Python3批量下載.dat和.hea檔案
阿新 • • 發佈:2018-11-22
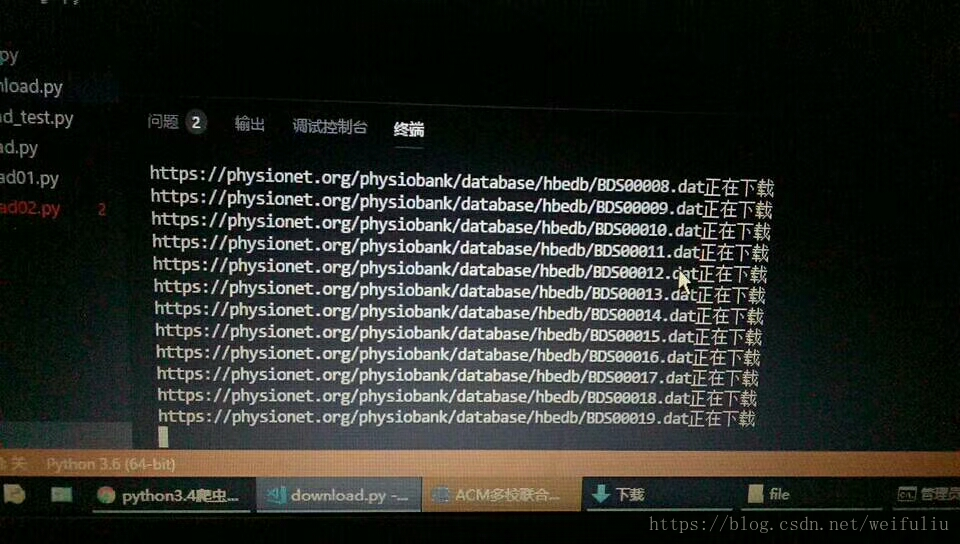
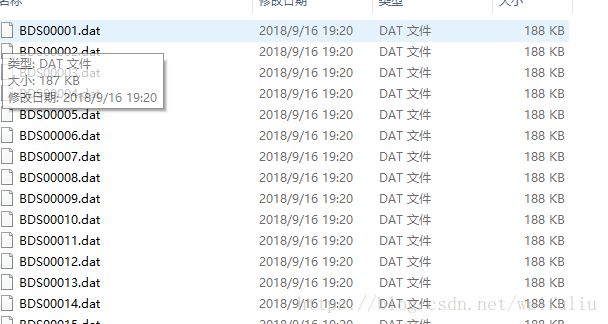
在杭州電子科技大學的讀研的哥哥研究專案需要在一個網站上下載資料進行資料分析,總共4000多份文件資料,若是手工點選連結下載的話,不知道要下載到猴年馬月了,還好我哥知道我會爬蟲,嘿嘿,這時候就該展現我Python爬蟲威力了。
程式碼
#https://physionet.org/physiobank/database/hbedb/BDS00001.dat
import requests
from bs4 import BeautifulSoup
import re
import os
import urllib
def getHTMLText(url):
try 效果圖