
RANSAC與最小二乘擬合 通俗講解
一、RANSAC理論介紹
普通最小二乘是保守派:在現有資料下,如何實現最優。是從一個整體誤差最小的角度去考慮,儘量誰也不得罪。
RANSAC是改革派:首先假設資料具有某種特性(目的),為了達到目的,適當割捨一些現有的資料。
給出最小二乘擬合(紅線)、RANSAC(綠線)對於一階直線、二階曲線的擬合對比:

可以看到RANSAC可以很好的擬合。RANSAC可以理解為一種取樣的方式,所以對於多項式擬合、混合高斯模型(GMM)等理論上都是適用的。
RANSAC的演算法大致可以表述為(來自wikipedia):
Given: data – a set of observed data points model – a model that can be fitted to data points n – the minimum number of data values required to fit the model k – the maximum number of iterations allowed in the algorithm t – a threshold value for determining when a data point fits a model d – the number of close data values required to assert that a model fits well to data Return: bestfit – model parameters which best fit the data (or nul if no good model is found) iterations = 0 bestfit = nul besterr = something really large while iterations < k { maybeinliers = n randomly selected values from data maybemodel = model parameters fitted to maybeinliers alsoinliers = empty set for every point in data not in maybeinliers { if point fits maybemodel with an error smaller than t add point to alsoinliers } if the number of elements in alsoinliers is > d { % this implies that we may have found a good model % now test how good it is bettermodel = model parameters fitted to all points in maybeinliers and alsoinliers thiserr = a measure of how well model fits these points if thiserr < besterr { bestfit = bettermodel besterr = thiserr } } increment iterations } return bestfit
RANSAC簡化版的思路就是:
第一步:假定模型(如直線方程),並隨機抽取Nums個(以2個為例)樣本點,對模型進行擬合:
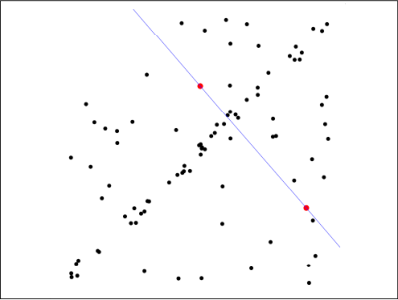
第二步:由於不是嚴格線性,資料點都有一定波動,假設容差範圍為:sigma,找出距離擬合曲線容差範圍內的點,並統計點的個數:
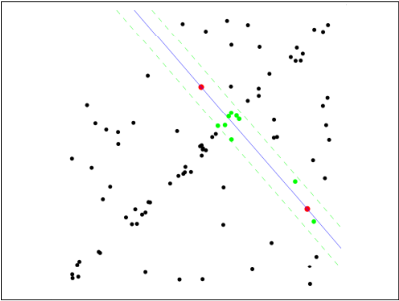
第三步:重新隨機選取Nums個點,重複第一步~第二步的操作,直到結束迭代:

第四步:每一次擬合後,容差範圍內都有對應的資料點數,找出資料點個數最多的情況,就是最終的擬合結果:
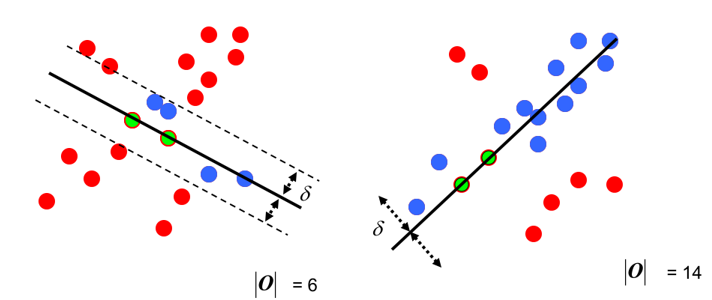
至此:完成了RANSAC的簡化版求解。
這個RANSAC的簡化版,只是給定迭代次數,迭代結束找出最優。如果樣本個數非常多的情況下,難不成一直迭代下去?其實RANSAC忽略了幾個問題:
- 每一次隨機樣本數Nums的選取:如二次曲線最少需要3個點確定,一般來說,Nums少一些易得出較優結果;
- 抽樣迭代次數Iter的選取:即重複多少次抽取,就認為是符合要求從而停止運算?太多計算量大,太少效能可能不夠理想;
- 容差Sigma的選取:sigma取大取小,對最終結果影響較大;
這些引數細節資訊參考:維基百科。
RANSAC的作用有點類似:將資料一切兩段,一部分是自己人,一部分是敵人,自己人留下商量事,敵人趕出去。RANSAC開的是家庭會議,不像最小二乘總是開全體會議。
附上最開始一階直線、二階曲線擬合的code(只是為了說明最基本的思路,用的是RANSAC的簡化版):
一階直線擬合:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|
二階曲線擬合:
二、RANSAC應用簡介
RANSAC其實就是一種取樣方式,例如在影象拼接(Image stitching)技術中:
第一步:預處理後(據說桶形變換,沒有去了解過)提取影象特徵(如SIFT)

第二步:特徵點進行匹配,可利用歸一化互相關(Normalized Cross Correlation method, NCC)等方法。
但這個時候會有很多匹配錯誤的點:

這就好比擬合曲線,有很多的誤差點,這個時候就想到了RANSAC演算法:我不要再兼顧所有了,每次選取Nums個點匹配 → 計算匹配後容差範圍內的點數 → 重複實驗,迭代結束後,找出點數最多的情況,就是最優的匹配。
利用RANSAC匹配:

第三步:影象拼接,這個就涉及拼接技術了,直接給出結果:

參考: