
行為識別論文整理(1)
謹以此片部落格開啟我的行為識別之路——養成記錄的好習慣
參考:https://github.com/Ewenwan/MVision/tree/master/CNN/Action_Recognition 以及無數部落格大佬們。
文章目錄
- 1、任務
- 2、研究進展
- 2.1、傳統方法
- 2.2、深度學習
- 2.2.1、Two-stream網路
- Two-Stream Convolutional Networks for Action Recognition in Videos(2014)
- Beyond Short Snippets: Deep Networks for Video Classification(2015)
- Convolutional Two-Stream Network Fusion for Video Action Recognition(2016)
- Temporal Segment Networks: Towards Good Practices for Deep Action Recognition(2016)
- Deep Local Video Feature for Action Recognition(2017)
- Temporal Relational Reasoning in Videos(2018)
- 2.2.2、3D網路
- Learning spatiotemporal features with 3d convolutional networks(2015)
- Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classificati(2017)
- Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks(2017)
- Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset(2017)
- 格式(2018)
1、任務
行為識別就是對時域預先分割好的序列判定其所屬行為動作的型別,即“讀懂行為”。注意行為識別和行為檢測的區別,在實現應用中更容易遇到的是序列尚未在時域分割,需要同時對行為動作進行時域定位(分割)和型別判斷,這類任務一般稱為行為檢測。
1.1、資料集介紹
快了…
2、研究進展
2.1、傳統方法
2.1.1 密度軌跡
Action Recognition by Dense Trajectories(2011)
Action recognition with improved trajectories(2013)
iDT演算法是行為識別領域中非常經典的一種演算法,在深度學習應用於該領域前也是效果最好的演算法。由INRIA的IEAR實驗室於2013年發表於ICCV。 DT論文 iDT論文
內容:
DT演算法利用光流場獲取視訊序列中的一些軌跡,沿著軌跡提取HOF、HOG、MBH和trajectory四種特徵。最後利用FV(Fisher Vector)方法對特徵進行編碼,再基於編碼結果訓練SVM分類器。而iDT改進的地方在於其利用前後幀視訊間的光流和SURF關鍵點進行匹配,從而消除/減弱相機運動帶來的影響。
模型:

說明:
A. 利用光流場來獲得視訊序列中的一些軌跡;
a. 通過網格劃分的方式在圖片的多個尺度上分別密集取樣特徵點,濾除一些變換少的點;
b. 計算特徵點鄰域內的光流中值來得到特徵點的運動速度,進而跟蹤關鍵點;
B. 沿軌跡提取HOF,HOG,MBH,trajectory,4種特徵
其中HOG基於灰度圖計算,另外幾個均基於稠密光流場計算。
a. HOG, 方向梯度直方圖,分塊後根據畫素的梯度方向統計畫素的梯度幅值。
b. HOF, 光流直方圖,光流通過當前幀梯度矩陣和相鄰幀時間上的灰度變換矩陣計算得
到,之後再對光流方向進行加權統計。
c. MBH,運動邊界直方圖,實質為光流梯度直方圖。即分別在影象的x和y方向光流影象上計算HOG特徵。
d. Trajectories, 軌跡特徵,特徵點在各個幀上位置點的差值,構成軌跡變化特徵。
2.2、深度學習
2.2.1、Two-stream網路
Two-Stream Convolutional Networks for Action Recognition in Videos(2014)
提出Two-stream時空雙流網路 論文
內容
首先計算連續兩幀間的稠密光流,然後將攜帶了場景和目標資訊的視訊幀和攜帶相機和目標運動資訊的光流分別訓練CNN模型,兩個網路分別對動作進行類別的判斷,最後對兩流的softmax分數採用平均或者SVM來計算。
程式碼
未公開
模型

實驗
UCF101-88.0%,HMDB51-59.4%

備註
時間流採用密集光流
Beyond Short Snippets: Deep Networks for Video Classification(2015)
論文
內容
論文中討論了兩種方法:
1)提取每一幀的深度卷積特徵,再使用不同的pooling層結構(見備註)進行特徵融合,得到最終輸出。
2)使用LSTM提取視訊序列上的全域性資訊,再加softmax層得到最終分類。
程式碼
未公開
模型

實驗

備註
1、對比了Conv Pooling、Late Pooling、Slow Pooling、Local Pooling、Time-Domain Convolution和GoogLeNet Conv Pooling等融合方法。實驗表明,上述方法效果都較差,說明一個時間域的卷積層對於在高階特徵上學習時間關係是無效的,進而使用LSTM從時間序列中學習。
2、沒有光流時,在UCF-101可以達到82.6%,加上光流後達到88.6%。
Convolutional Two-Stream Network Fusion for Video Action Recognition(2016)
論文
內容
在原雙流基礎上做了改進,原雙流網路時間和空間流在最後一步融合,結果取平均或SVM計算。本文將雙流網路都換成VGG-16網路,最後用一個卷積層融合雙流網路。
模型

實驗

備註
1、時間融合後使用單個流在UCF-101上可以達到91.8%,保持兩個流可以達到92.5%。前者引數要少很多。
2、將iDT方法的SVM評分與本文方法(softmax之前)預測進行平均,在UCF-101上取得93.5%,在HMDB-51取得69.2%。可以想象此方法的龜速。
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition(2016)
TSN網路提出,適用於長時間視訊的行為判斷。 論文
內容
視訊的連續幀之間存在冗餘,採用較為稀疏的抽幀方法去除冗餘資訊,同時減少計算量,具體做法:將視訊分成K個segments,從每個segment中隨機地選擇一個short snippet。將選擇的snippets通過BN-Inception (Inception with Batch Normalization)構建的two-stream卷積神經網路得到不同snippets的class scores,最後將它們融合。
通過常規的資料增加技術、regularization;還有作者提到的cross-modality pre-training,dropout等方式來減少過擬合,來彌補資料量的問題。還研究RGB difference和warped optical flow對動作檢測效果的影響。
程式碼
原始碼(caffe)
模型

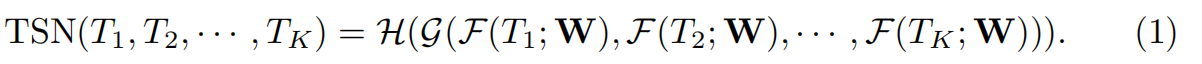
圖中綠色條形圖代表score在類別上的分佈,G是聚合函式(本文采用均值函式,就是對所有snippet的屬於同一類別的得分做個均值),G函式輸出的是Segmental Consensus的輸出結果。最後,利用H函式(本文采用softmax函式)計算得分概率,得分最高的類別就是該video所屬類別。
網路引數是共享的,即K個spatial convnet的引數是共享的,K個temporal convnet的引數也是共享的,實際用程式碼實現時只是不同的輸入同一個網路。
實驗
使用TVL1光流演算法提取正常光流場和扭曲光流場

備註
1、cross-modality pre-training:通過線性變換將光流場離散到從0到255的區間,這使得光流場的範圍和RGB影象相同。然後,修改RGB模型第一個卷積層的權重來處理光流場的輸入。具體來說,就是對RGB通道上的權重進行平均,並根據時間網路輸入的通道數量複製這個平均值。這一策略對時間網路中降低過擬合非常有效。
2、資料增強:傳統的two-stream採用隨記裁剪和水平翻轉方式,本文提出兩種新的方法,即角裁剪(corner cropping)和尺度抖動(scale-jittering)。
Deep Local Video Feature for Action Recognition(2017)
論文
內容
不是所有視訊幀都包含有用資訊,本文首先採用TSN提取區域性特徵。然後將區域性特徵聚合(本文采用最大池化方法)成全域性特徵,通過第二個分類階段採用SVM分配視訊級別的標籤。
程式碼
未公開
模型

實驗

備註
1、聚合( aggregation )方法:本文對比了Mean、Max、Mean_Std、BoW、VLAD和FV方法,實驗表示最大池化Max效果最好。
2、取樣:對每個視訊每個clips稀疏取樣15幀就就足夠了。
Temporal Relational Reasoning in Videos(2018)
論文
內容
本文提出一種時間關係網路,用來在多個時間尺度上學習,將不同時間尺度的關係特徵融合到一起,即可得到多時間尺度的時間關係
時間關係:給定一段視訊V,選取n個有序的視訊幀序列 ,則第 和 幀的關係定義如下:
其中函式 和 用於融合不同幀的特徵,這裡使用了簡單的多層感知機(MLP)來實現。這裡i和j的選取是隨機的。將該2-frame的關係概念可以拓展到N-frame。使用複合函式 融合不同尺度的視訊幀關係。
獲取TRN的代表幀序列:首先,計算視訊中等距幀的特徵,然後隨機組合他們生成不同的幀關係元組並將它們傳遞給到TRNs中,最後使用不同TRNs的響應對關係元組排序。
程式碼
原始碼(pytorch)
模型

實驗
目前可以用來做時間關係推理的資料集有Something-Something, Jester和Charades。其中Something-Something是最近提出的資料集,主要是用於人-物體互動動作識別,裡面有174類。
備註
無
2.2.2、3D網路
Learning spatiotemporal features with 3d convolutional networks(2015)
C3D提出 論文
內容
本文提出3D ConvNets在大規模視訊資料集訓練來學習視訊的時空特徵,並經過實驗選取了最佳的卷積核的尺寸3x3x3。使用C3D可以同時對外觀和運動資訊進行建模,在各種視訊分析任務上都優於2D卷積網路的特徵。
程式碼
原始碼(caffe)、預訓練模型
模型


實驗

備註
1、處理速度:若將一段16幀的視訊作為一個輸入,那麼C3D每秒可以處理約42個輸入(顯示卡為1080, batch size選為50),而圖中的fps達到了313.9,也就是每秒可以平均處理313.9幀,可見C3D的速度還是非常快的。
Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classificati(2017)
T3D 論文
內容
本文最大的貢獻就是該遷移方法的提出。本文引入一種新的時域層temporal layer給可變時域卷積核深度建模,此層叫做temporal transition layer(TTL) ,將這個新的temporal layer嵌入到我們提出的3D CNN,此網路叫做Temporal 3D ConvNets(T3D)。本文將DenseNet 結構從2D擴充套件到3D中。另一個貢獻是將知識預先訓練好的2D CNN轉移到隨記初始化的3D CNN以實現穩定的權值初始化。
程式碼
原始碼(pytorch)
模型


實驗

備註
無
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks(2017)
P3D 論文
內容
提出Pseudo-3D Residual Net (P3D ResNet),將1*3*3卷積和3*1*1卷積替代3*3*3卷積(前者用來獲取spatial維度的特徵,實際上和2D的卷積沒什麼差別,後者用來獲取temporal維度的特徵,因為倒數第三維是幀的數量),很大程度上減少計算量。
程式碼
原始碼(caffe)、第三方原始碼(pytorch)
模型



實驗

備註
無
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset(2017)
I3D 論文
內容
本文介紹了一個新的分類網路:膨脹3D卷積神經網路(I3D),即將卷積層和池化層推廣到3D情況。釋出了在新資料集Kinetics上訓練的BN Inception-v1 I3D models,通過遷移學習到UCF-101和HMDB-51上,取得驚人的精度。
程式碼
原始碼(tensorflow)
模型


實驗

備註
1、Kinetics資料集:包含大量資料,有400個動作分類,每個分類有超過400個例項,來源於YouTube,更有挑戰性。具體細節檢視文獻 The Kinetics Human Action Video Dataset。Kinetics-600下載地址。
格式(2018)
內容
程式碼
模型
實驗
備註