
java中的Map集合
什麼是Map集合?
Map用於儲存具有對映關係的資料,Map集合裡儲存著兩組值,一組用於儲存Map的ley,另一組儲存著Map的value。
圖解
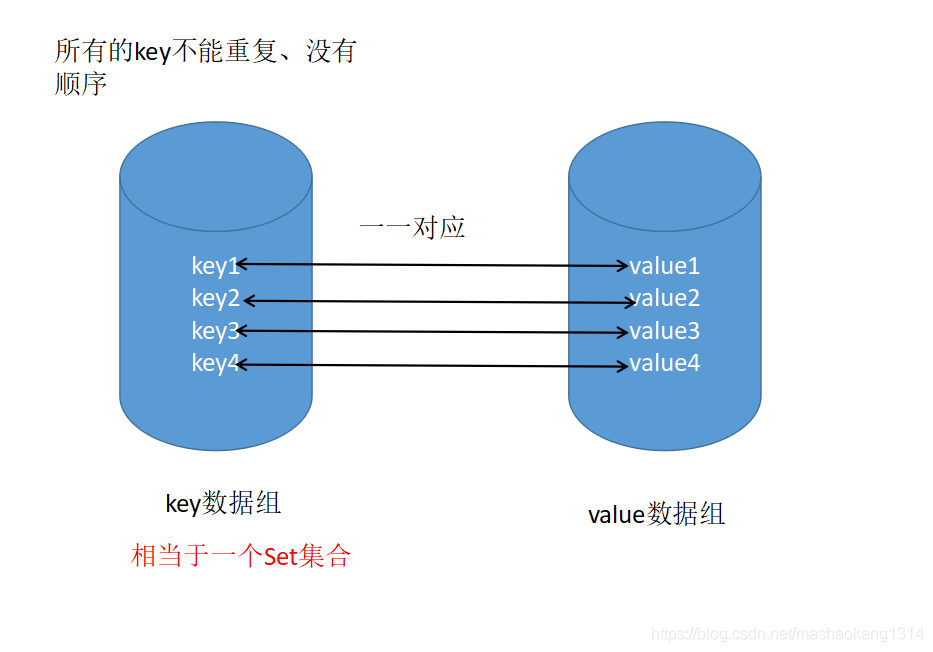
map集合的作用
和查字典類似,通過key找到對應的value,通過頁數找到對應的資訊。用學生類來說,key相當於學號,value對應name,age,sex等資訊。用這種對應關係方便查詢。
Map和Set的關係
可以說關係是很密切了,雖然Map中存放的時鍵值對,Set中存放的是單個物件,但如果把value看做key的附庸,key在哪裡,value就在哪裡,這樣就可以像對待Set一樣來對待Map了。事實上,Map提供了一個Entry內部類來封裝key-value對,再計算Entry儲存時則只考慮Entry封裝的key。
如果把Map集合裡的所有value放在一起來看,它們又類似於一個List,元素可以重複,每個元素可以根據索引來找,只是Map中的索引不再是整數值,而是以另一個物件作為索引。
Map中的常用方法:
void clear():刪除該Map物件中所有鍵值對;boolean containsKey(Object key):查詢Map中是否包含指定的key值;boolean containsValue(Object value):查詢Map中是否包含一個或多個value;Set entrySet():返回map中包含的鍵值對所組成的Set集合,每個集合都是Map.Entry物件。Object get():返回指定key對應的value,如果不包含key則返回null;boolean isEmpty():查詢該Map是否為空;Set keySet():返回Map中所有key組成的集合;Collection values():返回該Map裡所有value組成的Collection。Object put(Object key,Object value):新增一個鍵值對,如果集合中的key重複,則覆蓋原來的鍵值對;void putAll(Map m):將Map中的鍵值對複製到本Map中;Object remove(Object key):刪除指定的key對應的鍵值對,並返回被刪除鍵值對的value,如果不存在,則返回null;boolean remove(Object key,Object value):刪除指定鍵值對,刪除成功返回true;int size():返回該Map裡的鍵值對個數;
內部類Entry
Map中包括一個內部類Entry,該類封裝一個鍵值對,常用方法:
Object getKey():返回該Entry裡包含的key值;Object getvalue():返回該Entry裡包含的value值;Object setValue(V value):設定該Entry裡包含的value值,並設定新的value值。
例項:
HashMap<String, Integer> hm = new HashMap<>();
//放入元素
hm.put("Harry",23);
hm.put("Jenny",24);
hm.put("XiaoLi",20);
System.out.println(hm);//{XiaoLi=20, Harry=23, Jenny=24}
System.out.println(hm.keySet());//[XiaoLi, Harry, Jenny]
System.out.println(hm.values());//[20, 23, 24]
Set<Map.Entry<String, Integer>> entries = hm.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
java8為Map新增的方法
Object compute(Object key,BiFurcation remappingFunction):使用remappingFunction根據原鍵值對計算一個新的value,只要新value不為null,就覆蓋原value;如果新value為null則刪除該鍵值對,如果同時為null則不改變任何鍵值對,直接返回null。
HashMap<String, Integer> hm = new HashMap<>();
//放入元素
hm.put("Harry",23);
hm.put("Jenny",24);
hm.put("XiaoLi",20);
System.out.println(hm);//{XiaoLi=20, Harry=23, Jenny=24}
hm.compute("Harry",(key,value)->(Integer)value+10);
System.out.println(hm);//{XiaoLi=20, Harry=33, Jenny=24}
Object computeIfAbsent(Object key,Furcation mappingFunction):如果傳給該方法的key引數在Map中對應的value為null,則使用mappingFunction根據key計算一個新的結果,如果計算結果不為null,則計算結果覆蓋原有的value,如果原Map原來不包含該Key,那麼該方法可能會新增一組鍵值對。
HashMap<String, Integer> hm = new HashMap<>();
//放入元素
hm.put("Harry",23);
hm.put("Jenny",24);
hm.put("XiaoLi",20);
hm.put("LiMing",null);
//指定key為null則計算結果作為value
hm.computeIfAbsent("LiMing",(key)->10);
System.out.println(hm);//{XiaoLi=20, Harry=23, Jenny=24, LiMing=10}
//如果指定key本來不存在,則新增對應鍵值對
hm.computeIfAbsent("XiaoHong",(key)->34);
System.out.println(hm);//{XiaoLi=20, Harry=23, XiaoHong=34, Jenny=24, LiMing=10}
Object compute(Object key,BiFurcation remappingFunction):如果傳給該方法的key引數在Map中對應的value不為null,則通過計算得到新的鍵值對,如果計算結果不為null,則覆蓋原來的value,如果計算結果為null,則刪除原鍵值對。
hm.computeIfPresent("Harry",(key,value)->(Integer)value*(Integer)value);
System.out.println(hm);
//{XiaoLi=20, Harry=529, Jenny=24, LiMing=null}
void forEach(BiConsumer action):遍歷鍵值對。
HashMap<String, Integer> hm = new HashMap<>();
//放入元素
hm.put("Harry",23);
hm.put("Jenny",24);
hm.put("XiaoLi",20);
hm.put("LiMing",null);
hm.forEach((key,value)-> System.out.println(key+"->"+value));
/*XiaoLi->20
Harry->23
Jenny->24
LiMing->null*/
Object getOrDefault(Object key,V defaultValue):獲取指定key對應的value,如果key不存在則返回defaultValue;
System.out.println(hm.getOrDefault("Harry",33));//23
Object merge(Object key,Object value,BiFurcation remappingFunction):該方法會先根據key引數獲取該Map中對應的value。如果獲取的value為null,則直接用傳入的value覆蓋原有的value,如果獲取的value不為null,則使用remappingFunction函式根據原value、新value計算一個新的結果,並用得到的結果去覆蓋原有的value。
HashMap<String, Integer> hm = new HashMap<>();
//放入元素
hm.put("Harry",23);
hm.put("Jenny",24);
hm.put("XiaoLi",20);
hm.put("LiMing",null);
hm.merge("LiMing",24,(key,value)->value+10);
System.out.println(hm);//{XiaoLi=20, Harry=23, Jenny=24, LiMing=24}
hm.merge("Harry",24,(key,value)->value+10);
System.out.println(hm);//{XiaoLi=20, Harry=34, Jenny=24, LiMing=24}
Object putIfAbsent(Object key,Object value):該方法會自動檢測指定key對應的value是否為null,如果為null,則用新value去替換原來的null值。Object replace(Object key,Object value):將key對應的value替換成新的value,如果key不存在則返回null。boolean replace(K key,V oldValue,V newValue):將指定鍵值對的value替換成新的value,如果未找到則返回false;replaceAll(BiFunction Function):使用BiFunction對原鍵值對執行計算,並將結果作為該鍵值對的value值。
java8改進的HashMap和Hashtable實現類
HashMap和Hashtable的關係完全類似於ArrayList和Vector的關係。
區別
- Hashtable是線性安全的,HashMap是線性不安全的,所以後者效率更高。
- Hashtable不允許使用null作為key和value,否則會引發異常,而HashMap可以;
和HashSet的關係
- 與HashSet集合不能保證元素順序一樣,HashMap和Hashtable也不能保證鍵值對的順序。他們判斷兩個key相等的標準也是:兩個key通過equals方法比較返回true,兩個key的hashCode值也相等。而判斷value值相等的標準:只要兩個物件通過equals方法比較返回true即可。
- 不能修改集合中的key,否則程式再也無法準確訪問到Map中被修改過的key。
LinkedHashMap實現類
和HashSet中的LinkedHashSet一樣,HashMap也有一個LinkedHashMap子類,使用雙向連結串列來維護鍵值對的次序,迭代順序和插入順序保持一致。
使用Properties讀寫屬性檔案
Properties類是Hashtable類的子類,該物件在處理屬性檔案時特別方便。Properties類可以把Map物件和屬性檔案關聯起來,從而把Map物件的鍵值對寫入屬性檔案中,也可以把屬性檔案中的“屬性名=屬性值”載入到Map物件中。
Properties相當於一個key、value都是String型別的Map
String getProperty(String key):獲取Properties中指定的屬性名對應的屬性值。String getProperty(String key,String defaultValue):和前一個方法相同,只不過如果key不存在,則該方法指定預設值。Object setProperty(String key,String value):設定屬性值,類似於Hashtable的put方法;void load(InputStream inStream):從屬性檔案中載入鍵值對,把加載出來的鍵值對追加到Properties裡。void store(OutputStream out,String comments):將Properties中的鍵值對輸出到指定的屬性檔案中。
例項:
public static void main(String[] args) throws Exception {
Properties props = new Properties();
//向Properties中新增屬性
props.setProperty("username","yeeku");
props.setProperty("password","123456");
//儲存到檔案中
props.store(new FileOutputStream("a.ini"),"comment line");
//新建一個Properties物件
Properties props2 = new Properties();
props2.setProperty("gender","male");
//將檔案中的鍵值對追加到物件中
props2.load(new FileInputStream("a.ini"));
System.out.println(props2);//{password=123456, gender=male, username=yeeku}
}
檔案內容
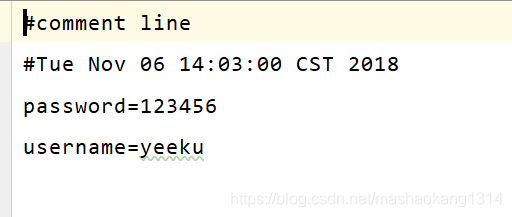
還可以把鍵值對以XML檔案的形式儲存起來,同樣可以從檔案中加載出來,用法與上述案例相同。
SortedMap介面和TreeMap實現類
正如Set介面派生出SortedSet子介面,Sorted介面有一個TreeSet實現類一樣,Map介面也派生出一個SortedMap子介面,SortedMap介面也有一個TreeMap實現類。
TreeMap就是一個紅黑樹資料結構,每個鍵值對作為紅黑樹的一個節點。儲存鍵值對時根據key對節點進行排序。可以保證所有鍵值對處於有序狀態。
和TreeSet一樣,TreeMap也有自然排序和定製排序兩種排序方式。
與TreeSet類似的是,TreeMap中提供了一系列根據key順序訪問鍵值對的方法:
public static void main(String[] args) {
TreeMap<String, Integer> stuTreeMap = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int num=o1.compareTo(o2);
return num;
}
});
stuTreeMap.put("LiMing",14);
stuTreeMap.put("LiMing",24);
stuTreeMap.put("Jenny",16);
stuTreeMap.put("Denny",24);
System.out.println(stuTreeMap);//{Denny=24, Jenny=16, LiMing=24}
System.out.println(stuTreeMap.firstEntry());//Denny=24
}
Map.Entry firstEntry():返回該Map中最小的key所對應的鍵值對,如果Map為空則返回null;
System.out.println(stuTreeMap.firstEntry());//Denny=24
-
Object firstKey():返回該Map中的最小key值,如果Map為空則返回null; -
Object lastKey():返回該Map中的最大key值,如果Map為空則返回null; -
Map.Entry higherEntry(Object key):返回該Map中位於key後一位的鍵值對; -
Object higherKey(Object key):返回該Map中位於key後一位的key; -
Map.Entry lowerEntry(Object key):返回該Map中位於key前一位的鍵值對; -
Object lowererKey(Object key):返回該Map中位於key前一位的key; -
NavigableMap tailMap(Object fromkey,boolean fromInclusive,Object toKey,boolean toInclusive):返回該Map的子Map,其key範圍從fromkey(是否包含取決於第二個引數)到toKey(是否包含取決於第四個引數)。
WeakHashMap實現類
WeakHashMap與HashMap的用法基本相似,區別在於HashMap的key保留了對實際物件的強引用,這意味著只要該物件不銷燬,該HashMap的所有key所引用的物件就不會被垃圾回收,HashMap也不會自動刪除這些key所對應的鍵值對,但WeakHashMap的key只保留了對實際物件的弱引用,這意味著如果WeakHashMap物件的key所引用的物件沒有被其他強引用變數所引用,則這些key所引用的物件可能被垃圾回收,WeakHashMap也可能自動刪除這些key對應的鍵值對。
IdentityHashMap實現類
這個類的實現機制與HashMap基本相似,但它在處理兩個key相等時比較獨特:在IdentityHashMap中,當且僅當兩個key嚴格相等(key1==key2)時,IdentityHashMap才認為兩個key相等,對於普通的HashMap而言,只要key1和key2通過equals方法比較返回true,且它們的hashcode相等即可。
IdentityHashMap map = new IdentityHashMap<>();
map.put(new String("語文"), 89);
map.put(new String("語文"), 90);
map.put("java",70);
map.put("java",71);
System.out.println(map);//{java=71, 語文=90, 語文=89}
前面是兩個物件雖然通過equal方法比較是相等的,但是通過==比較不相等,後面兩個字串在常量池中同一位置,所以使用==判斷相等。