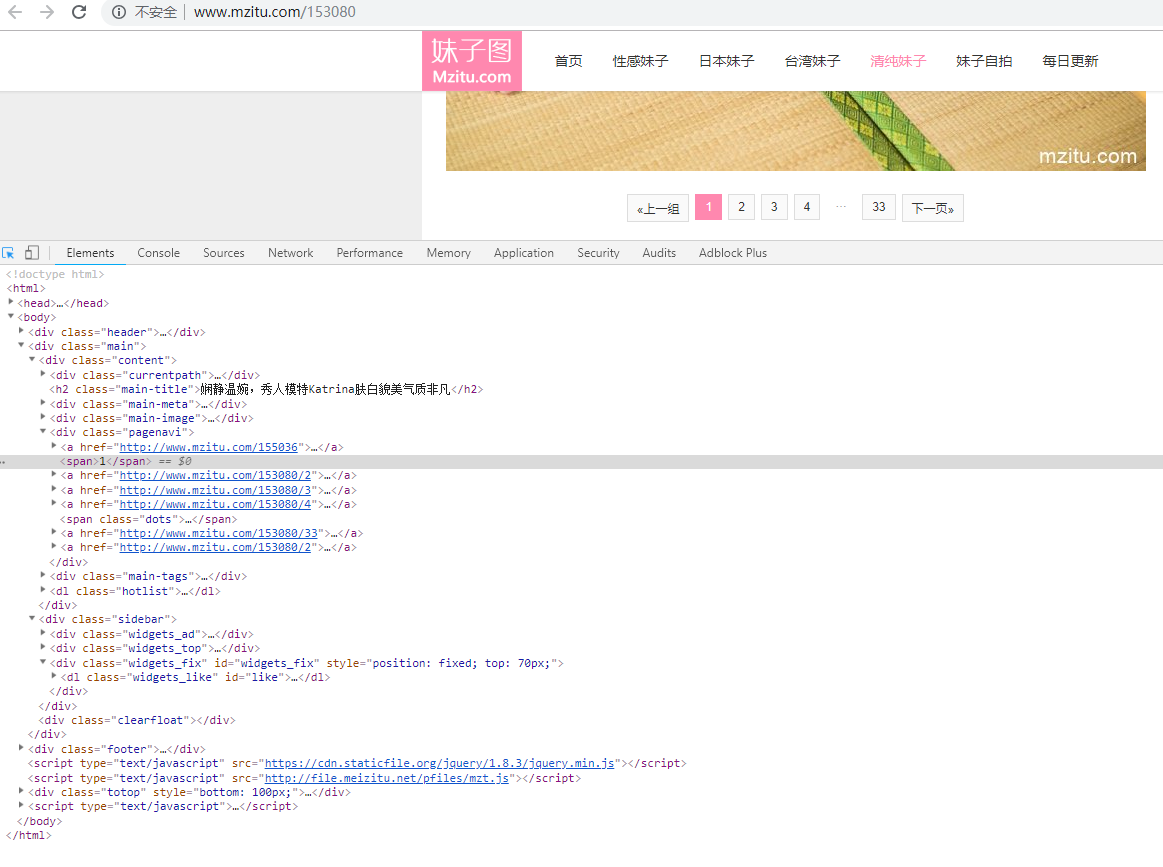
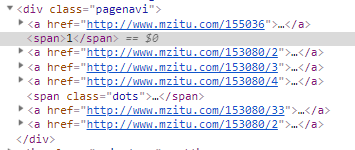
再扒一層就到具體的每一張圖片的地址了,讀一波,寫一波f.write(img.content),一波走起,儲存本地,
然後看本地的戰利品:請愛惜自己的身體

個人小小的趕腳,爬蟲抓包,找到你需要下載的每一個路徑,一步步去按標籤爬,儲存本地。貌似也挺簡單的哈。第一次跑Python程式碼,不好的地方見笑。
原始碼碼雲地址:https://gitee.com/52itstyle/Python 感興趣的一起學一波,組個隊。