
增強學習理解(一):概念介紹
一、增強學習概念
增強學習特點:
增強學習是機器學習的一種,機器學習主要分為監督學習、非監督學習、半監督學習,增強學習就是讓計算機學著自己去做事情,進行自學習,人只需要給計算機設定一個“小目標”,具體的策略就需要計算機自己去設計啦!
- 跟增強學習相關的例子
- 動態規劃法
逐步去找出最優子結構的狀態,然後找到這些狀態求解的先後順序,在狀態之間構成一個有向無環圖,來一步步求解最後的問題。
2.PageRank演算法
Google最先使用的網頁排序演算法,搜尋引擎需要對網頁進行排序,越重要的網頁排名越靠前,有越多的網站指向這個網頁就越重要。
PageRank演算法使用迭代方法解決了這個問題,首先將網頁的權重設成一樣的,然後計算一圈,很多網頁的權重和一開始不一樣了,這時候使用這個計算出來的權重再計算一次,最後結果是收斂的。
- 例子
把機器人放在一個陌生的環境中,希望機器人自己能夠到目標房間中去。
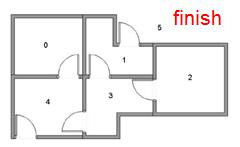
使用傳統方法會通過搜尋,或是記憶化的搜尋(動態規劃)找出全域性的佈局。
我們首先設定下目標房間的權重,即我們給它一個獎勵,當機器人走到目標房間時,就會給它對應的獎勵。寫出狀態之間切換的權重以及權重矩陣。


一步一步的對相鄰的房間也賦予權重,通過迭代訓練,只要機器人向當前結點周圍分值最高的點走過去就可以找到目標房間。
- 增強學習介紹
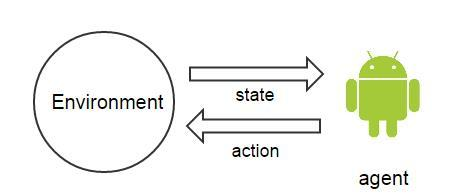
增強學習的特點是,從現有的狀態出發,不斷的優化自己的策略,過程中使用到了agent(主體)、environment(主體所處的環境)、episode(一個完整的訓練的階段,即訓練開始到結束)、step(一個episode中的一個操作)、state(主體當前所處的狀態)、action(要採取的操作是什麼)、value(採取的每個動作,所具有的價值)。

Agent和environment是最基本的互動,agent觀察environment的狀態,然後做出一個action,environment接收action又產生新的狀態。Agent只能獲得它觀測到的資料,不能有上帝視角。
- 增強學習的數學表示:
使用S表示狀態集合,A表示行為集合,π作為策略。當採取策略π時,根據當前狀態來選擇下一刻的行為:a=π(s)
對於狀態中的每一個狀態s,都有對應的回報值R(s)與之對應;對於狀態序列中的每下一個狀態,設定一個衰減係數γ;對於每一個策略π,設定一個相應的權值函式Vπ(S0)=E[R(S0)+γR(S1)+γ2R(S2)+…|S0=S,π]
這個表示式滿足Bellman-Ford Equation,即可簡化為Vπ(S0)=E[R(S0)+γVπ(S1)]
- 用大白話來講就是,需要知道當前狀態的價值是多少,從而選擇最大化價值的那個狀態來進行操作,當前狀態的價值,就是之後所有價值的疊加,越往後,噪聲越大,這就需要讓他們的權重減小。後面所有狀態的價值和,又可以寫成下一狀態的價值。當前狀態的回報值reward可以直接獲得,我們只需要計算下一狀態的權值函式就可以,這一點,我們需要神經網路來進行計算。
二、增強學習的策略
場景假設:在一個遊戲當中,可以向前後左右四個方向移動,想要知道往哪個方向走收益最大
1、蒙特卡洛方法
蒙特卡洛方法是一個暴力、直觀的方法,策略就是對所有可能的結果求平均,當我們選擇向“前”走了以後,再做一個action,根據這個式子,直到episode結束,求出收益的和,就是向前走這個動作的取樣。我們再不斷的在這個狀態取樣,然後求平均,等到取樣非常非常多的時候,統計值就會非常的接近期望值了。
2、動態規劃法
當我們要確定向前走這個動作的收益的時候,就把它所有的子問題全部都計算完成,然後取最大值,就是其收益,好處就是效率高,但缺點就是需要子結構的問題時有向無環圖。
3、Temporal Difference(時間差分)
簡稱TD,是蒙特卡洛方法的簡化,也是實際應用中最多的一種演算法。當計算向前走這個動作的收益的時候,是當前狀態的reward值加上轉移到後繼狀態的期望值,我們觀測前面的狀態,剩下的價值不真正的去計算,用神經網路去估算,這就是TD(0)演算法。
三、用神經網路對狀態進行估算
神經網路具體怎麼工作,就像一個黑盒子,輸入是一個狀態,輸出的是這個狀態的價值。
沒有訓練資料?
這個演算法最牛的地方在於,整個系統在運作過程中,通過現有的策略,產生了一些資料,獲得的這些資料在計算回報值Reward的時候,會有所修正,我們把修正的值和狀態,作為神經網路的輸入,再進行訓練,最後的結果顯示,這樣做是可以收斂的。
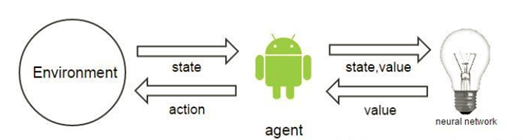
神經網路的運用包括訓練和預測兩部分,訓練的時候輸入的是狀態和這個狀態的value值,預測時候輸入時狀態,輸出的是估算的value值。
4、演算法的整個流程
我們採用TD(0)作為狀態的計算,神經網路作為狀態價值的估算的這套演算法,叫做Q-Learning演算法,如果我們採用epsilon-greedy方法,主要流程如下:

epsilon-greedy方法取決於任務,選擇每個動作的概率是一樣的,soft-max Action Selection方法給予了不同動作不同的概率,給greedy action最大的概率,其他的動作根據其value大小,按概率進行選擇。最不合適的行為概率最小。
演算法評價:
Evaluative-feedback:得到的reward值會反映出這個行為有多好,不會告訴是正確的還是錯誤的。
Instructive-feedback:執行的結果會告訴這個行為是正確的還是錯誤的
像flyppy bird讓小鳥自行的進行遊戲,訓練過程當中,撞到柱子就獲得-1的回報值,否則獲得0回報,經過若干次的訓練,就會訓練出一隻技能高超的小鳥,它知道在什麼情況下躲避柱子。
又像設計一款國際象棋的軟體,不能使用監督學習的方法,通過增強學習,不斷的摸索和試錯行為,在每個狀態下選擇最有可能獲勝的棋步,在棋類遊戲中獲得了廣泛的應用。
增強學習,更接近於生物學習的本質,就像在訓練一個更高階的智慧機器人,通過神經網路的訓練,讓它有自學習的能力,有自己的思考。最終達到的效果就是,人們給它設定一個目標,讓它自主的去實現,感覺像是將人工智慧實現從智商到情商的跨越,如果再加上博弈機器學習思想,實現由個體智慧到社會智慧的飛躍。