
機器學習中各種熵的定義及理解
機器學習領域有一個十分有魅力的詞:熵。然而究竟什麼是熵,相信多數人都能說出一二,但又不能清晰的表達出來。
而筆者對熵的理解是:“拒絕學習、拒絕提升的人是沒有未來的,也只有努力才能變成自己想成為的人”。
下圖是對熵的一個簡單描述:
熵可以理解為是一種對無序狀態的度量方式。那麼熵又是如何被用在機器學習中呢?
在機器學習領域中,量化與隨機事件相關的預期資訊量以及量化概率分佈之間的相似性是常見的問題。針對這類問題,利用夏農熵以及衍生的其他熵概念去度量概率分佈的資訊量是個很好的解決方案。本文會盡可能用簡單的描述分享自己對各種熵的定義及理解,歡迎交流討論。
1. 自資訊
自資訊又稱資訊量。
“陳羽凡吸毒?!工作室不是剛闢謠了嗎?哇!資訊量好大!”
在生活中,極少發生的事情最容易引起吃瓜群眾的關注。而經常發生的事情則不會引起注意,比如吃瓜群眾從來不會去關係明天太陽會不會東邊升起。
也就是說,資訊量的多少與事件發生概率的大小成反比。
對於已發生的事件i,其所提供的資訊量為:
![]()
其中底數通常為2,負號的目的是為了保證資訊量不為負。
事件i發生的概率與對應資訊量的關係如下所示:
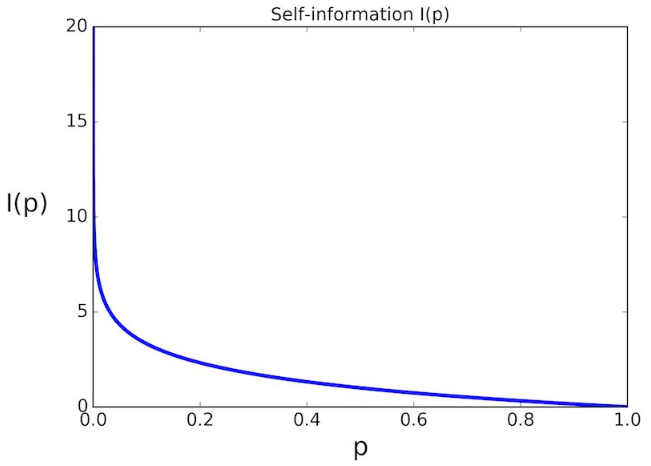
我們再考慮一個問題:假設事件x個可能的狀態,例如一枚硬幣丟擲落地後可能有兩種狀態,正面或反面朝上,這時候該怎樣取衡量事件所提供的資訊量?
2. 資訊熵
資訊熵又稱夏農熵。
到目前為止,我們只討論了自資訊。實際上,對於一枚硬幣來講,自資訊實際上等於資訊熵,因為無論正反面,朝上的概率都相等。
資訊熵用來度量一個事件可能具有多個狀態下的資訊量,也可以認為是資訊量關於事件概率分佈的期望值:
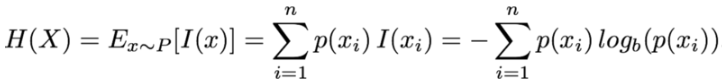
其中事件x共有n個狀態,i表示第i個狀態,底數b通常設為2,也可設為10或e。
H(x)表示用以消除這個事件的不確定性所需要的統計資訊量,即資訊熵。
還是以拋硬幣為例來理解資訊熵:
| 事件 |
概率 |
資訊量(自資訊) |
資訊熵(統計資訊量) |
| 正面朝上 |
1/2 |
-log(1/2) |
(-1/2 * log(1/2))+( -1/2 * log(1/2)) |
| 反面朝上 |
1/2 |
-log(1/2) |
(-1/2 * log(1/2))+( -1/2 * log(1/2)) |
根據資訊熵公式可得出以下結論:
- 若事件x個狀態發生概率為1,那麼資訊熵H(x)等於0
- 若事件x的所有狀態n發生概率都一致,即都為1/n,那麼資訊熵H(x)有極大值logn。
資訊熵可以推廣到連續域,此時被稱為微分熵。對於連續隨機變數x和概率密度函式p(x), 資訊熵的定義如下:
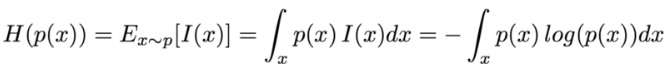
3. 聯合熵
上面我們講到的都是對於一個事件的熵。那麼如果有多個事件,例如事件x和事件y都出現時,又該怎樣去度量呢?
首先,是聯合熵,公式如下:
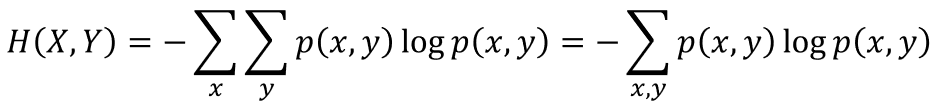
其中p(x,y)代表事件x和事件y的聯合概率。
這次以同時拋兩枚硬幣為例來說明聯合熵如何對兩個事件進行度量:
| 事件 |
概率 |
資訊量(自資訊) |
聯合熵 |
| x正,y正 |
1/2 * 1/2 = 1/4 |
-log(1/4) |
-(1/4*log(1/4)+ 1/4 * log(1/4) + 1/4 * log(1/4) + 1/4 * log(1/4)) |
| x正,y反 |
1/2 * 1/2 = 1/4 |
-log(1/4) |
-(1/4*log(1/4)+ 1/4 * log(1/4) + 1/4 * log(1/4) + 1/4 * log(1/4)) |
| X反,y正 |
1/2 * 1/2 = 1/4 |
-log(1/4) |
-(1/4*log(1/4)+ 1/4 * log(1/4) + 1/4 * log(1/4) + 1/4 * log(1/4)) |
| X反,y反 |
1/2 * 1/2 = 1/4 |
-log(1/4) |
-(1/4*log(1/4)+ 1/4 * log(1/4) + 1/4 * log(1/4) + 1/4 * log(1/4)) |
4. 條件熵
條件熵表示在已知事件x的條件下,事件y的不確定性。定義為在給定條件下x,y的條件分佈概率的熵對x的數學期望:
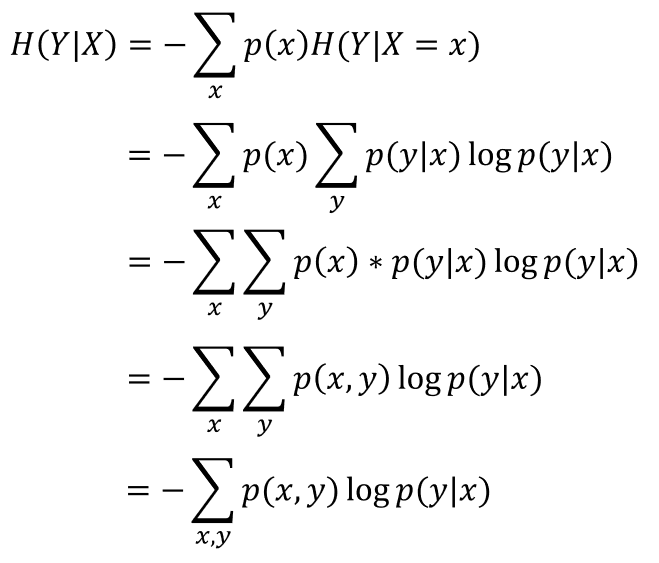
可以發現,條件熵與聯合熵僅僅在於log項不同。
此外,根據聯合概率分佈與條件概率分佈的關係,可得:
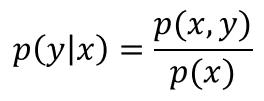
所以:
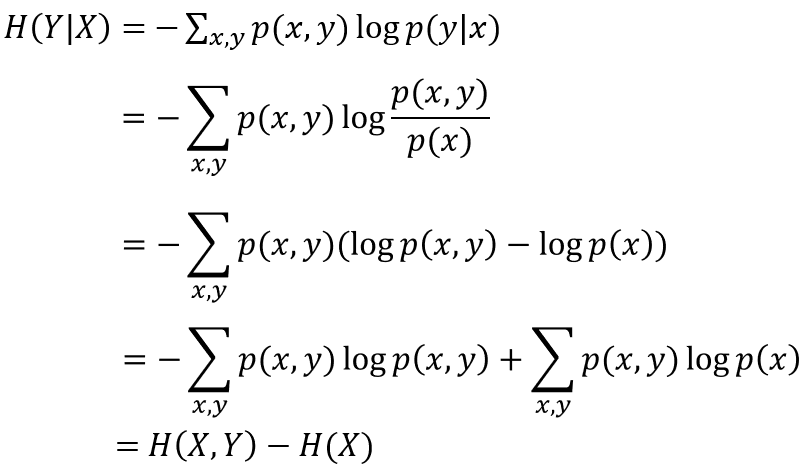
即在x條件下,y的條件熵 = x,y的聯合熵 - x的資訊熵。
5. 交叉熵
交叉熵是一個用來比較兩個概率分佈p和q的度量公式。換句話說,交叉熵是衡量在真實分佈下,使用非真實分佈所制定的策略能夠消除系統不確定性的大小。
如何正確理解上述這段描述呢?首先,觀察交叉熵的公式,如下圖所示:
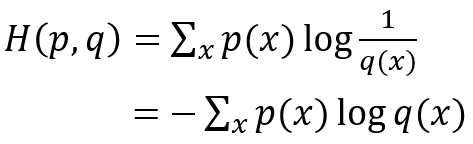
其中,p(x)為事件的真實分佈概率,q(x)為事件的非真實分佈概率。
可以看到,與資訊熵相比,唯一不同的是log裡的概率由資訊熵中的真實分佈概率p(x)變成了非真實概率(假設分佈概率)q(x),即1-p(x)。也就是與資訊熵相比,交叉熵計算的不是log(p)在p下的期望,而是log(q)在p下的期望。
同樣地,交叉熵可也以推廣到連續域。對於連續隨機變數x和概率密度函式p(x)和假設分佈概率密度函式q(x), 交叉熵的定義如下:
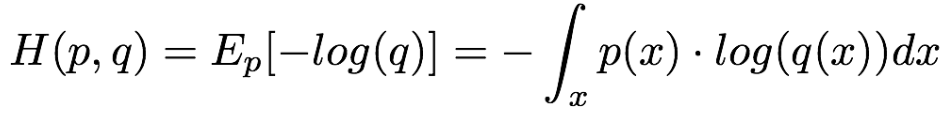
所以,如果假設分佈概率與真實分佈概率一致,那麼交叉熵 = 資訊熵。
6. 相對熵
相對熵又稱KL散度。
相對熵衡量了當修改從先驗分佈p到後驗分佈q的信念後所帶來的資訊增益。換句話說,就是用後驗分佈 q 來近似先驗分佈 p 的時候造成的資訊損失。再直白一點,就是衡量不同策略之間的差異性。
計算公式如下:
![]()
其中H(p,q)代表策略p下的交叉熵,H(p)代表資訊熵。所以,相對熵 = 某個策略的交叉熵-資訊熵。
相對熵用來衡量q擬合p的過程中產生的資訊損耗,損耗越少,q擬合p也就越好。
需要注意的是,儘管從直覺上相對熵(KL散度)是個度量或距離函式, 但是它實際上並不是一個真正的度量或距離。因為KL散度不具有對稱性:從分佈P到Q的距離通常並不等於從Q到P的距離。
![]()
7. 互資訊
互資訊用來表示兩個變數X與Y之間是否有關係,以及關係的強弱。
用公式可以表示為:
![]()
因此,可認為變數X與Y的互資訊就是資訊熵H(X)與條件熵H(X|Y)的差。
8. 熵在機器學習中的應用
針對熵的應用,個人總結主要有以下幾點:
- 在貝葉斯網路中,會假設一個先驗分佈,目的是為了反映隨機變數在觀測前的不確定性。在進行模型訓練時,減小熵,同時讓後驗分佈在最可能的引數值周圍形成峰值。
- 在做分類任務的引數估計時,尤其是在神經網路中,交叉熵往往作為損失函式用來更新網路權重。
- 在樹模型演算法中,熵的作用也是不可或缺,尤其是在使用ID3資訊增益、C4.5增益率時,通過使用熵來劃分子節點,從而可以構造出整棵樹。