
Hadoop的三種配置模式以及免密登入
本地模式
特點:只需要一臺伺服器,沒有HDFS、只能測試 MapReduce 程式,MapReduce 處理的是本地 Linux 的檔案資料。
配置步驟:
-
修改 hadoop-2.7.3/etc/hadoop 目錄下的 hadoop-env.sh 檔案,在第 25 行做如下修改(配置JAVA_HOME):
export JAVA_HOME=/root/training/jdk1.8.0_144 -
測試 MapReduce 程式:
2.1. 建立目錄 mkdir ~/input 作為測試資料的存放目錄。
2.2. 在 input 目錄下建立 data.txt 檔案,內容如下:
I love Beijing I love China Beijing is the capital of China2.3. 執行 hadoop 自帶的一個 MapRecue 程式中的詞頻統計程式:
首先切換到 /root/training/hadoop-2.7.3/share/hadoop/mapreduce/ 目錄下。
執行如下命令:
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ~/input ~/output該命令會執行 hadoop-mapreduce-examples-2.7.3.jar 中的 wordcount 程式,統計 ~/input 目錄下所有檔案中所有單詞出現的頻率,結果會儲存到 ~/output 目錄下。
注:不要事先建立 ~/output 目錄,否則程式會丟擲異常,程式在執行的時候會自動建立 ~/output 目錄。
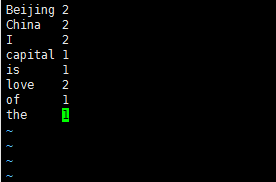
2.4. 執行成功的話會在 ~/output 目錄下產生兩個檔案:part-r-00000,_SUCCESS。_SUCCESS 這個檔案是一個空檔案,出現這個檔案說明詞頻統計成功。part-r-00000 這個檔案裡面儲存的是 ~/input 目錄下每個單詞出現的次數,內容如下:
偽分佈模式
特點:只需要一臺伺服器,模擬一個分散式的環境,具備 Hadoop 的主要功能。
配置步驟:
-
修改 hadoop-2.7.3/etc/hadoop 目錄下的 hadoop-env.sh
檔案,在第 25 行做如下修改(配置JAVA_HOME):export JAVA_HOME=/root/training/jdk1.8.0_144 -
修改 hdfs-site.xml 檔案,新增的內容如下:
<!-- 原則:一般資料塊的冗餘度跟資料節點(DataNode)的個數一致;最大不超過3 --> <!--表示資料塊的冗餘度,預設:3--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--是否開啟HDFS的許可權檢查,預設true,先不設定--> <property> <name>dfs.permissions</name> <value>false</value> </property> -
修改 core-site.xml 檔案,新增內容如下:
<!--配置NameNode地址,9000是RPC通訊埠--> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata111:9000</value> </property> <!--HDFS資料儲存在Linux的哪個目錄,預設值是Linux的tmp目錄--> <property> <name>hadoop.tmp.dir</name> <value>/root/training/hadoop-2.7.3/tmp</value> <!-- 該目錄必須事先建立 --> </property> -
修改 mapred-site.xml 檔案,新增內容如下:
<!--MapReduce程式執行在yarn裡面--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>注:hadoop-2.7.3/etc/hadoop/ 目錄下預設是沒有 mapred-site.xml 檔案的,需要複製一份 mapred-site.xml.template 檔案,執行如下命令:
cp mapred-site.xml.template mapred-site.xml。 -
修改 yarn-site.xml 檔案,新增內容如下:
<!--Yarn的主節點ResourceManager的位置--> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata111</value> </property> <!--MapReduce執行方式:shuffle洗牌--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
格式化 HDFS:
執行命令:
hdfs namenode -format看到列印的日誌中顯示:Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted 就說明格式化成功。
-
啟動停止 Hadoop 環境:
啟動:
start-all.sh停止:
stop-all.shps:啟動和停止 Hadoop 都會讓你輸入四次當前伺服器的密碼。因此我們需要配置免密碼登入伺服器。
免密碼登入
原理
使用非對稱加密演算法。

-
從 ServerA 登入到 ServerB。
-
ServerB 隨機產生一個字串,使用 ServerA 給的公鑰進行加密。
-
ServerB 把加密後的字串發給 ServerA。
-
ServerA 用私鑰解密收到的字串。
-
ServerA 將解密後的字串回發給ServerB。
-
ServerB 將收到的字串與最開始生成的字串對比,匹配則直接登入,不匹配則需要 ServerA 重新輸入密碼進行登入。
配置
-
使用
ssh-keygen -t rsa命令產生一個金鑰對:公鑰(給別人,用於加密),私鑰(給自己,用於解密)。 -
在當前使用者的家目錄下會產生一個 .ssh 隱藏目錄,裡面會產生兩個檔案:id_rsa(私鑰),id_rsa.pub(公鑰)。
-
把公鑰拷貝給要登入的伺服器:
ssh-copy-id -i .ssh/id_rsa.pub [email protected] -
在對方伺服器的 .ssh/ 目錄下就會多一個 authorized_keys 檔案,裡面儲存著別的伺服器發來的所有公鑰。
-
-
通過 Web 介面訪問:
HDFS:http://192.168.220.111:50070
Yarn:http://192.168.220.111:8088ps:具體的伺服器地址取決於自己的配置。
記錄下這歷史性的一刻:


ps:再執行一下之前那個 wordcount 程式,看看會發生什麼。
丟擲異常,原因:原來資料的目錄時本地 Linux 上的,現在已經開啟偽分散式模式,需要使用 HDFS 的目錄。
hdfs dfs -mkdir /input,該命令會在 HDFS 的根目錄 / 下建立一個 input 目錄。(執行該命令時,需要啟動 HDFSstart-all.sh)hdfs dfs -put ~/input/data.txt /input,該命令會把我們本地的 ~/input/data.txt 檔案上傳到 HDFS 的 /input 目錄下。- 檢視 HDFS 根目錄下的檔案:
hdfs dfs -ls /。 - 檢視 HDFS 根目錄下的檔案(包含子目錄):
hdfs dfs -lsr /。 - 執行原來的 mapreduce 程式:
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output/1117,該命令會讀取 HDFS 的 /input 目錄下的 data.txt 檔案,進行詞頻統計,統計的結果會輸出到 HDFS 的 /output/1117 目錄下。 - 在程式執行的過程中可以訪問:http://192.168.220.111:8088/ 檢視執行中的 mapreduce 程式。
- 最後程式執行完畢,執行
hdfs dfs -ls /output/1117檢視裡面生成的檔案內容。
全分佈模式
特點:需要多臺伺服器構建叢集,真正的分散式環境,用於生產。
準備工作
-
關閉防火牆:
本次停止:
systemctl stop firewalld.service
永久關停:systemctl disable firewalld.service -
安裝JDK
-
為叢集中的每臺機器配置IP到主機名的對映:
192.168.220.112 bigdata112 192.168.220.113 bigdata113 192.168.220.114 bigdata114 -
配置免密碼登入,兩兩之間都要配置
4.1. 每臺機器產生自己的公鑰和私鑰:
ssh-keygen -t rsa4.2. 每臺機器把自己的公鑰給別人和自己:
ssh-copy-id -i .ssh/id_rsa.pub [email protected] ssh-copy-id -i .ssh/id_rsa.pub [email protected] ssh-copy-id -i .ssh/id_rsa.pub [email protected] -
保證每臺機器的時間同步:
同時向三個終端傳送如下命令:
date -s "2018-11-18 14:47:57",來協調時間的一致,如果時間不一致,後續在執行 mapreduce 程式的時候有可能出現問題。
在主節點上進行安裝
-
解壓 tar 包,向 .bash_profile 中設定 Hadoop 的環境變數:
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
叢集中的每臺機器都要設定環境變數
HADOOP_HOME=/root/training/hadoop-2.7.3 export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export PATH -
修改 hadoop-env.sh 檔案,將第 25 行的內容修改為:
export JAVA_HOME=/root/training/jdk1.8.0_144 -
修改 hdfs-site.xml 檔案:
<!--表示資料塊的冗餘度,預設:3--> <property> <name>dfs.replication</name> <value>2</value> </property> -
修改 core-site.xml 檔案:
<!--配置NameNode地址,9000是RPC通訊埠--> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata112:9000</value> </property> <!--HDFS資料儲存在Linux的哪個目錄,預設值是Linux的tmp目錄--> <property> <name>hadoop.tmp.dir</name> <value>/root/training/hadoop-2.7.3/tmp</value> </property> -
拷貝 mapred-site.xml.template 生成一份 mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml修改內容如下:
<!--MR執行的框架--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> -
修改 yarn-site.xml 檔案:
<!--Yarn的主節點RM的位置--> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata112</value> </property> <!--MapReduce執行方式:shuffle洗牌--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
修改 slaves 檔案,配置從機的位置:
bigdata113 bigdata114 -
格式化 namenode:
hdfs namenode -format -
把主節點上配置好的 hadoop 複製到從節點上:
scp -r hadoop-2.7.3/ [email protected]:/root/training scp -r hadoop-2.7.3/ [email protected]:/root/training -
在主節點上啟動:
start-all.sh值得紀念的一刻:

也可以通過執行
hdfs dfsadmin -report命令,檢視 HDFS 的 namenode 和 datanode 節點的狀態。[[email protected] ~]# hdfs dfsadmin -report Configured Capacity: 100865679360 (93.94 GB) Present Capacity: 96658509824 (90.02 GB) DFS Remaining: 96658493440 (90.02 GB) DFS Used: 16384 (16 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (2): Name: 192.168.220.113:50010 (bigdata113) Hostname: bigdata113 Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 8192 (8 KB) Non DFS Used: 2103767040 (1.96 GB) DFS Remaining: 48329064448 (45.01 GB) DFS Used%: 0.00% DFS Remaining%: 95.83% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sun Nov 18 15:05:23 CST 2018 Name: 192.168.220.114:50010 (bigdata114) Hostname: bigdata114 Decommission Status : Normal Configured Capacity: 50432839680 (46.97 GB) DFS Used: 8192 (8 KB) Non DFS Used: 2103402496 (1.96 GB) DFS Remaining: 48329428992 (45.01 GB) DFS Used%: 0.00% DFS Remaining%: 95.83% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sun Nov 18 15:05:23 CST 2018
安裝過程中出現的問題
-
value 標籤錯寫成 valual,導致執行 start-all.sh 的時候拋異常。
-
之前在主節點上搭建了偽分散式環境,已經格式化了 hdfs,導致在搭建全分散式環境啟動 HDFS 和 Yarn 的時候,從節點雖然已啟動了 DataNode 程序但是在 web 頁面上卻顯示存活的節點數為 0。按照網上的教程,刪除儲存資料的目錄,重新格式化無果。刪除 hadoop 重灌,問題解決。
全分佈模式最終的叢集結構
