
機器學習6:評估
評估+設計雜談
評估模型(假設函式)
當要對我們的預測誤差作故障排除,不外乎通過以下這幾種方式:
- 增加更多的訓練樣本
- 減少特徵種類
- 增加特徵種類(增加額外的特徵或者多項式特徵 )
- 增加或減少懲罰引數
但是如何確定應該採取的方式?
訓練集+測試集
訓練得到的假設函式可能對於訓練集來說誤差低,但是在預測新樣本時不夠準確(過擬合),因此,我們需要把訓練樣本分為訓練集和測試集,比例為7:3。
所以評估過程為:
- 採用訓練集訓練得到假設函式
- 計算測試集在假設函式下的代價函式(計算測試集的平均誤差)
測試集的誤差
-
線性迴歸
-
邏輯迴歸
2.1 分類誤差 0/1
上式將錯誤分類用0或1進行了標識,所以測試集的平均誤差為:
上式揭示了根據測試集的輸入特徵錯誤分類的比例。
2.2 代價函式
訓練集+驗證集+測試集
如果有多個模型可以選擇,例如可以選擇多個多項式次數不同的模型,那麼,可以通過驗證集對模型進行選擇,再利用測試集評估泛化誤差。(如果只有訓練集和測試集,用測試集同時進行模型選擇和誤差評估是不合理的,因為通過模型選擇後,測試集已經與模型相匹配,很難再用於泛化評估)
訓練集、驗證集和測試集的比例為6:2:2。
診斷:偏差 vs 方差
高偏差指欠擬合;高方差指過擬合。
- 多項式次數與偏差和方差診斷的關係

隨著假設函式中多項式次數(特徵)的增多,對於訓練集的誤差越來越小,而對於驗證集的誤差先降後升。
訓練集誤差和驗證集誤差均高且近似相等時診斷為高偏差;
訓練集誤差低,而驗證集誤差高時診斷為高方差。
- 正則化和偏差/方差
正則化引數 過小時,有可能過擬合,過大時,有可能欠擬合。
隨著 增大,對於訓練集的誤差越來越大,而對於驗證集的誤差先降後升。
訓練集誤差和驗證集誤差均高且近似相等時診斷為高偏差;
訓練集誤差低,而驗證集誤差高時診斷為高方差。
可以通過以下步驟選擇合適的
:
2.1 生成若干個
,如
2.2 生成一系列模型,對應不同的
2.3 通過訓練集訓練得到各模型的模型引數
2.4 通過驗證集計算驗證誤差(計算時忽略代價函式中的正則項),並選出驗證誤差最小的模型作為最優模型
2.5 將測試集應用於最優模型以預測泛化效能。
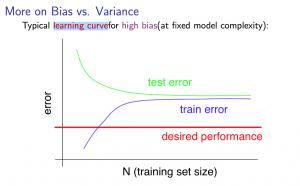
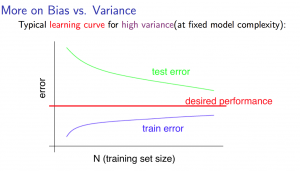
- 學習曲線(訓練樣本/訓練集數量與偏差和方差)
當訓練樣本增多,訓練集的誤差越來越大,而驗證集的誤差卻越來越小。在訓練樣本數量達到一定程度後,訓練集和驗證集的誤差近似。
-
如果增加訓練樣本的情況下,訓練集的誤差和驗證集的誤差不變,且均高於理想水平,則有可能高偏差(同時可見,增加訓練樣本不能解決高偏差的問題)PS:快速聚攏的就是高偏差,因為如果是正常情況,則兩種誤差應當相似,如果一開始驗證集誤差比訓練集誤差高,則要麼高偏差,要麼高方差
-
如果在增加訓練樣本的情況下,驗證集的誤差平緩下降,訓練集的誤差平緩上升,且它們之間有明顯的差距,則有可能高方差(同時可見,增加訓練樣本可以解決高方差時,它們向理想水平靠攏)PS:訓練樣本增加到一定程度後,兩者之間在很長一段期間內還保持一定差距,那就說明是高方差了
診斷後的調整
調整方式可列舉如下:
- 增加訓練樣本 - 高方差
- 減少特徵 - 高方差
- 增加特徵(額外的特徵或增加多項式次數) - 高偏差
- 減小 - 高偏差
- 增加 - 高方差
評估神經網路
過擬合/欠擬合
- 一個簡易的神經網路傾向於欠擬合(計算量小)
- 一個大型的神經網路傾向於過擬合(計算量大;可以使用正則化來解決過擬合)
平衡偏差和方差
- 利用訓練集,從訓練包含一個隱藏層的神經網路依次