
Hyperface人臉檢測演算法
論文地址:
《2016 PAMI HyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition.
全文翻譯有幾處文意不同,後期慢慢進行修改。
只是大體把主要步驟描述了一遍。
由深度學習完成,將人臉檢測,關鍵點定位,頭部角度預測與性別識別相結合。
此演算法用深度卷積神經網路完成(CNN:什麼是卷積神經網路及其結構),此方法名稱被稱為Hyperface,期間融合中間層。
Hyperface的兩個重要點:
1.Hyperface-ResNet基於ResNet-101模型,並在此基礎上實現了很大提升
2.Fast-Hyperface針對截出的臉部區域,使用了一個很高的召回率臉部識別器,以此提高了演算法速度
1.Introduction
同時使用四個任務進行預測估計,有助於提升單個任務效率。
淺層對邊與角落的資訊敏感,因此淺層有更好的關鍵點位置資訊。
淺層處理,有助於學習關鍵點定位與頭部角度預測任務。
深層更適合學習更復雜的任務,例如人臉識別與性別識別。
實現表明多工學習比單任務學習效果要好,也要用好融合中間層。
兩種後處理方法能有效提升識別效果:IRP與L-NMS
iterative region proposals 和 landmarks-based non-maximum suppression
深度學習網路與fusion-CNN結合相比其他的來說效果更好。
我們必須要用好深度神經網路的中間層,我們更傾向於在中間層設定hyperface的特徵。
通過融合中間層,我們推出兩種新的演算法,Hyperface與HF-ResNet
2.Hyperface
Hyperface演算法由三個模組組成:
1.生成裁剪區域框
用選擇性搜尋(什麼是selective search)選出候選框,然後resize到227*227畫素中:
2.用CNN判別該區域是否是臉部。如果是臉,那麼進行另外三個判斷
3.後處理階段IPR與L-NMS,用來提高臉部檢測分數與提升單個任務的效能。
2.1Hyperface的結構組成
採用Alexnet進行影象分類,每個輸入圖片都將被縮放成227*227大小,分rgb三個顏色維度輸入。AlexNet一共8個層,包含前5個卷積層與後3個全連線層(什麼是全連線層)。每一層所做的處理:請點擊出檢視。利用R-CNN_Face網路初始化模型
影象中卷積卷積地是什麼意思呢,就是影象f(x),模板g(x),然後將模版g(x)在模版中移動,每到一個位置,就把f(x)與g(x)的定義域相交的元素進行乘積並且求和,得出新的影象一點,就是被卷積後的影象. 模版又稱為卷積核.卷積核做一個矩陣的形狀.
去除了三個全連線層,因為這三個全連線層對於頭部姿態估計與關鍵點定位不能起到幫助。
演算法對於以下兩項進行了拓展,從而建立自己的網路:
(1)低層特徵有助於進行關鍵點識別與頭部姿態估計,高層有助於識別與分類
(2)我們通過融合中間層的特徵,來達到四個任務的目標,但並不是把所有的中間層都融合。
我們使用分開的網路融合了AlexNet的最大層1(維度:27*27*96),卷積層3(13*13*384)與池化層5(6*6*256)(具體流程)。
他們有各自的維度,因此我們添加了卷積層conv1a與conv3a,分別新增到池化層pool1與卷積層conv3後,來獲取持續的feature map(6*6*256)(什麼是feature map)。我們之後連線池化層pool5來形成一個6*6*768維度的feature map。
我們用一個1*1的卷積核(什麼是1*1卷積核),新增到(6*6*192)裡面來進行降維。
我們對於CONVall新增一個全連線層(FCall,輸出3072個特徵向量)。
我們將網路分為5各分支對應5個1不同的任務,我們新增:

全連線層,到FCall中。
最後一個全連線層新增到最後,連線各自的五個任務。
最後我們再新增ReLU當做啟用函式,同時我們不考慮池化層。
整個演算法的流程如下圖所示:

3.Training
使用AFLW人臉資料庫進行訓練,AFLW提供臉部的21個位置標記點。我們使用損失函式(loss function)進行評估。
臉部識別,使用R-CNN的Selective Search演算法來找到臉部區域。利用IOU係數(Intersection over Union),如果IOU超過0.5,那麼就認為是一個正樣本(即人臉),低於0.35被認為是負樣本(不是人臉),其他區域被忽略。
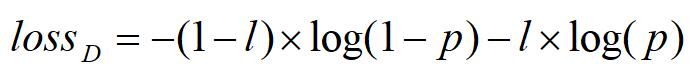
p是區域是否是人臉的概率。概率值從最後一層的全連線層中獲取。
關鍵點定位:
我們利用AFLW提供的臉部21點位置資訊來進行定位。AFLW的資料庫提供了定位資訊。如下圖所示
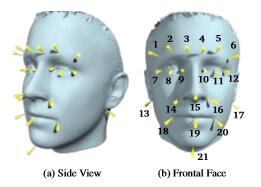
一個區域的特徵有四個點資訊{x,y,w,h},x,y是區域的位置,w,h是區域的寬度與高度。

上述公式,是利用可見因子(visbility factor)為衡量標準的使用歐幾里得損失函式來訓練關鍵點特徵的任務。
ai,bi是訓練的標籤,xi,yi是真實的臉部座標位置。xywh是人臉框。
計算預測關鍵點標記的損失函式如下所示:
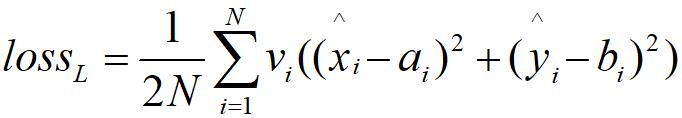
xi,yi是第i個被網路預測的關鍵點標記,N是關鍵點個數(在本文中,利用AFLW是21個),vi是可見因子,它只能是1或者0,當為1時,代表該關鍵點可見,0的時候代表關鍵點不可見。因為影象中會出現偏著頭的情況,例如上圖中關鍵點有可能沒有全部被標註。
3.3Testing
我們使用selective search來選出區域,
在最後兩步中,Hyperface加入了兩步演算法第一個是IPR,第二個是L-NMS(什麼是NMS)。
IRP(iterative region proposals):
我們使用selective search的快速版本,從一張圖片中抽取出兩千個區域,我們將此版本成為FAST_SS.
網路可能因為低分數而沒有檢測到部分人臉。因此需要一個更加精準的檢測器,我們由此發明了一個新的候選區域,這個候選區域來源於預測關鍵點,通過使用了FaceRectCalculator提供的預測關鍵點(AFLW人臉資料庫提供21個人臉關鍵點)。
L-NMS:傳統的NMS方法,是採用選取分數最高的區域,並拋掉分數超過閾值的區域,去除冗雜區域,如下圖所示。

傳統方法有兩個缺點:
1.如果對於一張相同的臉來說,該區域有著最高的分數,較少的重複度,那麼有可能被認為是一個單獨分開的人臉。
2.最高得分的區域,可能不是每次都精準的定位到人臉上,如果兩張臉靠的很近,可能會有矛盾。
為了克服這些困難,我們提出了新的演算法L-NMS。
我們在一個新的區域上,邊界為
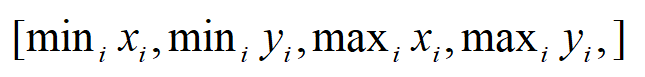
其演算法步驟為:

- 獲取檢測區域
- 獲取檢測區域區域的基準值
- 精準區域的座標位置,獲取上述1的四個值
- 從與區域重疊中提取人臉
- 對每張人臉進行迭代
- 獲取最高值的前K個區域
- 中和前K個區域的值
- 確定最終的姿態(根據前K個)
- 獲取最終性別
- 獲取最終可見度
- 獲取最終的區域
- 演算法結束