
JAVASE8流庫Stream學習總結(三)
阿新 • • 發佈:2018-12-08
3、聚合(終止流操作)
前面我們已經看到過如何建立流和轉換流了,現在是時候讓流終止,並返回些有用的東西給我們了,這個過程就叫做聚合,
也叫約簡。
一、Optional類
講到這個,我們先從
Optional類講起,什麼是Optional類,Optional<T>是一種包裝器物件,他可以對空值進行了處理,比直接
使用某個物件更加安全。例如,我們如果現在有個函式int a(int x),和函式int b(int y),如果一個函式的返回值作為另一個函式的引數
,就比如a(b(x))吧 b(x)的返回值要保證不是空值才行,否則會丟擲空指標異常。
簡而言之,Optional是一個可以允許所包含的物件
建立Optional類:
第一種方法接收一個物件,返回一個含義該物件的Optional物件,但他不接收null,否則會丟擲NullPointerException異常 第二種方法接收一個物件,也接收null,返回一個含義該物件的Optional物件,這個Optional物件可以是空的。 第三種方法就直接建立一個空的Optional
舉個栗子: public static void main(String[] args) {
可以看到,當使用第二種方法也就是ofNullable方法時,如果傳入的物件為空,就直接返回一個空的Optional物件,避免了空指標物件 而使用of方法時,傳入的物件為null時,則會丟擲 NullPointerException異常
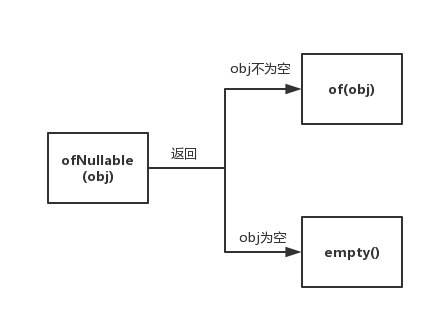
實際上,我們通過ofNullable()方法的原始碼也可以發現,它被用來作為可能出現null值和可選值之間的橋樑。他在傳入的值不為空的時候 返回Option.of(obj),在傳入的值為空時則,返回Optional.empty();
ofNullable原始碼: public static <T> Optional<T> ofNullable(T value) { return value == null ? empty() : of(value);
使用Optional物件 我們已經知道Optional物件是一種更加安全的物件,因為他對空值進行了處理,那也就是說,他的使用方法 得像這樣:他會在值不存在的情況下產生一個“替代物”代替null,在值存在的情況下則使用該值 我們先看下第一種情況,在值不存在的時候怎麼辦: 當值不存在時: 1、給預設值 public class OptionalUse { public static void main(String[] args) { Optional<String> optional=Optional.ofNullable(null); String result=optional.orElse("empty String"); System.out.println(result); } } 輸出: empty String 可以看到,利用orElse()方法,我們為沒有Optional物件為空的情況指定了一個預設值,呼叫時若為空則返回指定的 預設值。 2、給處理方法得出預設值 public class OptionalUse { public static void main(String[] args) { Optional<String> optional=Optional.ofNullable(null); String result=optional.orElseGet(()->Locale.getDefault().getDisplayName()); System.out.println(result); } } 輸出: 中文 (中國) 同樣的,我們指定了一個方法為預設方法(上面那個方法的作用是返回本地語言和國家) 3、丟擲某個異常 public class OptionalUse { public static void main(String[] args) { Optional<String> optional=Optional.ofNullable(null); String result=optional.orElseThrow(RuntimeException::new); System.out.println(result); } } 輸出: Exception in thread "main" java.lang.RuntimeException at java.base/java.util.Optional.orElseThrow(Optional.java:385) at 建立流.OptionalUse.main(OptionalUse.java:9) 這個應該就沒什麼好解釋了的,預設指定為丟擲一個異常
當值存在時: 當值存在時,我們可以對值進行操作, 注意:這種操作是可能改變Optional本身包含的值的。 1、利用void ifPresent(Supplier <? extemds T> s) Supplier有點熟悉吧,他其實就是一個Lambda表示式,我們在建立流的generate()方法中有看到過。 public class OptionalUse { public static void main(String[] args) { Optional<String> optional=Optional.ofNullable("XiaoZhong"); String result=optional.orElseThrow(RuntimeException::new); optional.ifPresent(w->System.out.println(w.toUpperCase())); //這個get()是獲取Optional物件中的元素 System.out.println(optional.get()); } } 輸出: XIAOZHONG XiaoZhong
前面說到,這種操作是可能改變Optional本身包含的值的。 可以看到,在ifPresent()方法裡,我們對該值進行了大小寫轉換並作出了列印操作,然後再一次的在ifParesent()外面 驗證了一下Optional中的值是否被改變了。發現值並沒有被改變。 但你有可能會想,ifPresent()把引數傳遞給某個函式的時候是值傳遞,如果傳遞某個具體的物件呢(其實這個String已經是個物件了), 保險起見,我們再驗證一下。 public class OptionalUse { public static class Id { private static int count=0; private final int id=count++; public String name="Zhong"; public Id() { // TODO Auto-generated constructor stub } @Override public String toString() { // TODO Auto-generated method stub return "ID: "+ id +"\nNAME: " + name; }
public String getName() { return name; }
public void setName(String name) { this.name = name; } } public static void main(String[] args) { Optional<Id> optional=Optional.ofNullable(new Id()); //這個get()是獲取Optional物件中的元素 System.out.println(optional.get()); optional.ifPresent(w->w.setName("you name")); System.out.println(optional.get()); } } 輸出: ID: 0 NAME: Zhong ID: 0 NAME: you name
這裡簡單地寫了一個內部類,這個內部類用來記錄一個人ID和名字,名字預設是Zhong,我們想通過在ifPresent()中呼叫內部類的 set方法,來看是否發生了改變,結果顯而易見,的確發生了改變 其實我們在傳遞引數的時候,當傳入的基本資料型別時,是值傳遞,而傳入的是陣列,物件時則是引用傳遞,這一點同樣適用於在 ifPresent()中引數的傳遞
2、利用map()對值進行操作 先上程式碼 Optional<String> optional2=Optional.ofNullable(null); List<String> list=new ArrayList<String>(); optional2.map(list::add); System.out.println(list); optional2=Optional.of("Hello World"); optional2.map(list::add); System.out.println(list); 輸出: [] [Hello World]
map()對Optional中的值進行操作,這裡是把值加入到list中,list的add有兩種情況,當Optional為空時,則返回空的Optional,不為空則返回某個字串。 這裡的”::“操作符,是lambda表示式對方法的呼叫,叫做method reference。大家可以看看這兩個資料: 中文版: http://zh.lucida.me/blog/java-8-lambdas-insideout-language-features/ 英文版: http://www.techempower.com/blog/2013/03/26/everything-about-java-8/ 這裡有詳細地講述,JAVA8中Lambda表示式的用法。
3、利用flatMap()來構建Optional值的函式 假設你有一個可以產生Optional<T>的f方法,泛型T又有一個可以產生Optional<U>的方法g,你想通過f獲得U目標物件 很自然地會想到 這樣組合 s.f().g(),然而這樣無法工作,因為s.f()是Optional<T>型別的,而不是T型別的
private static Optional<Double> sum(Double a,Double b){ return Optional.of(a+b); } private static Optional<Double> squareRoot(Double x){ return x<0?Optional.empty():Optional.of(Math.sqrt(x)); } main方法中: //Optional<Double> result=sum(1.0,1.0).map(a->squareRoot(a)); 不行,編譯器會報錯,不能把Optional<Double>轉換為Double //flatMap示例 Optional<Double> result=sum(1.0,1.0).flatMap(a->squareRoot(a)); System.out.println(result.get()); 輸出: 1.4142135623730951 二、收集結果 1、forEach(),將函式應用於每個元素 例如:stream.forEach(System.out::print); 2、iterator(),用來訪問元素的迭代器 沒錯,JAVA8也有迭代器,使用方法和以前的一樣,就不寫例子了 3、toArray(),將流中的元素轉換為陣列物件 但是stream.toArray()返回的是Object[]型別的陣列,要得到正確型別的陣列,我們就得傳陣列構造器到引數中 例如:String[] result=stream.toArray(String[]::new); 4、轉換成Collection (1)轉換成List,利用stream.collect(Collectors.toList()) 例如List<String> result=stream.collect(Collectors.toList()) (2)轉換成set,利用stream.collect(Collectors.toSet()) 例如Set<String> result=stream.collect(Collectors.toSet()) (3)轉換成Map,這個要重點記下筆記 a、利用Collectors.toMap()方法 這一種是最簡單的,直接指定鍵和值就可以了 例如: 假設我們有個Stream<Employee>物件stream,Employee有name,city的例項變數,並且具有相對應的get和set方法 現在我們要生成一個Map,以city為鍵,name為值 Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName)); 這樣就行了,十分簡單 但是如果鍵衝突了怎麼辦,即一個鍵對應了多個元素,編譯器會丟擲IllegalStateException 我們要為toMap再新添一個引數,說明這種情況怎麼辦 例如: Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->existingValue)); (existingValue,newValue)->existingValue指出了這種情況怎麼辦,即以原先的元素為準,不新增新元素 或者你也可以選擇丟擲異常 Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->{throw new RuntimeException("SomethingWrong")})); 如果要得到TreeSet,那麼再加一個構造引數在收集器中就可以了 Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->{throw new RuntimeException("SomethingWrong")},TreeMap::new)); b、利用Collectors.groupingBy()分組獲得Map groupingBy的基本使用方法: goupingBy方法會產生一個對映表,它的每一個值都對應一個列表
public String getName() { return name; }
public void setName(String name) { this.name = name; } @Override public String toString() { // TODO Auto-generated method stub return name; } } public static class Employee{ private Person person; private String city; public Employee(Person person, String city) { this.person = person; this.city = city; } public Employee(String name, String city) { this.person = new Person(name); this.city = city; }
public Person getPerson() { return person; }
public void setPerson(Person person) { this.person = person; }
public String getCity() { return city; }
public void setCity(String city) { this.city = city; }
@Override public String toString() { // TODO Auto-generated method stub return person.toString(); } } 在main方法中: List<Employee> employees=Arrays.asList(new Employee("小鐘","深圳"),new Employee("小紅", "深圳"),new Employee("小齊", "廣州")); //鍵為城市,list為員工列表 Map<String, List<Employee>> employeeMap= new HashMap<String,List<Employee>>(); //根據城市對員工進行分類 //傳統分類 for (Employee employee : employees) { String city=employee.getCity(); if(employeeMap.get(city)==null) { List<Employee> employeeList=new ArrayList<Employee>(); employeeList.add(new Employee(employee.getPerson().getName(), city)); employeeMap.put(city,employeeList); } else { List<Employee> employeeList=employeeMap.get(city); employeeList.add(employee); } } System.out.println(employeeMap); 輸出: {廣州=[小齊], 深圳=[小鐘, 小紅]} 可以看到,如果用傳統方法分類步驟繁瑣,寫程式碼還有思考一下怎麼寫 如果我們用groupingBy方法,那就變得直觀,而且簡單了 //使用groupingBy方法進行分類 Stream<Employee> stream=employees.stream(); employeeMap = stream.collect(Collectors.groupingBy(Employee::getCity)); 輸出: {廣州=[小齊], 深圳=[小鐘, 小紅]} 我們只需要短短一行程式碼,就把stream分好類了,並裝入了map中 另外,groupingBy方法和SQL中的group by很類似,不知道大家有沒有發現 就相當於 select city from XXX group by city
groupingBy的進一步使用: 利用groupingBy我們還可以進行更進一步的分類操作 在資料庫中,我們可以這樣來對統計分組中的元素 例如:select city,count(*) from XXX group by city 同樣我們用groupingBy也可以做到類似的效果 Map <String,Long> map=stream2.collect(Collectors.groupingBy(Employee::getCity,Collectors.counting())); System.out.println(map); 輸出: {廣州=1, 深圳=2}
這一種東西在SQL中叫做 聚合函式,在JAVA8中叫做“下游收集器”。 這些函式一般在groupingBy中使用 下面列舉一些常見的
建立Optional類:
- Optional.of(T value)
- Optional.ofNullable(T value)
- Optional.empty();
第一種方法接收一個物件,返回一個含義該物件的Optional物件,但他不接收null,否則會丟擲NullPointerException異常 第二種方法接收一個物件,也接收null,返回一個含義該物件的Optional物件,這個Optional物件可以是空的。 第三種方法就直接建立一個空的Optional
舉個栗子: public static void main(String[] args) {
可以看到,當使用第二種方法也就是ofNullable方法時,如果傳入的物件為空,就直接返回一個空的Optional物件,避免了空指標物件 而使用of方法時,傳入的物件為null時,則會丟擲 NullPointerException異常
實際上,我們通過ofNullable()方法的原始碼也可以發現,它被用來作為可能出現null值和可選值之間的橋樑。他在傳入的值不為空的時候 返回Option.of(obj),在傳入的值為空時則,返回Optional.empty();
ofNullable原始碼: public static <T> Optional<T> ofNullable(T value) { return value == null ? empty() : of(value);
}
現在我們已經會建立Optional物件了,那接下來就要看看他是如何使用的
使用Optional物件 我們已經知道Optional物件是一種更加安全的物件,因為他對空值進行了處理,那也就是說,他的使用方法 得像這樣:他會在值不存在的情況下產生一個“替代物”代替null,在值存在的情況下則使用該值 我們先看下第一種情況,在值不存在的時候怎麼辦: 當值不存在時: 1、給預設值 public class OptionalUse { public static void main(String[] args) { Optional<String> optional=Optional.ofNullable(null); String result=optional.orElse("empty String"); System.out.println(result); } } 輸出: empty String 可以看到,利用orElse()方法,我們為沒有Optional物件為空的情況指定了一個預設值,呼叫時若為空則返回指定的 預設值。 2、給處理方法得出預設值 public class OptionalUse { public static void main(String[] args) { Optional<String> optional=Optional.ofNullable(null); String result=optional.orElseGet(()->Locale.getDefault().getDisplayName()); System.out.println(result); } } 輸出: 中文 (中國) 同樣的,我們指定了一個方法為預設方法(上面那個方法的作用是返回本地語言和國家) 3、丟擲某個異常 public class OptionalUse { public static void main(String[] args) { Optional<String> optional=Optional.ofNullable(null); String result=optional.orElseThrow(RuntimeException::new); System.out.println(result); } } 輸出: Exception in thread "main" java.lang.RuntimeException at java.base/java.util.Optional.orElseThrow(Optional.java:385) at 建立流.OptionalUse.main(OptionalUse.java:9) 這個應該就沒什麼好解釋了的,預設指定為丟擲一個異常
當值存在時: 當值存在時,我們可以對值進行操作, 注意:這種操作是可能改變Optional本身包含的值的。 1、利用void ifPresent(Supplier <? extemds T> s) Supplier有點熟悉吧,他其實就是一個Lambda表示式,我們在建立流的generate()方法中有看到過。 public class OptionalUse { public static void main(String[] args) { Optional<String> optional=Optional.ofNullable("XiaoZhong"); String result=optional.orElseThrow(RuntimeException::new); optional.ifPresent(w->System.out.println(w.toUpperCase())); //這個get()是獲取Optional物件中的元素 System.out.println(optional.get()); } } 輸出: XIAOZHONG XiaoZhong
前面說到,這種操作是可能改變Optional本身包含的值的。 可以看到,在ifPresent()方法裡,我們對該值進行了大小寫轉換並作出了列印操作,然後再一次的在ifParesent()外面 驗證了一下Optional中的值是否被改變了。發現值並沒有被改變。 但你有可能會想,ifPresent()把引數傳遞給某個函式的時候是值傳遞,如果傳遞某個具體的物件呢(其實這個String已經是個物件了), 保險起見,我們再驗證一下。 public class OptionalUse { public static class Id { private static int count=0; private final int id=count++; public String name="Zhong"; public Id() { // TODO Auto-generated constructor stub } @Override public String toString() { // TODO Auto-generated method stub return "ID: "+ id +"\nNAME: " + name; }
public String getName() { return name; }
public void setName(String name) { this.name = name; } } public static void main(String[] args) { Optional<Id> optional=Optional.ofNullable(new Id()); //這個get()是獲取Optional物件中的元素 System.out.println(optional.get()); optional.ifPresent(w->w.setName("you name")); System.out.println(optional.get()); } } 輸出: ID: 0 NAME: Zhong ID: 0 NAME: you name
這裡簡單地寫了一個內部類,這個內部類用來記錄一個人ID和名字,名字預設是Zhong,我們想通過在ifPresent()中呼叫內部類的 set方法,來看是否發生了改變,結果顯而易見,的確發生了改變 其實我們在傳遞引數的時候,當傳入的基本資料型別時,是值傳遞,而傳入的是陣列,物件時則是引用傳遞,這一點同樣適用於在 ifPresent()中引數的傳遞
2、利用map()對值進行操作 先上程式碼 Optional<String> optional2=Optional.ofNullable(null); List<String> list=new ArrayList<String>(); optional2.map(list::add); System.out.println(list); optional2=Optional.of("Hello World"); optional2.map(list::add); System.out.println(list); 輸出: [] [Hello World]
map()對Optional中的值進行操作,這裡是把值加入到list中,list的add有兩種情況,當Optional為空時,則返回空的Optional,不為空則返回某個字串。 這裡的”::“操作符,是lambda表示式對方法的呼叫,叫做method reference。大家可以看看這兩個資料: 中文版: http://zh.lucida.me/blog/java-8-lambdas-insideout-language-features/ 英文版: http://www.techempower.com/blog/2013/03/26/everything-about-java-8/ 這裡有詳細地講述,JAVA8中Lambda表示式的用法。
3、利用flatMap()來構建Optional值的函式 假設你有一個可以產生Optional<T>的f方法,泛型T又有一個可以產生Optional<U>的方法g,你想通過f獲得U目標物件 很自然地會想到 這樣組合 s.f().g(),然而這樣無法工作,因為s.f()是Optional<T>型別的,而不是T型別的

可以使用Optional<U>=s.f().flatMap(T::g) 來獲得U,這和之前的stream.flatMap()很類似,也類似把一些巢狀給“拍扁”了,直接取用他們的值 再舉個例子:
private static Optional<Double> sum(Double a,Double b){ return Optional.of(a+b); } private static Optional<Double> squareRoot(Double x){ return x<0?Optional.empty():Optional.of(Math.sqrt(x)); } main方法中: //Optional<Double> result=sum(1.0,1.0).map(a->squareRoot(a)); 不行,編譯器會報錯,不能把Optional<Double>轉換為Double //flatMap示例 Optional<Double> result=sum(1.0,1.0).flatMap(a->squareRoot(a)); System.out.println(result.get()); 輸出: 1.4142135623730951 二、收集結果 1、forEach(),將函式應用於每個元素 例如:stream.forEach(System.out::print); 2、iterator(),用來訪問元素的迭代器 沒錯,JAVA8也有迭代器,使用方法和以前的一樣,就不寫例子了 3、toArray(),將流中的元素轉換為陣列物件 但是stream.toArray()返回的是Object[]型別的陣列,要得到正確型別的陣列,我們就得傳陣列構造器到引數中 例如:String[] result=stream.toArray(String[]::new); 4、轉換成Collection (1)轉換成List,利用stream.collect(Collectors.toList()) 例如List<String> result=stream.collect(Collectors.toList()) (2)轉換成set,利用stream.collect(Collectors.toSet()) 例如Set<String> result=stream.collect(Collectors.toSet()) (3)轉換成Map,這個要重點記下筆記 a、利用Collectors.toMap()方法 這一種是最簡單的,直接指定鍵和值就可以了 例如: 假設我們有個Stream<Employee>物件stream,Employee有name,city的例項變數,並且具有相對應的get和set方法 現在我們要生成一個Map,以city為鍵,name為值 Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName)); 這樣就行了,十分簡單 但是如果鍵衝突了怎麼辦,即一個鍵對應了多個元素,編譯器會丟擲IllegalStateException 我們要為toMap再新添一個引數,說明這種情況怎麼辦 例如: Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->existingValue)); (existingValue,newValue)->existingValue指出了這種情況怎麼辦,即以原先的元素為準,不新增新元素 或者你也可以選擇丟擲異常 Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->{throw new RuntimeException("SomethingWrong")})); 如果要得到TreeSet,那麼再加一個構造引數在收集器中就可以了 Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->{throw new RuntimeException("SomethingWrong")},TreeMap::new)); b、利用Collectors.groupingBy()分組獲得Map groupingBy的基本使用方法: goupingBy方法會產生一個對映表,它的每一個值都對應一個列表

顧名思義,它實際上起的作用就是根據某個關鍵字進行分類的作用 舉個栗子: 下面是用來記錄員工的類 public static class Person{ private String name; public Person(String name) { // TODO Auto-generated constructor stub this.name=name; }
public String getName() { return name; }
public void setName(String name) { this.name = name; } @Override public String toString() { // TODO Auto-generated method stub return name; } } public static class Employee{ private Person person; private String city; public Employee(Person person, String city) { this.person = person; this.city = city; } public Employee(String name, String city) { this.person = new Person(name); this.city = city; }
public Person getPerson() { return person; }
public void setPerson(Person person) { this.person = person; }
public String getCity() { return city; }
public void setCity(String city) { this.city = city; }
@Override public String toString() { // TODO Auto-generated method stub return person.toString(); } } 在main方法中: List<Employee> employees=Arrays.asList(new Employee("小鐘","深圳"),new Employee("小紅", "深圳"),new Employee("小齊", "廣州")); //鍵為城市,list為員工列表 Map<String, List<Employee>> employeeMap= new HashMap<String,List<Employee>>(); //根據城市對員工進行分類 //傳統分類 for (Employee employee : employees) { String city=employee.getCity(); if(employeeMap.get(city)==null) { List<Employee> employeeList=new ArrayList<Employee>(); employeeList.add(new Employee(employee.getPerson().getName(), city)); employeeMap.put(city,employeeList); } else { List<Employee> employeeList=employeeMap.get(city); employeeList.add(employee); } } System.out.println(employeeMap); 輸出: {廣州=[小齊], 深圳=[小鐘, 小紅]} 可以看到,如果用傳統方法分類步驟繁瑣,寫程式碼還有思考一下怎麼寫 如果我們用groupingBy方法,那就變得直觀,而且簡單了 //使用groupingBy方法進行分類 Stream<Employee> stream=employees.stream(); employeeMap = stream.collect(Collectors.groupingBy(Employee::getCity)); 輸出: {廣州=[小齊], 深圳=[小鐘, 小紅]} 我們只需要短短一行程式碼,就把stream分好類了,並裝入了map中 另外,groupingBy方法和SQL中的group by很類似,不知道大家有沒有發現 就相當於 select city from XXX group by city
groupingBy的進一步使用: 利用groupingBy我們還可以進行更進一步的分類操作 在資料庫中,我們可以這樣來對統計分組中的元素 例如:select city,count(*) from XXX group by city 同樣我們用groupingBy也可以做到類似的效果 Map <String,Long> map=stream2.collect(Collectors.groupingBy(Employee::getCity,Collectors.counting())); System.out.println(map); 輸出: {廣州=1, 深圳=2}
這一種東西在SQL中叫做 聚合函式,在JAVA8中叫做“下游收集器”。 這些函式一般在groupingBy中使用 下面列舉一些常見的
- counting 對組中的元素個數進行統計
- summingInt、summingLong、summingDouble,接收組中元素的一個函式(該函式返回值必須是對應型別),產生這些函式返回值的和
- maxBy,minBy會接收一個比較器,並比較器中相應的值,產生一個擁有最大值或最小值的Optional的物件(Optional用來包裝分組元素)
- mapping方法會產生將函式應用到下游結果上的收集器,並將函式值傳遞到另一個收集器
呼~今天總結寫了好多東西,感覺自己更深入的理解了一些,先到這裡,下次再來更新