
位元組序問題的簡單理解
什麼是位元組序?
什麼是位元組序我就不再囉嗦了,這樣的文章在網上一搜一大片,而且很多寫的頗有水平。我主要參考了以下3篇文章:
位元組序詳解:https://blog.csdn.net/ce123_zhouwei/article/details/6971544
理解位元組序:http://www.ruanyifeng.com/blog/2016/11/byte-order.html
一篇英文部落格:https://blog.erratasec.com/2016/11/how-to-teach-endian.html#.XAID0JMzZsM
什麼情況下需要使用到位元組序相關的知識?
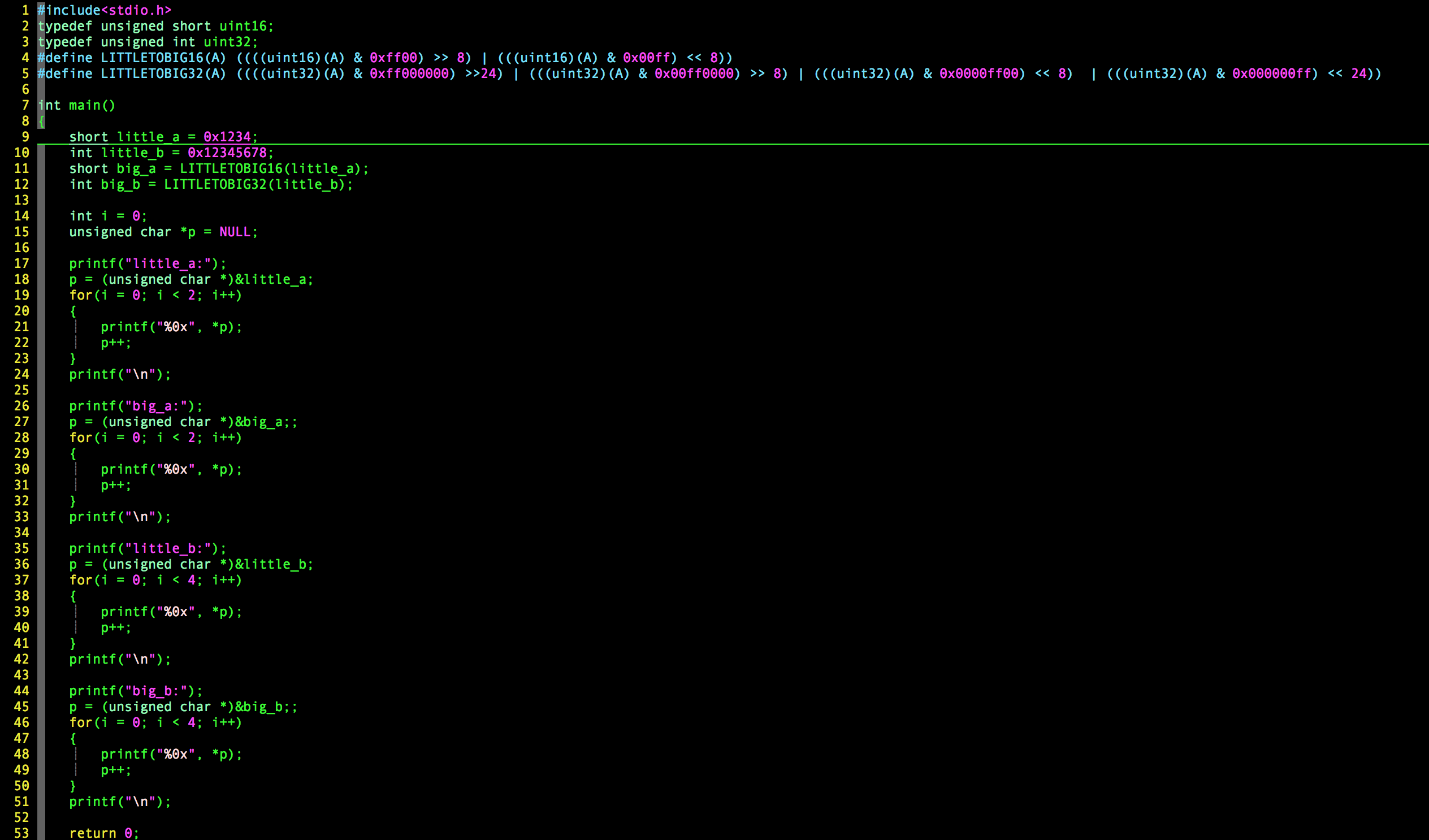
在常見的高階語言中,一定有和int相關的基礎型別。以32位環境下的C語言為例,如果一個數字大於255就必須要使用2個以上的位元組去儲存,比如short(2位元組)和int(4位元組)。對於short 0x1234來說,人們為了描述方便,0x12被叫做高位元組,0x34被叫做低位元組。假設從左到右是記憶體增長的方向,那麼小端環境下這個short的儲存方式是“0x34 0x12”,低地址存放低位元組,高地址存放高位元組。在大端環境下,這個short的存放方式是“0x12 0x34”,低地址存放高位元組,高地址存放低位元組。
現在假設一個場景。比如機器A是小端環境,機器B是大端環境,A通過socket TCP協議想把0x1234(10進製為4660)這個short發給B。使用socket傳送資料的原理就是指定一塊資料的起始地址和這塊資料的長度,然後socket從起始地址開始,把bit一位一位寫入TCP流中。對於short 0x1234來說,在A的記憶體中就是“0x34 0x12”, 轉換為二進位制就為“0011 0100 0001 0010”。當TCP資料流到達B後,B會把這串bit從低地址開始存放。也就是說,這串bit到了B之後,在記憶體中也是“0011 0100 0001 0010”。按照大端的解析記憶體方式,低地址存放的是高位元組,高地址存放的是低位元組,這串bit在B將會被解析為0x3412(十進位制為13330)。看到了吧,B把A想要傳遞的資訊給解析錯了。這就是大端小端之間傳遞資料由於架構不同而導致的問題。其實不光是socket,A和B通過檔案互動也是一個道理,因為檔案也是從記憶體的低地址開始,按順序寫入一定個數的bit。
怎麼解決位元組序的問題?
所有的解決方式原理都是一樣的,就是統一使用大端或者統一使用小端的方式去存取需要共享的int類資料。要麼A在傳輸之前,把小端的bit轉換為大端的bit。要麼就是B在接到A的資料之後,自己做一下從小端bit到大端bit的轉換操作。
c語言給我們提供了ntohs,htons,ntohl,htonl來從本機位元組序轉換為大端位元組序或者從大端位元組序轉換為本機位元組序。其他大部分的語言也有相應的實現。
這幾個函式的實現原理就是下圖中的程式碼:
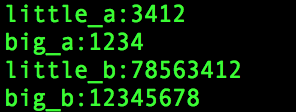
執行結果:
位元組序引起問題的例項:
<1> 解析kafka的日誌
kafka V1 日誌格式如下:

8位元組的offset + 4位元組的size + 上圖的結構
也就是說,如果我想要第一條訊息,只需要跳過前0~25個位元組,然後取第26~29位元組,就是key的長度。然後跳過對應key的長度,再取4位元組,就是payload的長度。
假設我生產的資訊key="key", value="hello";
我編寫程式碼的環境是小端位元組序,那麼我寫以下程式碼來解析kafka的log:

執行結果:

可以看到,如果使用小端的方式解析這個檔案,就會輸出錯誤的結果。但是使用大端,則返回了期望的結果
也就是說,kafka在把資料寫入檔案時,是以大端方式的位元組序列寫入檔案的,而我們讀取的時候如果使用小端的方式解析這串位元組序列,就會出現錯誤。
<2> 寫程式碼得到zip壓縮檔案中某個檔案的大小
zip包的格式可以參考這篇博文:https://blog.csdn.net/a200710716/article/details/51644421
有如下檔案:

將其進行zip壓縮:

寫如下程式碼進行解析:

執行結果:

可以看到,zip格式在儲存壓縮大小時候是使用小端的方式儲存的。