
Java的序列化機制
1、java本身的序列化存在的問題
1、序列化資料結果比較大、傳輸效率比較低
2、不能跨語言對接
對於該問題出現的xml、json等方式成為了熱門技術,但是這種序列化技術還是存在佔用空間大、效能低等問題,也就出現了二進位制序列化框架MessagePack等。
2、序列化概念
把物件轉換為位元組序列的過程稱之為物件的序列化,反之則稱為反序列化
3、如何實現一個序列化操作
1、對一個類實現Serializable介面,同時生成一個serialVersionUID。
package com.wuyonghu.test4; import java.io.Serializable; public class Person implements Serializable { private static final long serialVersionUID = 2818521397469642897L; private String name; private String age; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAge() { return age; } public void setAge(String age) { this.age = age; } }
2、建立主方法來進行對物件的序列化:
package com.wuyonghu.test4; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; public class MainTest { public static void main(String[] args) { // 序列化 SerializableTest(); } private static void SerializableTest() { try { // 使用ObjectOutputStream指定序列化的結果 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("person"))); // 建立需要序列化的物件 Person person = new Person(); person.setAge("17"); person.setName("lufei"); // 進行序列化 oos.writeObject(person); System.out.println("序列化完成!"); oos.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
3、執行SerializableTest方法後,會發現在工程的根目錄下生成了一個person檔案:

該檔案通過二進位制方式開啟的結果如下:
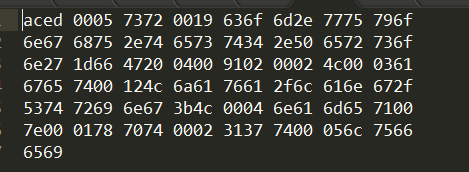
4、如何進行反序列化操作
以第三步得到的person檔案來進行反序列化
1、反序列化的方法如下:
public static void SerializableTest2() { try { ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("person"))); Person person = (Person) ois.readObject(); System.out.println("反序列化完成,姓名為" + person.getName() + ",年齡為:" + person.getAge()); ois.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } }
2、執行反序列化後的結果如下:

3、從結果可以知道,我們能從通過反序列化得到序列化前的物件資訊。
5、serialVersionUID的作用
在對物件進行序列化的時候,該對應對應的類是實現了序列化的介面,同時新增了serialVersionUID這個值的,那麼這個值的作用是什麼呢?

為了測試,首先將該值保留,進行序列化,得到結果person檔案。然後將該值註釋後進行反序列化。

此處注意一下,如果要驗證該功能,測試時最好自己隨意指定一個serialVersionUID值,否則jvm會自動生成一個UID,而反序列的時候自動生成的該UID會相同,從而會出現沒有報錯的情況。
從該現象,得出的結論如下:
檔案流中的class和classpath中的class,也就是修改過後的class,不相容了,處於安全機制考慮,程式丟擲了錯誤,並且拒絕載入。從錯誤結果來看,如果沒有為指定的class配置serialVersionUID,那麼java編譯器會自動給這個class進行一個摘要演算法,類似於指紋演算法,只要這個檔案有任何改動,得到的UID就會截然不同的,可以保證在這麼多類中,這個編號是唯一的。所以,由於沒有顯指定 serialVersionUID,編譯器又為我們生成了一個UID,當然和前面儲存在檔案中的那個不會一樣了,於是就出現了2個序列化版本號不一致的錯誤。因此,只要我們自己指定了serialVersionUID,就可以在序列化後,去新增一個欄位,或者方法,而不會影響到後期的還原,還原後的物件照樣可以使用,而且還多了方法或者屬性可以用。
6、關於序列化的其他概念
1、序列化並不儲存靜態變數的狀態
2、transient關鍵字表示指定屬性不參與序列化
3、如果父類沒有實現序列化,而子類實現列序列化。那麼父類中的成員沒辦法做序列化操作
4、對同一個物件進行多次寫入,打印出的第一次儲存結果和第二次儲存結果,只多了5個位元組的引用關係。
並不會導致檔案累加