
Python爬蟲實戰--WeHeartIt爬蟲
阿新 • • 發佈:2018-11-23
前言:
通過上次的小豬短租爬蟲實戰,我們再次熟悉的使用requests傳送一個網頁請求,並使用BeautifulSoup來解析頁面,從中提取出我們的目標內容,並將其存入文件中。同時我們也學會了如何分析頁面,並提取出關鍵資料。
下面我們將進一步學習,並爬去小豬短租的詳情頁面,提取資料。
Just do it~~!
目標站點分析
目標URL:https://weheartit.com/inspirations/beach?page=1
明確內容:
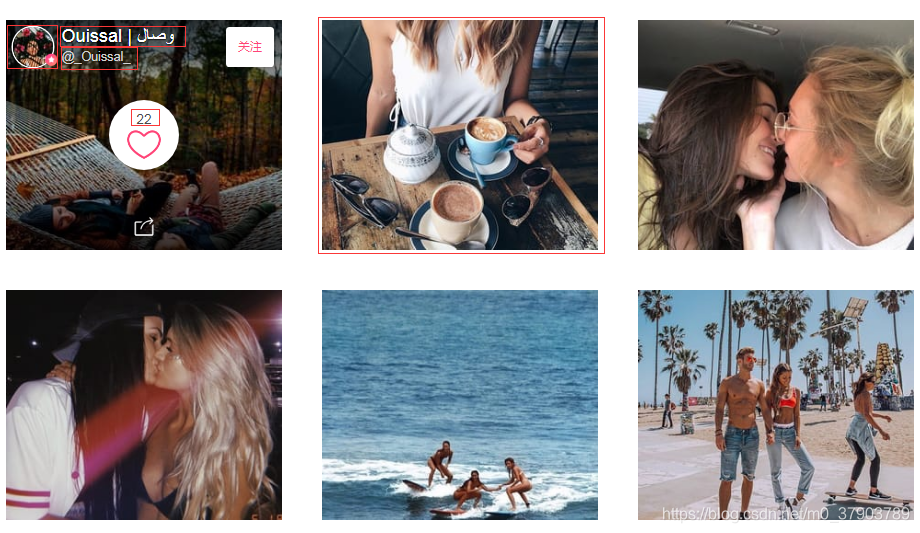
在列表頁面中,找的了我們需要的資料:如title,img_src,name,host_src,comment等(紅色方框中的內容)
下面我們需要遍歷所有的列表頁面,並從中提取目標資料。
業務邏輯:
1.查詢規律
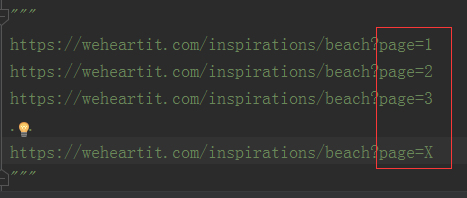
遍歷所有的列表頁,再下翻幾頁後,我們發現***page=X***(其中X為1,2,3,4…)
# 解析列表頁面,並提取詳情頁的URL def parse_html(self, html): soup = BeautifulSoup(html, 'lxml') lis = soup.select("div#page_list > ul > li") for li in lis: # 提取詳情頁URL page_url = li.select("a")[0].attrs['href']
2.提取資料
# 解析網頁,並提取資料 def parse_html(self, html): item_list = [] soup = BeautifulSoup(html, 'lxml') divs = soup.select("div.entry.grid-item") for div in divs: title = div.select("span.text-big")[0].get_text() img_src = div.select("img.entry-thumbnail")[0].attrs['src'] temp_name = div.select("a.js-blc-t-user")[0].attrs['href'] name = temp_name.replace('/', '') host_src = div.select("img.avatar")[0].attrs['src'] comment = div.select("span.js-heart-count")[0].get_text() item = dict( title=title, img_src=img_src, name=name, host_src=host_src, comment=comment, ) print(item) item_list.append(item) return item_list
3.儲存資料
# 儲存資料
def save_item(self, item_list):
with open('WeHeartIt.txt', 'a+', encoding='utf-8') as f:
for item in item_list:
json.dump(item, f, ensure_ascii=False, indent=2)
f.close()
print("Save success!")
結果展示

好了,本次講解,到這裡就差不多該結束啦~感興趣的同學,可以動手試試。
小練習
通過上面的爬蟲,我們獲得了圖片連結,那我們有該怎麼講圖片下載下來?並儲存到本地呢?
原始碼地址:https://github.com/NO1117/WeHeartIt_Spider
Python交流群:942913325 歡迎大家一起交流學習