
sklearn庫的學習(轉載)
原部落格地址:https://blog.csdn.net/u014248127/article/details/78885180
網上有很多關於sklearn的學習教程,大部分都是簡單的講清楚某一個方面。其實最好的教程就是官方文件(http://scikit-learn.org/stable/),但是官方文件講述的太過於詳細,同時很多人對官方文件的理解和結構認識上都不能很好的把握。我寫這篇文章的目的是想用一篇文章講清楚整個sklearn庫,我會講清楚怎麼樣用這個庫,而不是講清楚每一個知識點。(授人以魚不如授人以漁)(本文很多都是從實踐的角度出發,也僅僅只代表我個人的認識)
本篇文章主要從兩個方面出發:1,介紹sklearn官方文件的類容和結構;2,從機器學習重要步驟出發講清楚sklearn的使用方法。
一、sklearn官方文件的類容和結構
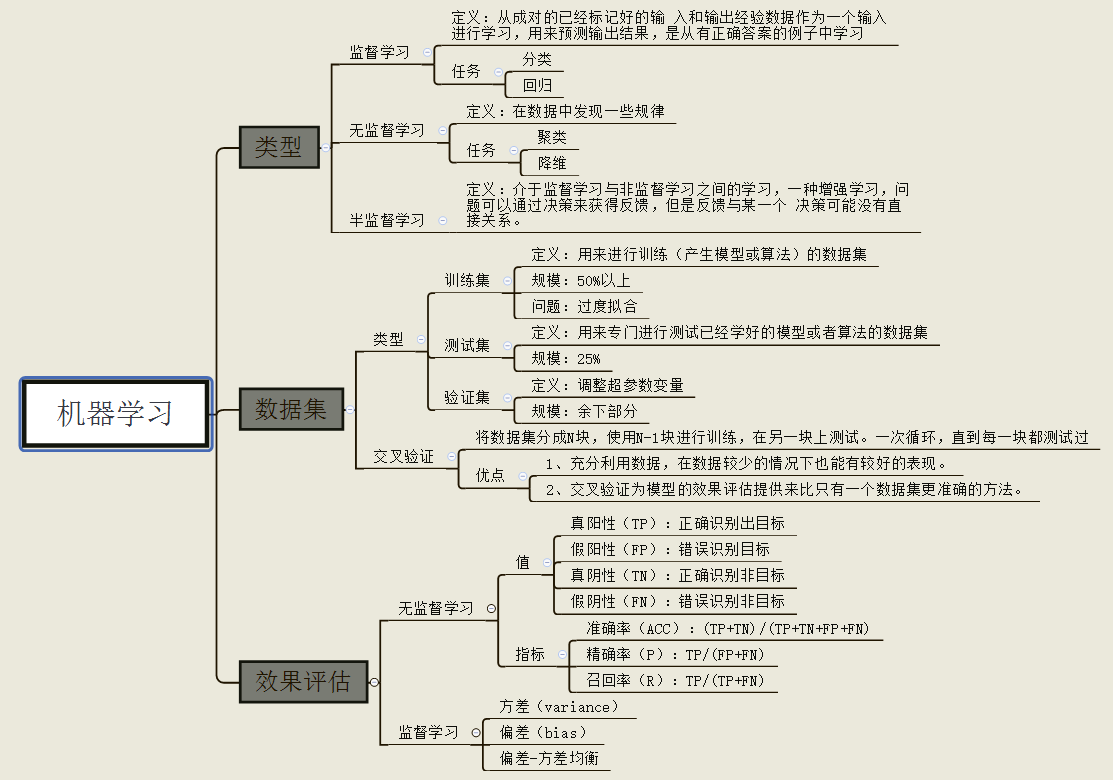
1,機器學習的認識:從實踐的角度出發,機器學學習要做的工作就是在我們有的一個數據集上建立一個或者多個模型,然後對我們的模型進行優化和評估。我們將會在sklearn中看到下圖各個模組到底是什麼,怎麼用。
2,sklearn庫官方文件結構:
下圖表示:官方文件有很多模組:
tutorials:是一個官方教程,可以理解快速上手教程,但是看完感覺並沒有很快。
user guide(使用者指南):這裡對每一個演算法有詳細的介紹
API:這裡是庫呼叫的方法
FAQ:常見問題
contributing:貢獻,還介紹最新的一些程式碼,功能。
(下面三個就跟沒有用了)
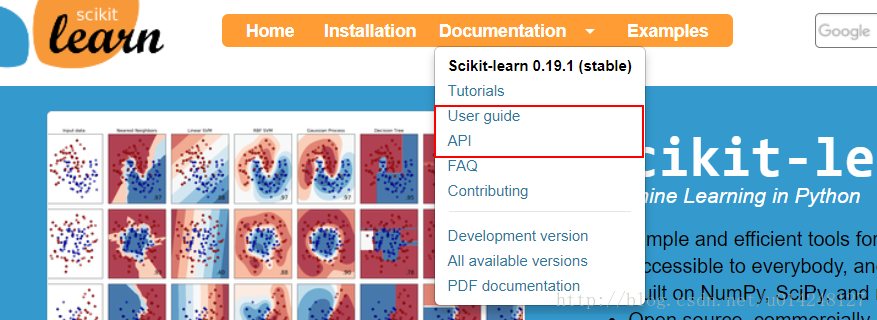
總結:一般的做法是API裡面找到你要呼叫的方法,然後可以檢視方法引數的情況和使用情況。也可以在指南里面找到具體的解釋。
3,sklearn庫的結構:
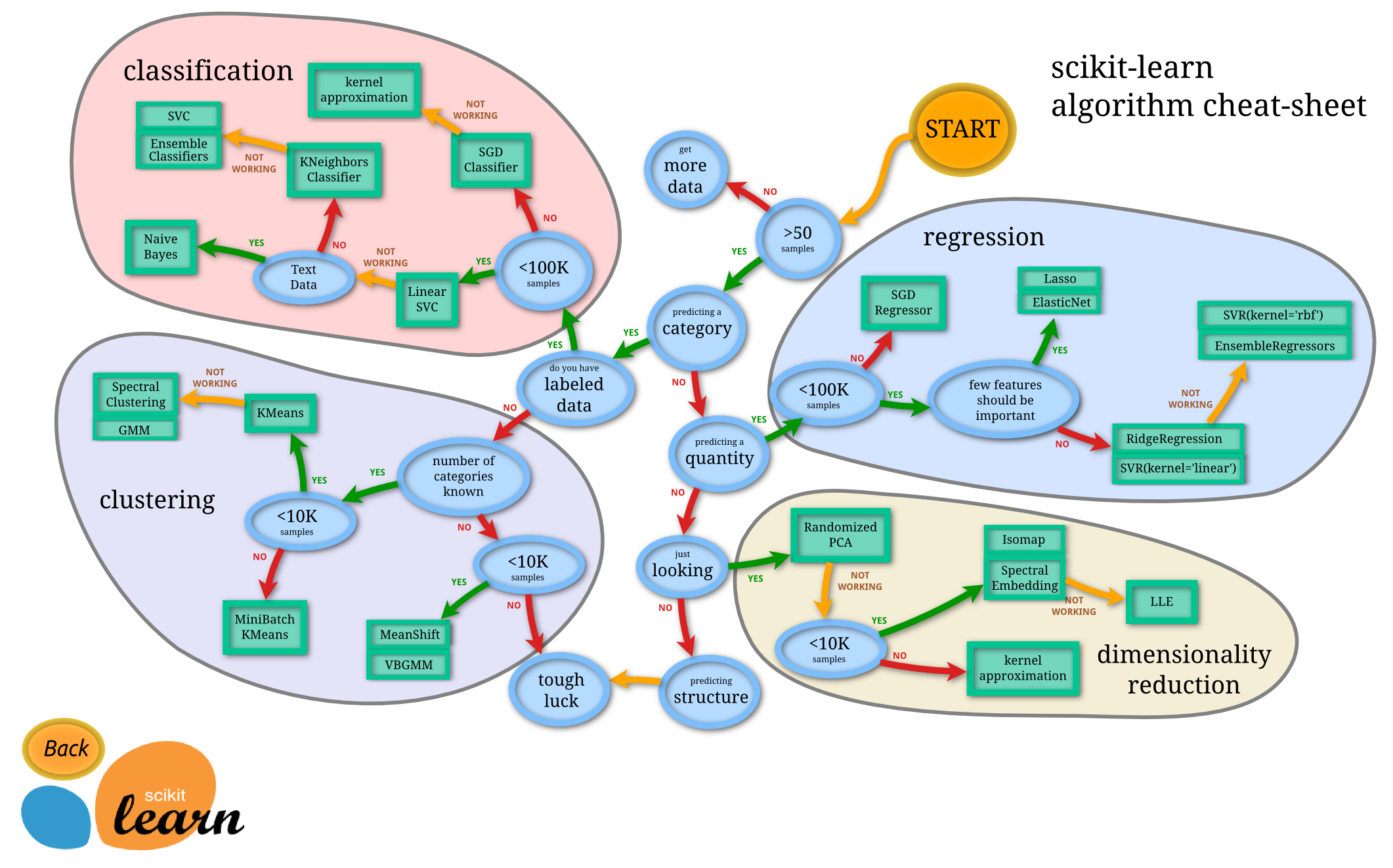
(1)結構:
由圖中,可以看到庫的演算法主要有四類:分類,迴歸,聚類,降維。其中:
常用的迴歸:線性、決策樹、SVM、KNN ;整合迴歸:隨機森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用的分類:線性、決策樹、SVM、KNN,樸素貝葉斯;整合分類:隨機森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用聚類:k均值(K-means)、層次聚類(Hierarchical clustering)、DBSCAN
常用降維:LinearDiscriminantAnalysis、PCA
(2)圖片中隱含的操作流程:
這個流程圖代表:藍色圓圈內是判斷條件,綠色方框內是可以選擇的演算法。你可以根據自己的資料特徵和任務目標去找到一條自己的操作路線,一步步做就好了。
二、機器學習主要步驟中sklearn應用
1,資料集:面對自己的任務肯定有自己的資料集,但是對於學習來說,sklearn提供了一些資料,主要有兩部分:現在網上一些常用的資料集,可以通過方法載入;另一種sklearn可以生成資料,可以生成你設定的資料。(設定規模,噪聲等)
下面是一段python例項:
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
#使用以後的資料集進行線性迴歸(這裡是波士頓房價資料)
loaded_data=datasets.load_boston()
data_X=loaded_data.data
data_y=loaded_data.target
model=LinearRegression()
model.fit(data_X,data_y)
print(model.predict(data_X[:4,:]))
print(data_y[:4])
#使用生成線性迴歸的資料集,最後的資料集結果用散點圖表示
X,y=datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=10) #n_samples表示樣本數目,n_features特徵的數目 n_tragets noise噪音
plt.scatter(X,y)
plt.show()
2,資料預處理:資料預處理包括:降維、資料歸一化、特徵提取和特徵轉換(one-hot)等,這在sklearn裡面有很多方法,具體檢視api。這裡用歸一化(preprocessing.scale() )例子解釋一下:
from sklearn import preprocessing #進行標準化資料時,需要引入個包
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
X,y=make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22,n_clusters_per_class=1,scale=100)
#X=preprocessing.minmax_scale(X,feature_range=(-1,1))
X=preprocessing.scale(X) #0.966666666667 沒有 0.477777777778
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
clf=SVC()
clf.fit(X_train,y_train)
print(clf.score(X_test,y_test))
plt.scatter(X[:,0],X[:,1],c=y)
plt.show()
a=np.array([[10,2.7,3.6],
[-100,5,-2],
[120,20,40]],dtype=np.float64) #每一列代表一個屬性
print(a) #標準化之前a
print(preprocessing.scale(a)) #標準化之後的a
3,選擇模型並訓練: sklearn裡面有很多的機器學習方法,可以檢視api找到你需要的方法,sklearn統一了所有模型呼叫的api,使用起來還是比較簡單。
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
#使用以後的資料集進行線性迴歸
loaded_data=datasets.load_boston()
data_X=loaded_data.data
data_y=loaded_data.target
model=LinearRegression()
model.fit(data_X,data_y)
print(model.predict(data_X[:4,:]))
print(data_y[:4])
#引數
print(model.coef_) #如果y=0.1x+0.3 則此行輸出的結果為0.1
print(model.intercept_) #此行輸出的結果為0.3
print(model.get_params()) #模型定義時定義的引數,如果沒有定義則返回預設值
print(model.score(data_X,data_y)) #給訓練模型打分,注意用在LinearR中使用R^2 conefficient of determination打分
4,模型評分:
(1)模型的score方法:最簡單的模型評估方法是呼叫模型自己的方法:
#預測
y_predict = knnClf.predict(x_test)
print("score on the testdata:",knnClf.score(x_test,y_test))
(2)sklearn的指標函式:庫提供的一些計算方法,常用的有classification_report方法
下面是一個svm分類器,是關於圖片分類的,具體資料這裡沒有給出,大家只需要關注模型的評估就好。
def svmClassify(x_train, x_test, y_train, y_test):
id = range(1, x_test.shape[0]+1)
print("start run svm!")
#訓練
svc = svm.SVC(kernel='rbf', C=10,probability=True)
svc.fit(x_train, y_train)
#預測
y_predict = svc.predict(x_test)
print("svm mode's score on the test data:",svc.score(x_test,y_test))
print("svm mode's evaluate:",classification_report(y_test,y_predict))
# print(svc.coef_) # 如果y=0.1x+0.3 則此行輸出的結果為0.1
# print(svc.intercept_) # 此行輸出的結果為0.3
print(svc.get_params()) # 模型定義時定義的引數,如果沒有定義則返回預設值
#可能性計算
probablity = svc.predict_proba(x_test)
list_pro = []
for i in range(probablity.shape[0]):
pro = max(list(probablity[i]))
list_pro.append(pro)
#輸出
index = np.array(id).reshape(-1,1)
result = pd.DataFrame(np.column_stack((np.array(id).reshape(-1, 1), np.array(y_test).reshape(-1, 1),np.array(y_predict).reshape(-1,1),np.array(list_pro).reshape(-1,1))),
columns=['ImageId','test_label','predict_lable','probablity'])
result.to_csv("result/svm_result.csv", index=False, header=True, encoding='gbk')
diff_index = []
for i in range(result.shape[0]):
# print(result['test_label'][i], result['predict_lable'][i],)
diff_index.append(result['test_label'][i] != result['predict_lable'][i])
print(diff_index)
diff = result[diff_index]
diff_x = x_test_original[diff_index]
diff.to_csv('result/svm_result_diff.csv', index=False, header=True, encoding='gbk')
# 檢視每個錯誤
for i in range(len(diff_index)):
# print("label is:",diff['test_label'][i],"predict is:",diff['predict_lable'][i])
print("test label is :", diff.iloc[i]['test_label'], 'predict label is :', diff.iloc[i]['predict_lable'])
x = diff_x[i]
img = x.reshape(28, 28)
image_show(img)
(3)sklearn也支援自己開發評價方法
5,模型的保存於恢復:模型的儲存與恢復可以採用python的pickle,也可以用joblib的方法。
from sklearn import svm
from sklearn import datasets
clf=svm.SVC()
iris=datasets.load_iris()
X,y=iris.data,iris.target
clf.fit(X,y)
#method1:pickle
import pickle
#save
with open('save/clf.pickle','wb')as f:
pickle.dump(clf,f)
#restore
with open('save/clf.pickle','rb') as f:
clf=pickle.load(f)
print(clf.predict(X[0:1]))
#method2:joblib
from sklearn.externals import joblib
#save
joblib.dump(clf,'save/clf.pkl')
clf3=joblib.load('save/clf.pkl')
print(clf3.predict(X[0:1]))
這是一篇入門的文章,希望入門的人有一個很好的引導,接下來我也會跟新一些重要的內容。下一篇,我打算講解交叉驗證這個很重要的模組。
---------------------
作者:yealxxy
來源:CSDN
原文:https://blog.csdn.net/u014248127/article/details/78885180
版權宣告:本文為博主原創文章,轉載請附上博文連結!