
資料結構與算法系列13--二分查詢
什麼是二分查詢?
二分查詢演算法是一種針對有序集合的查詢演算法,也叫折半查詢。
實現原理
每次都通過跟區間的中間元素對比,將待查詢的區間縮小為之前的一半,直到找到要查詢的元素,或者區間被縮小為0。(特別注意前提是針對有序的資料集合)
時間複雜度
二分查詢是一種非常高效的查詢演算法,他的時間複雜度是O(logn),我們可以假設資料大小是n,每次查詢後資料都會縮小為原來的一半,也就是會除以2。最壞情況下,直到查詢區間被縮小為空,才停止。那麼被查詢的區間大小變化為:n,n/2,n/4,n/8…n/2^k,可以看出這是一個等比數列,其中n/2k=1時,k的值就是總共縮小的次數,而每一次縮小操作只涉及兩個資料的大小比較,所以,經過了k次區間縮小操作,時間複雜度就是O(k)。通過n/2k=1,我們可以求得
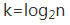
二分查詢的非遞迴實現
def bsearch(a,value): low=0 high=len(a)-1 while(low<=high): mid=(low+high)//2 if a[mid]==value: return mid elif a[mid]>value: high=mid-1 else: low=mid+1 return -1 a=[1,2,3,4,5,6] print(bsearch(a,6))
注意:
1.迴圈退出條件
注意是 low<=high,而不是 low<high。
2.mid的取值
mid的取值,使用mid=low + (high - low) / 2,而不用mid=(low + high)/2,因為如果low和high比較大的話,求和可能會發生int型別的值超出最大範圍。為了把效能優化到極致,可以將除以2轉換成位運算,即low + ((high - low) >> 1),因為相比除法運算來說,計算機處理位運算要快得多。
3.low和high的更新
low = mid - 1,high = mid + 1,若直接寫成low = mid,high=mid,就可能會發生死迴圈。比如,我們假設low=5,high=5,此時如果a[5]不等於value,那麼此時就會陷入死迴圈。
二分查詢的遞迴實現
def bsearch(a,value):
low=0
high=len(a)-1
return bsearchInternally(a,low,high,value)
def bsearchInternally(a,low,high,value):
if low>high:
return -1
mid=(low+high)//2
if a[mid]==value:
return mid
elif a[mid]>value:
high=mid-1
return bsearchInternally(a,low,high,value)
else:
low=mid+1
return bsearchInternally(a,low,high,value)
a=[1,2,3,4,5,6]
print(bsearch(a,5))
二分查詢應用場景的侷限性
雖然二分查詢速度很快,時間複雜度為O(logn),但是並不是什麼情況下都可以使用二分查詢。
1.二分查詢依賴的是順序表結構,即陣列。
那二分查詢能否依賴其他資料結構呢?比如連結串列。答案是不可以的,主要原因是二分查詢演算法需要按照下標隨機訪問元素,陣列按照下標隨機訪問資料的時間複雜度是O(1),而連結串列隨機訪問的時間複雜度是O(n)。所以,如果資料使用連結串列儲存,二分查詢的時間複雜就會變得很高。
2.二分查詢針對的資料集合必須是有序的
二分查詢針對的是有序資料,因此只能用在插入、刪除操作不頻繁,一次排序多次查詢的場景中。針對動態變化的資料集合,二分查詢將不再適用。那針對動態資料集合,如何在其中快速查詢某個資料呢?可以使用二叉樹,後續我們也會講到。
3.資料量太小不適合二分查詢
因為如果要處理的資料量很小,不管用二分查詢還是順序遍歷,查詢速度都差不多。優勢並不明顯。不過,這裡有一個例外。如果資料之間的比較操作非常耗時,不管資料量大小,我都推薦使用二分查詢。因為假如陣列中儲存的都是長度超過300的字串ao,如此長的兩個字串之間比對大小,就會非常耗時。我們需要儘可能地減少比較次數,而比較次數的減少會大大提高效能,這個時候二分查詢就比順序遍歷更有優勢。
4.資料量太大也不適合二分查詢
前面我們說到二分查詢需要依賴順序表結構,也即是陣列,而陣列是需要連續的儲存空間,如果要查詢的資料量非常大,往往找不到儲存如此大規模資料的連續記憶體空間。
二分查詢變形問題(重要):
前面我們講的是最簡單的一種二分查詢演算法。看起來還是比較簡單的,但是它的變形問題就比較複雜了。二分查詢的變形問題很多,這裡我們只講解幾個典型的例子:
- 查詢第一個值等於給定值的元素
- 查詢最後一個值等於給定值的元素
- 查詢第一個大於等於給定值的元素
- 查詢最後一個小於等於給定值的元素
查詢第一個值等於給定值的元素
def bsearch(a,value):
low=0
high=len(a)-1
while(low<=high):
mid=low+((high-low)>>1)
if a[mid]<value:
low=mid+1
elif a[mid]>value:
high=mid-1
else:
#這裡先判斷mid是否等於0,如果是說明是第一個了,另外如果mid不等於0,但a[mid]的前一個元素a[mid-1]不等於value,說明也是a[mid]就是我們要查詢的第一個等於value的元素
if (mid==0||a[mid-1]!=value):
return mid
else:
#如果經過檢查之後發現a[mid]前面的一個元素a[mid-1]也等於value,那就說明a[mid]肯定不是我們要查詢的第一個值等於value的元素。那我們就更新high的值,因為要查詢的元素肯定會出現在[low,mid-1]之間。
high=mid-1
return -1
a=[1,2,3,3,4,4,4,5,5,5,5]
print(bsearch(a,4))
同樣的思路,我們寫下查詢最後一個值等於給定值的元素
def bsearch3(a,value):
low=0
high=len(a)-1
while(low<=high):
mid=low+((high-low)>>1)
if a[mid]<value:
low=mid+1
elif a[mid]>value:
high=mid-1
else:
if ((mid==len(a)-1)or(a[mid+1]!=value)):
return mid
else:
low=mid+1
return -1
a=[1,2,3,3,4,4,4,5,5,5,5]
print(bsearch3(a,4))
查詢第一個大於等於給定值的元素:
def bsearch4(a,value):
low=0
high=len(a)-1
while(low<=high):
mid=low+((high-low)>>1)
if a[mid]>=value:
#注意這裡
if (a[mid]==0)or(a[mid-1]<value):
return mid
else:
high=mid-1
else:
low=mid+1
return -1
a=[1,2,5,6]
print(bsearch4(a,3))
查詢最後一個小於等於給定值的元素
def bsearch5(a,value):
low=0
high=len(a)-1
while(low<=high):
mid=low+((high-low)>>1)
if a[mid]<=value:
if (a[mid]==len(a)-1)or(a[mid+1]>value):
return mid
else:
low=mid+1
else:
high=mid-1
return -1
a=[1,2,5,9]
print(bsearch5(a,8))
二分查詢應用場景:
1.凡事能用二分查詢解決的,絕大部分我們更傾向於用散列表或者二叉查詢樹,即便二分查詢在記憶體上更節省,但是畢竟記憶體如此緊缺的情況並不多。
2.二分查詢適用於近似查詢,如第一個≥給定值的元素,第一個≤給定值的元素,都是二分查詢的變體。而一般情況下查詢某個給定值,二叉查詢樹和散列表更適合。