
《推薦系統實踐》第八章 評分預測問題
TopN推薦,即給定一個使用者,如何給他生成一個長度為N的推薦列表,使該推薦列表能夠儘量滿足使用者的興趣和需求。TopN推薦非常接近於滿足實際系統的需求,實際系統絕大多數情況下就是給使用者提供一個包括N個物品的個性化推薦列表。
評分預測問題最基本的資料集就是使用者評分資料集。該資料集由使用者評分記錄組成,每一條評分記錄是一個三元組(u,i, r),表示使用者u給物品i賦予了評分r,本章用表示使用者u對物品i的評分。因為使用者不可能對所有物品都評分,因此評分預測問題就是如何通過已知的使用者歷史評分記錄預測未知的使用者評分記錄。
8.1 離線實驗方法
評分預測問題基本都通過離線實驗進行研究。在給定使用者評分資料集後,研究人員會將資料集按照一定的方式分成訓練集和測試集,然後根據訓練集建立使用者興趣模型來預測測試集中的使用者評分。對於測試集中的一對使用者和物品(u, i),使用者u對物品i的真實評分是

評分預測的目的就是找到最好的模型最小化測試集的RMSE。
8.2 評分預測演算法
8.2.1 平均值
最簡單的評分預測演算法是利用平均值預測使用者對物品的評分的。
1. 全域性平均值
它的定義為訓練集中所有評分記錄的評分平均值:

而最終的預測函式可以直接定義為:![]()
2. 使用者評分平均值
使用者u的評分平均值定義為使用者u在訓練集中所有評分的平均值:
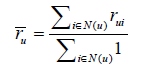
而最終的預測函式可以定義為:![]()
3. 物品評分平均值
物品i的評分平均值定義為物品i在訓練集中接受的所有評分的平均值:
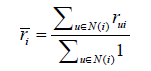
而最終的預測函式可以定義為:![]()
4. 使用者分類對物品分類的平均值
假設有兩個分類函式,一個是使用者分類函式,一個是物品分類函式
。
定義了使用者u所屬的類,
定義了物品i所屬的類。那麼,我們可以利用訓練集中同類使用者對同類物品評分的平均值預測使用者對物品的評分,即:

前面提出的全域性平均值,使用者評分平均值和物品評分平均值都是類類平均值的一種特例。
如果定義 = 0,
= 0,那麼
就是全域性平均值。
如果定義 = u,
= 0,那麼
就是使用者評分平均值。
如果定義 = 0,
= i ,那麼
就是物品評分平均值。
除了這3種特殊的平均值,在使用者評分資料上還可以定義很多不同的分類函式。
使用者和物品的平均分:對於一個使用者,可以計算他的評分平均分。然後將所有使用者按照評分平均分從小到大排序,並將使用者按照平均分平均分成N類。物品也可以用同樣的方式分類。
使用者活躍度和物品流行度:對於一個使用者,將他評分的物品數量定義為他的活躍度。得到使用者活躍度之後,可以將使用者通過活躍度從小到大排序,然後平均分為N類。物品的流行度定義為給物品評分的使用者數目,物品也可以按照流行度均勻分成N類。

8.2.2 基於鄰域的方法
基於使用者的鄰域演算法和基於物品的鄰域演算法都可以應用到評分預測中。
基於使用者的鄰域演算法認為預測一個使用者對一個物品的評分,需要參考和這個使用者興趣相似的使用者對該物品的評分,即:

S(u, K)是和使用者u興趣最相似的K個使用者的集合,N(i)是對物品i評過分的使用者集合, 是使用者v對物品i的評分,
是使用者v對他評過分的所有物品評分的平均值。
使用者之間的相似度可以通過皮爾遜係數計算:
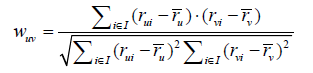
基於物品的鄰域演算法在預測使用者u對物品i的評分時,會參考使用者u對和物品i相似的其他物品的評分,即:

S(i, K)是和i最相似的物品集合,N(u)是使用者u評過分的物品集合, 是物品之間的相似度,
是物品i的平均分。
物品的相似度可以用以下方式進行計算。(參見Item-based Collaborative Filtering Recommendation Algorithms,http://files.grouplens.org/papers/www10_sarwar.pdf)
第一種是普通的餘弦相似度(cosine similarity):

第二種是皮爾遜係數(pearson correlation):
 ,
,是物品i的平均分。
第三種被Sarwar稱為修正的餘弦相似度(adjust cosine similarity):
 ,
, 是使用者u對他評過分的所有物品評分的平均值。
實驗結果表明利用修正後的餘弦相似度進行評分預測可以獲得最優的MAE。
8.2.3 隱語義模型與矩陣分解模型
在推薦系統領域,提的最多的就是潛語義模型和矩陣分解模型。其實,這兩個名詞說的是一回事,就是如何通過降維的方法將評分矩陣補全。
使用者的評分行為可以表示成一個評分矩陣R,其中R[u][i]就是使用者u對物品i的評分。但是,使用者不會對所有的物品評分,所以這個矩陣裡有很多元素都是空的,這些空的元素稱為缺失值(missing value)。因此,評分預測從某種意義上說就是填空,如果一個使用者對一個物品沒有評過分,那麼推薦系統就要預測這個使用者是否是否會對這個物品評分以及會評幾分。
1. 傳統的SVD分解
我們要找的是一種對矩陣擾動最小的補全方法。那麼什麼才算是對矩陣擾動最小呢?一般認為,如果補全後矩陣的特徵值和補全之前矩陣的特徵值相差不大,就算是擾動比較小。所以,最早的矩陣分解模型就是從數學上的SVD(奇異值分解)開始的。
給定m個使用者和n個物品,和使用者對物品的評分矩陣。首先需要對評分矩陣中的缺失值進行簡單地補全,比如用全域性平均值,或者使用者/物品平均值補全,得到補全後的矩陣R'。接著,可以用SVD分解將R'分解成如下形式:
![]()
其中,
是兩個正交矩陣,
是對角陣,對角線上的每一個元素都是矩陣的奇異值。為了對R'進行降維,可以取最大的f個奇異值組成對角矩陣
,並且找到這f個奇異值中每個值在U、V矩陣中對應的行和列,得到
、
,從而可以得到一個降維後的評分矩陣:
![]()
其中,就是使用者u對物品i評分的預測值。
SVD分解具有以下缺點,因此很難在實際系統中應用。
該方法首先需要用一個簡單的方法補全稀疏評分矩陣。一般來說,推薦系統中的評分矩陣是非常稀疏的,一般都有95%以上的元素是缺失的。而一旦補全,評分矩陣就會變成一個稠密矩陣,從而使評分矩陣的儲存需要非常大的空間,這種空間的需求在實際系統中是不可能接受的。
該方法依賴的SVD分解方法的計算複雜度很高,特別是在稠密的大規模矩陣上更是非常慢。一般來說,這裡的SVD分解用於1000維以上的矩陣就已經非常慢了.
2. Simon Funk的SVD分解
被Netflix Prize的冠軍Koren稱為Latent Factor Model(簡稱為LFM)。LFM在TopN推薦中的應用參見第二章。
從矩陣分解的角度說,如果我們將評分矩陣R分解為兩個低維矩陣相乘:
![]()
其中和
是兩個降維後的矩陣。那麼,對於使用者u對物品i的評分的預測值
,可以通過如下公式計算:
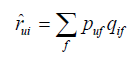
其中,
。那麼,Simon Funk的思想很簡單:可以直接通過訓練集中的觀察值利用最小化RMSE學習P、Q矩陣。
如果能找到合適的P、Q來最小化訓練集的預測誤差,那麼應該也能最小化測試集的預測誤差。因此,Simon Funk定義損失函式為:

直接優化上面的損失函式可能會導致學習的過擬合,因此還需要加入防止過擬合項,其中
是正則化引數,從而得到:
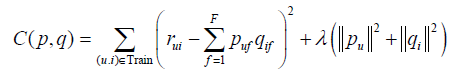
要最小化上面的損失函式,我們可以利用隨機梯度下降法。
上面定義的損失函式裡有兩組引數(puf和qif),最速下降法需要首先對它們分別求偏導數,可以得到:
其中,
根據隨機梯度下降法,需要將引數沿著最速下降方向向前推進,因此可以得到如下遞推公式:
其中,α是學習速率(learning rate),它的選取需要通過反覆實驗獲得。
下面的程式碼實現了學習LFM模型時的迭代過程。在LearningLFM函式中,輸入train是訓練集中的使用者評分記錄,F是隱類的個數,n是迭代次數。
def LearningLFM(train, F, n, alpha, lambda):
[p,q] = InitLFM(train, F)
for step in range(0, n):
for u,i,rui in train.items():
pui = Predict(u, i, p, q)
eui = rui - pui
for f in range(0,F):
p[u][f] += alpha * (q[i][f] * eui - lambda * p[u][f])
q[i][f] += alpha * (p[u][f] * eui - lambda * q[i][f])
alpha *= 0.9
return list(p, q)LearningLFM主要包括兩步。首先,需要對P、Q矩陣進行初始化,然後需要通過隨機梯度下降法的迭代得到最終的P、Q矩陣。在迭代時,需要在每一步對學習引數進行衰減(alpha *= 0.9),這是隨機梯度下降法演算法要求的,其目的是使演算法儘快收斂。
初始化P、Q矩陣的方法很多,一般都是將這兩個矩陣用隨機數填充,但隨機數的大小還是有講究的,根據經驗,隨機數需要和1/sqrt(F)成正比。
def InitLFM(train, F):
p = dict()
q = dict()
for u, i, rui in train.items():
if u not in p:
p[u] = [random.random()/math.sqrt(F) for x in range(0,F)]
if i not in q:
q[i] = [random.random()/math.sqrt(F) for x in range(0,F)]
return list(p, q)而預測使用者u對物品i的評分可以通過如下程式碼實現:
def Predict(u, i, p, q):
return sum(p[u][f] * q[i][f] for f in range(0,len(p[u]))3. 加入偏置項後的LFM
LFM預測公式通過隱類將使用者和物品聯絡在了一起。但是,實際情況下,一個評分系統有些固有屬性和使用者物品無關,而使用者也有些屬性和物品無關,物品也有些屬性和使用者無關。因此,Netflix Prize中提出了另一種LFM,其預測公式如下:
![]()
這個預測公式中加入了3項 、
、
。本章將這個模型稱為BiasSVD。這個模型中新增加的三項的作用如下。
:訓練集中所有記錄的評分的全域性平均數。全域性平均數可以表示網站本身對使用者評分的影響。
:使用者偏置(user bias)項。這一項表示了使用者的評分習慣中和物品沒有關係的那種因素。
:物品偏置(item bias)項。這一項表示了物品接受的評分中和使用者沒有什麼關係的因素。
增加的3個引數中,只有、
是要通過機器學習訓練出來的。同樣可以求導,然後用梯度下降法求解這兩個引數。此時損失函式為:
求偏導:
其中,
遞推公式:
我們對LearningLFM稍做修改,就可以支援BiasLFM模型:
def LearningBiasLFM(train, F, n, alpha, lambda, mu):
[bu, bi, p,q] = InitBiasLFM(train, F)
for step in range(0, n):
for u,i,rui in train.items():
pui = Predict(u, i, p, q, bu, bi, mu)
eui = rui - pui
bu[u] += alpha * (eui - lambda * bu[u])
bi[i] += alpha * (eui - lambda * bi[i])
for f in range(0,F):
p[u][f] += alpha * (q[i][f] * eui - lambda * p[u][f])
q[i][f] += alpha * (p[u][f] * eui - lambda * q[i][f])
alpha *= 0.9
return list(bu, bi, p, q)而、
在一開始只要初始化成全0的向量。
def InitBiasLFM(train, F):
p = dict()
q = dict()
bu = dict()
bi = dict()
for u, i, rui in train.items():
bu[u] = 0
bi[i] = 0
if u not in p:
p[u] = [random.random()/math.sqrt(F) for x in range(0,F)]
if i not in q:
q[i] = [random.random()/math.sqrt(F) for x in range(0,F)]
return list(p, q)
def Predict(u, i, p, q, bu, bi, mu):
ret = mu + bu[u] + bi[i]
ret += sum(p[u][f] * q[i][f] for f in range(0,len(p[u]))
return ret4. 考慮鄰域影響的LFM
前面的LFM模型中並沒有顯式地考慮使用者的歷史行為對使用者評分預測的影響。為此,Koren在Netflix Prize比賽中提出了一個模型(參見Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model ,http://www.cs.rochester.edu/twiki/pub/Main/HarpSeminar/Factorization_Meets_the_Neighborhood-_a_Multifaceted_Collaborative_Filtering_Model.pdf),將使用者歷史評分的物品加入到了LFM模型中,Koren將該模型稱為SVD++。
如何將基於鄰域的方法也像LFM那樣設計成一個可以學習的模型,我們可以將ItemCF的預測演算法改成如下方式:
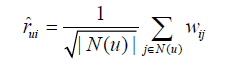
這裡,不再是根據ItemCF演算法計算出的物品相似度矩陣,而是一個和P、Q一樣的引數,它可以通過優化如下的損失函式進行優化:

不過,這個模型有一個缺點,就是w將是一個比較稠密的矩陣,儲存它需要比較大的空間。此外,如果有n個物品,那麼該模型的引數個數就是個,這個引數個數比較大,容易造成結果的過擬合。因此,Koren提出應該對w矩陣也進行分解,將引數個數降低到2*n*F個,模型如下:

這裡, 、
是兩個F維的向量。由此可見,該模型用
代替了
,從而大大降低了引數的數量和儲存空間。
再進一步,我們可以將前面的LFM和上面的模型相加,從而得到如下模型:

Koren又提出,為了不增加太多引數造成過擬合,可以令x = q,從而得到最終的SVD++模型:
此時,損失函式為
求偏導:
其中,
遞推公式:
def LearningSVDPlusPlus(train_ui, F, n, alpha, lambda, mu):
[bu, bi, p, q, y] = InitSVDPlusPlus(train, F)
z = dict()
for step in range(0, n):
for u,items in train_ui.items():
z[u] = p[u]
ru = 1 / math.sqrt(1.0 * len(items))
for i,rui in items items():
for f in range(0,F):
z[u][f] += y[i][f] * ru
sum = [0 for i in range(0,F)]
for i,rui in items.items():
pui = Predict(u, i, p, q, bu, bi, mu, z)
eui = rui - pui
bu[u] += alpha * (eui - lambda * bu[u])
bi[i] += alpha * (eui - lambda * bi[i])
for f in range(0,F):
sum[f] += q[i][f] * eui * ru
p[u][f] += alpha * (q[i][f] * eui - lambda * p[u][f])
q[i][f] += alpha * ((z[u][f] + p[u][f]) * eui - lambda * q[i][f])
for i,rui in items.items():
for f in range(0,F):
y[i][f] += alpha * (sum[f] - lambda * y[i][f])
alpha *= 0.9
return list(bu, bi, p, q, y)
def Predict(u, i, p, q, bu, bi, mu, z):
ret = mu + bu[u] + bi[i]
ret += sum(p[u][f] * q[i][f] for f in range(0,len(p[u]))
ret += sum(q[i][f] * z[u][f] for f in range(0, len(q[i])))
return ret8.2.4 加入時間資訊
利用時間資訊的方法也主要分成兩種,一種是將時間資訊應用到基於鄰域的模型中,另一種是將時間資訊應用到矩陣分解模型中。
1. 基於鄰域的模型融合時間資訊
Netflix Prize的參賽隊伍BigChaos在技術報告中提出了一種融入時間資訊的基於鄰域的模型,本節將這個模型稱為TItemCF。該演算法通過如下公式預測使用者在某一個時刻會給物品什麼
評分:

這裡, 是使用者u對物品i和物品j評分的時間差,
是物品i和j的相似度,
是一個考慮了時間衰減後的相似度函式,它的主要目的是提高使用者最近的評分行為對推薦結果的影響,BigChaos在模型中採用瞭如下的f :
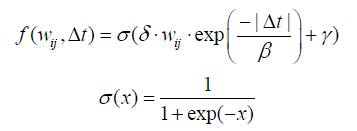
是sigmoid函式,它的目的是將相似度壓縮到(0,1)區間中。
隨著增加,
會越來越小,也就是說使用者很久之前的行為對預測使用者當前評分的影響越來越小。
2. 基於矩陣分解的模型融合時間資訊
在引入時間資訊後,使用者評分矩陣不再是一個二維矩陣,而是變成了一個三維矩陣。不過,我們可以仿照分解二維矩陣的方式對三維矩陣進行分解。我們可以將使用者—物品—時間三維矩陣如下分解:

這裡建模了系統整體平均分隨時間變化的效應,
建模了使用者平均分隨時間變化的效應,
建模了物品平均分隨時間變化的效應,而
建模了使用者興趣隨時間影響的效應。這個模型也可以很容易地利用前面提出的隨機梯度下降法進行訓練。本章將這個模型記為TSVD。
Koren在SVD++模型的基礎上也引入了時間效應②,回顧一下SVD++模型:

我們可以對這個模型做如下改進以融合時間資訊:

這裡,是使用者所有評分的平均時間。period(t)考慮了季節效應,可以定義為時刻t所在的月份。該模型同樣可以通過隨機梯度下降法進行優化。
8.2.5 模型融合
1. 模型級聯融合
假設已經有一個預測器,對於每個使用者—物品對(u, i)都給出預測值,那麼可以在這個預測器的基礎上設計下一個預測器
來最小化損失函式:

該方法每次產生一個新模型,按照一定的引數加到舊模型上去,從而使訓練集誤差最小化。每次都還是利用全樣本集進行預測,但每次使用的模型都有區別。
一般來說,級聯融合的方法都用於簡單的預測器,比如前面提到的平均值預測器。

由此可見,即使是利用簡單的演算法進行級聯融合,也能得到比較低的評分預測誤差。
2. 模型加權融合
假設我們有K個不同的預測器{ ,
, ...,
},本節主要討論如何將它們融合起來獲得最低的預測誤差。
最簡單的融合演算法就是線性融合,即最終的預測器ˆr 是這K個預測器的線性加權:

一般來說,評分預測問題的解決需要在訓練集上訓練K個不同的預測器,然後在測試集上作出預測。但是,如果我們繼續在訓練集上融合K個預測器,得到線性加權係數,就會造成過擬合的問題。因此,在模型融合時一般採用如下方法。
假設資料集已經被分為了訓練集A和測試集B,那麼首先需要將訓練集A按照相同的分割方法分為A1和A2,其中A2的生成方法和B的生成方法一致,且大小相似。
在A1上訓練K個不同的預測器,在A2上作出預測。因為我們知道A2上的真實評分值,所以可以在A2上利用最小二乘法計算出線性融合係數k。
在A上訓練K個不同的預測器,在B上作出預測,並且將這K個預測器在B上的預測結果按照已經得到的線性融合係數加權融合,以得到最終的預測結果。
除了線性融合,還有很多複雜的融合方法,比如利用人工神經網路的融合演算法。其實,模型融合問題就是一個典型的迴歸問題,因此所有的迴歸演算法都可以用於模型融合。
8.2.6 Netflix Prize的相關實驗結果

② 參見Arkadiusz Paterek的“Improving regularized singular value decomposition for collaborative filtering”(ACM International Conference on Knowledge Discovery and Data Mining,2007,39-42。
③ 同上。
④ 參見Yehuda Koren的“Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model”(ACM SIGKDD international conference on Knowledge discovery and data mining,2008,426-434。
⑤ 參見Yehuda Koren的“Collaborative Filtering with Temporal Dynamics”(ACM 2009 Article,2009)。