
Python中的requests模組
阿新 • • 發佈:2018-12-04
Python中的Requests模組
Requests模組是一個用於網路訪問的模組,類似的模組有urllib,urllib2,httplib,httplib2等,但由於其訪問http時的人性化,便於操作,深受人們喜歡。
在爬蟲中常使用的模組:
獲取網頁內容的----- urllib, requests
分析網頁常用的模組------ re, bs4(beautifulsoup4)
1. 例項引入
使用get方法獲得響應物件Response,我們可以利用這個物件得到我們想要的任何資訊。
# 例項引入 import requests url = 'http://www.baidu.com' response = requests.get(url) print('1',response) print('2',response.status_code) # 獲得響應狀態碼 print('3',response.cookies) # 獲得網頁cookies資訊 print('4',response.text) # 獲得網頁內容 print('5',type(response.text)) # 獲得網頁內容的型別

2.常見的請求方式
除了get方法之外。Requests還包括兩種請求方法post和delete方法。
import requests
response = requests.post('http://httpbin.org/post', data={'name' : 'xxxxxxx', 'age':18})
print(response.text)
response = requests.delete('http://httpbin.org/delete', data={'name' : 'xxxxxxx'})
print(response.text)
由例子可知,post

delete方法也通過data引數來傳遞請求引數。

3.帶引數的get請求
get引數是以params關鍵字引數傳遞的
#帶引數的get請求 url1 = 'https://movie.douban.com/subject/4864908/comments?start=20&limit=20&sort=new_score&status=P' import requests data = { 'start': 20, 'limit': 40, 'sort': 'new_score', 'status': 'P', } url = 'https://movie.douban.com/subject/4864908/comment' response = requests.get(url, params=data) print(response.url)
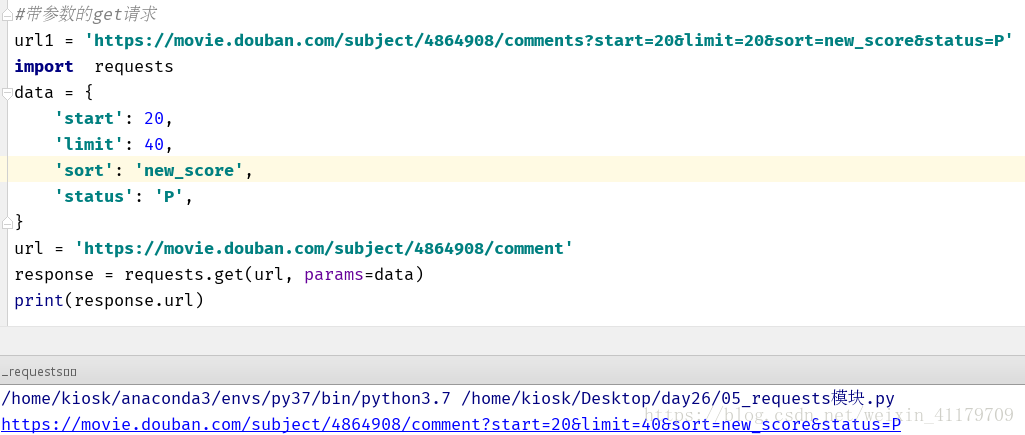
4.解析json格式
JSON(JavaScript Object Notation, JS 物件簡譜) 是一種輕量級的資料交換格式。它基於 ECMAScript (歐洲計算機協會制定的js規範)的一個子集,採用完全獨立於程式語言的文字格式來儲存和表示資料。簡潔和清晰的層次結構使得 JSON 成為理想的資料交換語言。 易於人閱讀和編寫,同時也易於機器解析和生成,並有效地提升網路傳輸效率。
import requests
# ip = '8.8.8.8'
ip = input("請輸入查詢的IP:")
url = "http://ip.taobao.com/service/getIpInfo.php?ip=%s" %(ip)
response = requests.get(url)
content = response.json()
print(content)
print(type(content))
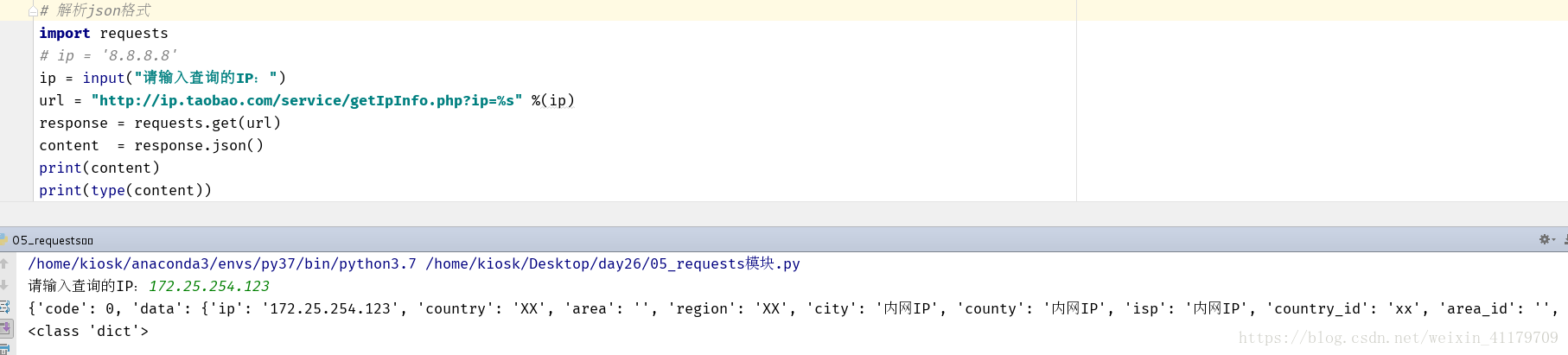
5.獲取二進位制資訊
# 獲取二進位制資料
import requests
url = 'https://gss0.bdstatic.com/-4o3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=4f7bf38ac3fc1e17fdbf8b3772ab913e/d4628535e5dde7119c3d076aabefce1b9c1661ba.jpg'
response = requests.get(url)
print(response.text)
with open('github.png', 'wb') as f:
# response.text : 返回字串的頁面資訊
# response.content : 返回bytes的頁面資訊
f.write(response.content)
寫入影象中效果:

6.下載視訊
import requests
# url = 'https://gss0.bdstatic.com/-4o3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=4f7bf38ac3fc1e17fdbf8b3772ab913e/d4628535e5dde7119c3d076aabefce1b9c1661ba.jpg'
url = "http://gslb.miaopai.com/stream/sJvqGN6gdTP-sWKjALzuItr7mWMiva-zduKwuw__.mp4"
response = requests.get(url)
with open('/tmp/learn.mp4', 'wb') as f:
# response.text : 返回字串的頁面資訊
# response.content : 返回bytes的頁面資訊
f.write(response.content)
下載成功

7.新增headers資訊
在get引數中田間header資訊
import requests
url = 'http://www.cbrc.gov.cn/chinese/jrjg/index.html'
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
headers = {
'User-Agent': user_agent
}
response = requests.get(url, headers=headers)
print(response.text)
print(response.status_code)
使得之前需要使用好幾步urlopen方法的偽裝瀏覽器操作變得只需在get方法中加入header引數即可。
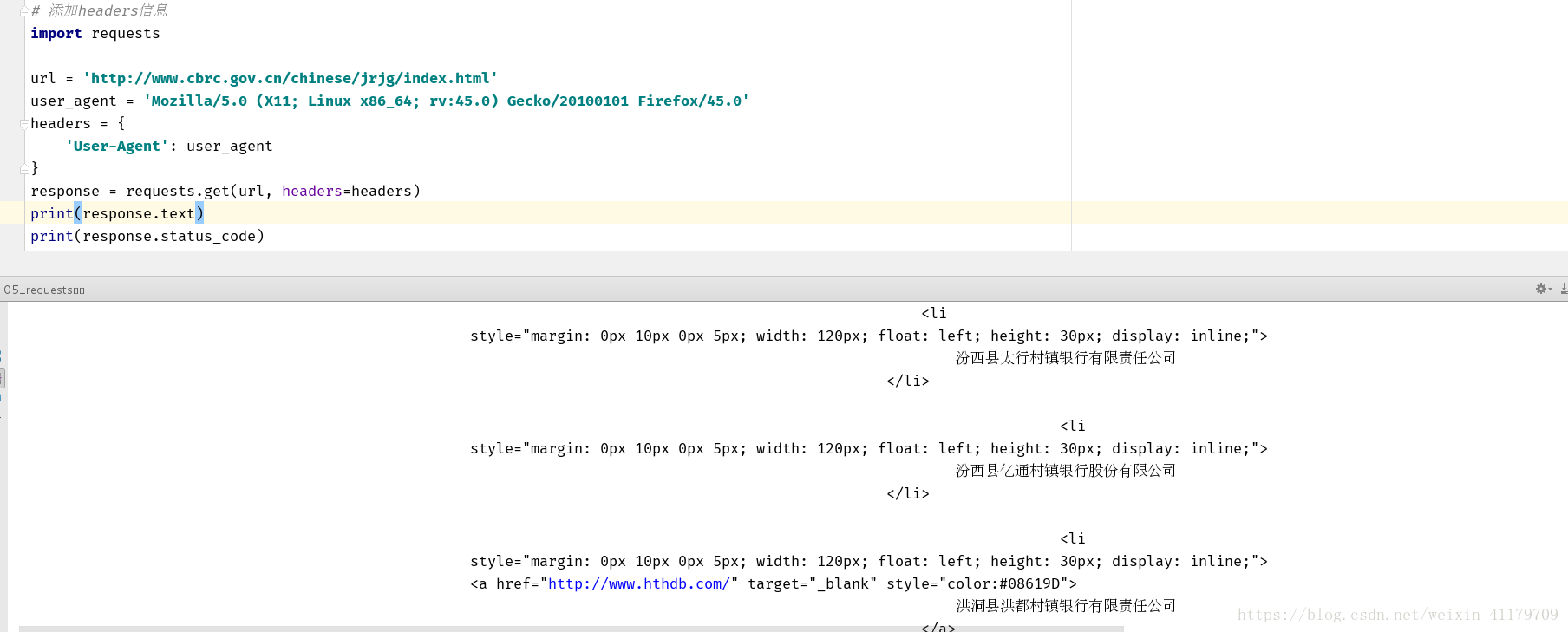
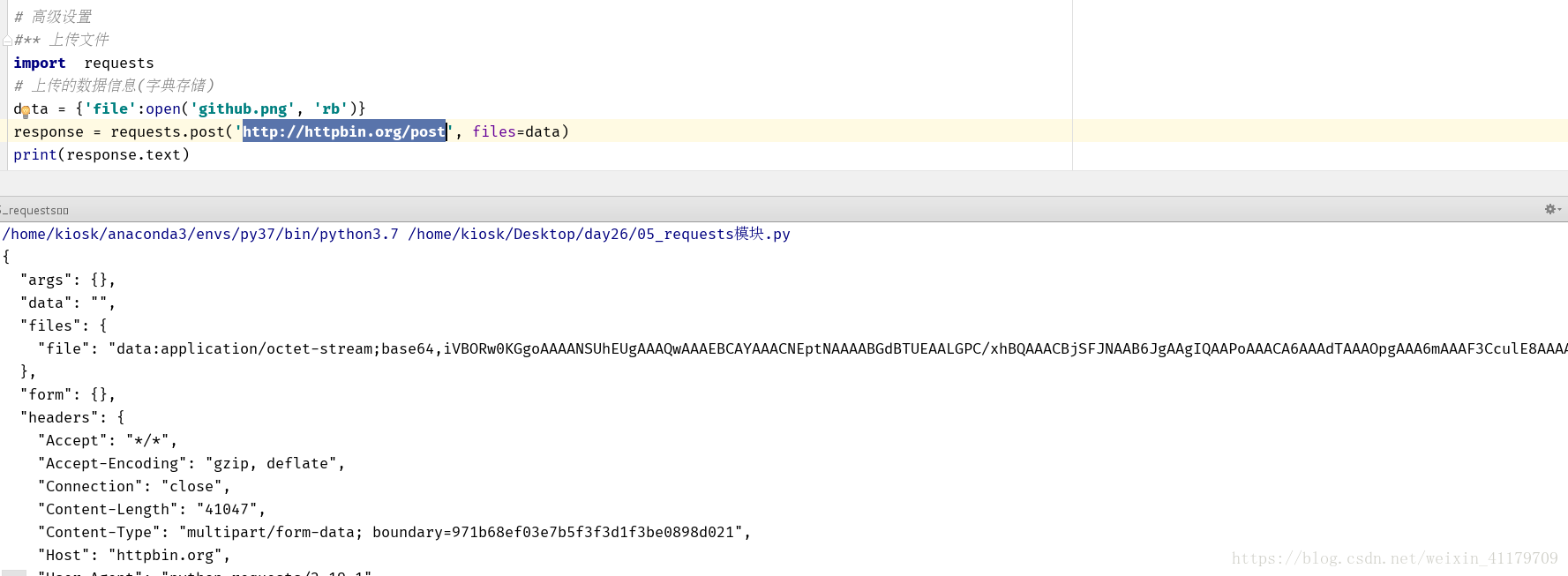
8.上傳檔案
import requests
# 上傳的資料資訊(字典儲存)
data = {'file':open('github.png', 'rb')}
response = requests.post('http://httpbin.org/post', files=data)
print(response.text)
使用[http://httpbin.org/post]網站返回的值確定可上傳檔案
9.獲取cookie資訊
import requests
# 上傳的資料資訊(字典儲存)
response = requests.get('http://www.csdn.net')
print(response.cookies)
for key, value in response.cookies.items():
print(key + "=" + value)

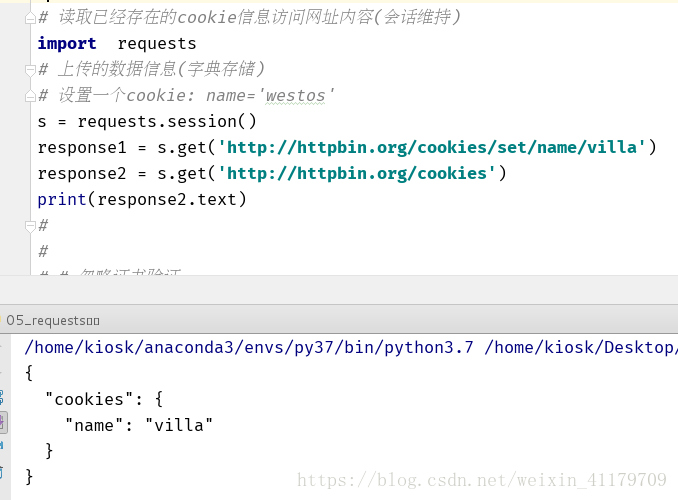
10.讀取已經存在的cookie資訊訪問網址內容(會話維持)
import requests
# 上傳的資料資訊(字典儲存)
# 設定一個cookie: name='westos'
s = requests.session()
response1 = s.get('http://httpbin.org/cookies/set/name/villa')
response2 = s.get('http://httpbin.org/cookies')
print(response2.text)
11.忽略證書驗證
由於很多網站在爬取時會碰到需要證書驗證的問題,在get方法中加入verify=False可忽略證書驗證
在沒有加入忽略引數時,即無法訪問
# 忽略證書驗證
import requests
url = 'https://www.12306.cn'
response = requests.get(url)
print(response.status_code)
print(response.text)

新增忽略引數之後
# 忽略證書驗證
import requests
url = 'https://www.12306.cn'
response = requests.get(url, verify=False)
print(response.status_code)
print(response.text)

12.代理設定(proxies=proxy)/設定超時間(timeout=sec)
# 代理設定/設定超時間
import requests
proxy = {
'https': '171.221.239.11:808',
'http': '218.14.115.211:3128'
}
response = requests.get('http://httpbin.org/get', proxies=proxy, timeout=10)
print(response.text)