
【Python例項第16講】特徵集聚
阿新 • • 發佈:2018-11-29
機器學習訓練營——機器學習愛好者的自由交流空間(qq 群號:696721295)
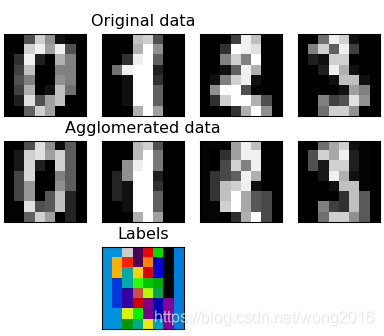
本例演示如何使用特徵集聚(feature agglomeration)將相似的特徵合併到一起。所謂“特徵集聚”,是指迭代地將相似的特徵合併到一起,類似於聚類,但這裡聚的是特徵而不是樣本。本例使用的資料集是手寫數字識別資料集。
例項詳解
首先,匯入必需的庫。
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, cluster from sklearn.feature_extraction.image import grid_to_graph
匯入手寫數字資料集digits, 它是一個三維陣列(1797, 8, 8). 即,有1797個手寫數字,每個數字由8*8的畫素矩陣組成。在這裡,我們使用numpy庫的reshape函式將它變成(1797, 64)的二維陣列。
digits = datasets.load_digits()
images = digits.images
X = np.reshape(images, (len(images), -1))
connectivity = grid_to_graph(*images[0].shape)
使用cluster模組的FeatureAgglomeration方法進行特徵集聚。在這裡,指定聚類數為32,每個特徵的鄰居特徵的連線形式由引數connectivity
agglo = cluster.FeatureAgglomeration(connectivity=connectivity, n_clusters=32) agglo.fit(X) X_reduced = agglo.transform(X) X_restored = agglo.inverse_transform(X_reduced) images_restored = np.reshape(X_restored, images.shape)
最後,視覺化特徵集聚後的手寫數字影象。
plt.figure(1, figsize=(4, 3.5))
plt.clf()
plt.subplots_adjust(left=.01, right=.99, bottom=.01, top=.91)
for i in range(4):
plt.subplot(3, 4, i + 1)
plt.imshow(images[i], cmap=plt.cm.gray, vmax=16, interpolation='nearest')
plt.xticks(())
plt.yticks(())
if i == 1:
plt.title('Original data')
plt.subplot(3, 4, 4 + i + 1)
plt.imshow(images_restored[i], cmap=plt.cm.gray, vmax=16,
interpolation='nearest')
if i == 1:
plt.title('Agglomerated data')
plt.xticks(())
plt.yticks(())
plt.subplot(3, 4, 10)
plt.imshow(np.reshape(agglo.labels_, images[0].shape),
interpolation='nearest', cmap=plt.cm.nipy_spectral)
plt.xticks(())
plt.yticks(())
plt.title('Labels')
plt.show()
閱讀更多精彩內容,請關注微信公眾號:統計學習與大資料