
Python3實現機器學習經典演算法(四)C4.5決策樹
一、C4.5決策樹概述
C4.5決策樹是ID3決策樹的改進演算法,它解決了ID3決策樹無法處理連續型資料的問題以及ID3決策樹在使用資訊增益劃分資料集的時候傾向於選擇屬性分支更多的屬性的問題。它的大部分流程和ID3決策樹是相同的或者相似的,可以參考我的上一篇部落格:https://www.cnblogs.com/DawnSwallow/p/9452586.html
C4.5決策樹和ID3決策樹相同,也可以產生一個離線的“決策樹”,而且對於連續屬性組成的C4.5決策樹資料集,C4.5演算法可以避開“測試集中的取值不存在於訓練集”這種情況,所以不需要像ID3決策樹那樣,預先將測試集中不存在於訓練集中的屬性的取值,“手動地”加入到決策樹中的問題。但是對於同時有離散屬性和連續屬性的資料集,離散屬性部分仍舊是需要進行將存在於測試集,不存在於訓練集中的取值(注意,是取值不是向量!)給刪除或者加入到樹的構造過程中。
C4.5不是一個簡單的決策樹構造演算法,它是一組演算法,包括C4.5的構造和C4.5剪枝的問題,剪枝問題在ID3決策樹、C4.5決策樹和CART樹都實現完的時候再統一實現。
流行的C4.5決策樹構造演算法是沒有進行修正的過程的,這會導致一個很嚴重的問題:C4.5決策樹在構造樹的時候傾向於選擇連續屬性作為最佳分割屬性。所以C4.5需要一個修正的過程,在進行連續屬性的資訊增益率的計算的時候,要進行修正。
C4.5使用的是資訊增益率來劃分“最好的”屬性,這個“資訊增益率”和ID3決策樹使用的“資訊增益”有什麼區別呢?
資訊增益(Information Gain):對於某一種劃分的資訊增益可以表示為“期望資訊 - 該種劃分的夏農熵”。它的公式可以表示為:IG(T)=H(C)-H(C|T)。
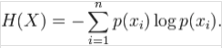
當我們把這條熵公式轉換為一個函式:calculateEntropy(dataSet,feature = NULL)的時候,上面這個計算過程可以變成以下的虛擬碼:

1 while dataSet != NULL:
2 feat = -1
3 for i in range(featureNum):
4 IG = calculateEntropy(dataSet) - calculateEntropy(dataSet,feature[i])
5 if IG > IGMAX:
6 IGMAX = IG
7 feat = feature[i]
8 #IGMAX此時儲存的即為最大的資訊增益,feat儲存的即為最大的資訊增益所對應的特徵
9 dataSet = dataSet - feature[i]#這裡不是減法,而是在資料集中去除該列
由上面的虛擬碼,也可以理解到“資訊增益最大的時候,熵減最多”。這裡的數學理解就是:資訊增益的公式可以看作A - B,其中B是改變的,A是一個常量,那麼B越小A - B的值就會越大,B越小則代表熵越小,當B達到最小的時候,A - B最大,此時熵最小,也即是熵減最多。
資訊增益率/資訊增益比(GainRatio):在選擇決策樹中某個結點上的分支屬性時,假設該結點上的資料集為DataSet,其中包含Feature個描述屬性,樣本總數為len(DataSet)或者DataSet.shape[0],設描述屬性feature(不同於Feature,Feature是屬性的個數,取值為DataSet.shape[1],feature是某一個具體的屬性)總共有M個不同的取值,則利用描述屬性feature可以將資料集DataSet劃分為M個子集,設這些子集為{DataSet1,DataSet2,…,DataSetN,…,DataSetM},並且這些子集中樣本在同一個子集中對應的feature屬性的取值應該是相同的(若feature屬性為離散屬性,則取值為某一個離散值,若為連續屬性,則取值為<=num,>num之一),用{len1,len2,…,lenN,…,lenM}表示每個對應的子集的樣本的數量,則用描述屬性feature來劃分給定的資料集DataSet所得到的資訊增益率/資訊增益比為:

Gain(feature)的演算法和上面ID3決策樹計算資訊增益的演算法是一樣的,事實上,求GainRatio的過程就是在上述的計算資訊增益的過程中加上一個對其“稀釋”的作用,使得取值多的feature不會佔據主導地位,由於在計算資訊增益的時候,是一個累加的公式,log(p)一定是一個負值,這樣就導致Gain(feature)會一直地往上增大,即使增大幅度很小,而除以劃分屬性的熵公式(如下)則可以儘量的把這種微小的累加所帶來的影響降到最低。
C4.5處理連續屬性的資料的過程:假設當前正在處理的屬性feature為一個連續型屬性,當前正在劃分的資料集的樣本數量為total,則:
①將該節點上的所有資料樣本按照連續型描述屬性的具體取值,由小到大進行排序,得到屬性值的取值序列{A1,A2,…,AN,…,Atotal};
②在獲得的取值序列{A1,A2,…,AN,…,Atotal}中生成total - 1個分割點,其中,第n(1<= n <= total - 1)個分割點的取值為(An + An+1 )/ 2,獲得的這個分割點,可以將資料集DataSet劃分為兩個子集,即描述屬性feature的取值在[ A1,(An + An+1 )/ 2 ],((An + An+1 )/ 2 ,Atotal]這兩個區間的資料樣本。
③從total - 1個分割點中選擇當前描述屬性feature的最佳分割點,這個分割點可以得到最大的資訊增益。(注意,資訊增益,而非資訊增益率,這是對C4.5的修正)
④計算當前描述屬性feature的資訊增益率,如果它的資訊增益率是所有的描述屬性中最大的,則選擇其作為當前結點的劃分描述屬性。
下面舉例說明C4.5演算法對於連續型描述屬性的處理方法:假設一個連續型屬性的取值序列為{32,25,46,56,60,52,42,36,23,51,38,43,41,65}。
①對連續序列進行升序排序,產生一個新的有序連續序列:{23,25,32,36,38,41,42,43,46,51,52,56,60,65};
②對新的有序連續序列產生分割點,共產生13個分割點:{24,23.5,34,37,39.5,41.5,42.5,44.5,48.5,51.5,54,58,62.5};
③選擇最佳分割點。對於第一個分割點,計算取值在[23,24]的數量和在(24,65]中的數量,然後計算其資訊增益IG1,而後對於第二個分割點,計算取值在[23,25]的數量和在(25,65]的數量,計算其資訊增益IG2,以此類推,最後選擇最大的資訊增益IGMAX,此時對應的分割點為最大分割點。
④選擇最大分割點後,對於這個分割點,計算資訊增益率GainRatio,則這個GainRatio則代表了這個描述屬性feature的GainRatio。
C4.5修正:C4.5的修正在上面的處理連續屬性的資料的過程③中體現了出來,它選擇的並不是能獲得最大的資訊增益率的分割點,而是選擇能獲得最大的資訊增益的分割點。這樣做的原因是,當我們選擇資訊增益率來作為C4.5的連續型屬性的資料集劃分的依據時,它會傾向於選擇連續型屬性來作為劃分的描述屬性具體演算法流程如下:
①將該節點上的所有資料樣本按照連續型描述屬性的具體取值,由小到大進行排序,得到屬性值的取值序列{A1,A2,…,AN,…,Atotal};
②在獲得的取值序列{A1,A2,…,AN,…,Atotal}中生成total - 1個分割點,其中,第n(1<= n <= total - 1)個分割點的取值為(An + An+1 )/ 2,獲得的這個分割點,可以將資料集DataSet劃分為兩個子集,即描述屬性feature的取值在[ A1,(An + An+1 )/ 2 ],((An + An+1 )/ 2 ,Atotal]這兩個區間的資料樣本,計算這個分割點的資訊增益。
③選擇資訊增益最大的分割點作為該描述屬性feature的最佳分割點。
④計算最佳分割點的資訊增益率作為當前的描述屬性的資訊增益率,對最佳分割點的資訊增益進行修正,減去log2(N-1)/|D|(N是連續特徵的取值個數,D是訓練資料數目)。
二、準備資料集
Python3實現機器學習經典演算法的資料集都採用了著名的機器學習倉庫UCI(http://archive.ics.uci.edu/ml/datasets.html),其中分類系列演算法採用的是Adult資料集(http://archive.ics.uci.edu/ml/datasets/Adult),測試資料所在網址:http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data,訓練資料所在網址:http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test。
Adult資料集通過收集14個特徵來判斷一個人的收入是否超過50K,14個特徵及其取值分別是:
age: continuous.
workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
fnlwgt: continuous.
education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
education-num: continuous.
marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse.
occupation: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces.
relationship: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried.
race: White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black.
sex: Female, Male.
capital-gain: continuous.
capital-loss: continuous.
hours-per-week: continuous.
native-country: United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands.
最終的分類標籤有兩個:>50K, <=50K.
下一步是分析資料:
1、資料預處理:C4.5演算法能處理連續屬性和連續屬性,所以這裡不需要資料預處理的過程,整個原生的資料集就是訓練集/測試集。
2、資料清洗:
資料中含有大量的不確定資料,這些資料在資料集中已經被轉換為‘?’,但是它仍舊是無法使用的,資料探勘對於這類資料進行資料清洗的要求規定,如果是可推算資料,應該推算後填入;或者應該通過資料處理填入一個平滑的值,然而這裡的資料大部分沒有相關性,所以無法推算出一個合理的平滑值;所以所有的‘?’資料都應該被剔除而不應該繼續使用。為此我們要用一段程式碼來進行資料的清洗:
1 def cleanOutData(dataSet):#資料清洗 2 for row in dataSet: 3 for column in row: 4 if column == '?' or column=='': 5 dataSet.remove(row
這段程式碼只是示例,它有它不能處理的資料集!比如上述這段程式碼是無法處理相鄰兩個向量都存在‘?’的情況的!修改思路有多種,一種是迴圈上述程式碼N次直到沒有'?'的情況,這種演算法簡單易實現,只是給上述程式碼加了一層迴圈,然而其複雜度為O(N*len(dataset));另外一種實現是每次找到存在'?'的列,回退迭代器一個距離,大致的虛擬碼為:
1 def cleanOutData(dataSet): 2 for i in range(len(dataSet)): 3 if dataSet[i].contain('?'): 4 dataSet.remove(dataSet[i]) ( dataSet.drop(i) ) 5 i-=1
上述程式碼的複雜度為O(n)非常快速,但是這種修改迭代器的方式會引起編譯器的報錯,對於這種報錯可以選擇修改編譯器使其忽略,但是不建議使用這種回退迭代器的寫法。
3、資料歸一化:
決策樹這樣的概念模型不需要進行資料歸一化,因為它關心的是向量的分佈情況和向量之間的條件概率而不是變數的值,進行資料歸一化更難以進行劃分資料集,因為Double型別的判等非常難做且不準確。
4、資料集讀入:
綜合上訴的預處理和資料清洗的過程,資料集讀入的過程為:
1 #讀取資料集 2 def createDateset(filename): 3 with open(filename, 'r')as csvfile: 4 dataset= [line.strip().split(', ') for line in csvfile.readlines()] #讀取檔案中的每一行 5 dataset=[[int(i) if i.isdigit() else i for i in row] for row in dataset] #對於每一行中的每一個元素,將行列式數字化並且去除空白保證匹配的正確完成 6 cleanoutdata(dataset) #清洗資料 7 del (dataset[-1]) #去除最後一行的空行 8 #precondition(dataset) #預處理資料 9 labels=['age','workclass','fnlwgt','education','education-num', 10 'marital-status','occupation', 11 'relationship','race','sex','capital-gain','capital-loss','hours-per-week', 12 'native-country'] 13 labelType = ['continuous', 'uncontinuous', 'continuous', 14 'uncontinuous', 15 'continuous', 'uncontinuous', 16 'uncontinuous', 'uncontinuous', 'uncontinuous', 17 'uncontinuous', 'continuous', 'continuous', 18 'continuous', 'uncontinuous'] 19 20 return dataset,labels,labelType 21 22 def cleanoutdata(dataset):#資料清洗 23 for row in dataset: 24 for column in row: 25 if column == '?' or column=='': 26 dataset.remove(row) 27 break
對比ID3的讀入過程,少了一個對於連續型屬性的清洗過程,增加了一個labelType的列表來表示當前的屬性是連續型屬性還是離散型屬性。
三、訓練演算法
訓練演算法既是構造C4.5決策樹的過程,構造結束的原則為:如果某個樹分支下的資料全部屬於同一型別,則已經正確的為該分支以下的所有資料劃分分類,無需進一步對資料集進行分割,如果資料集內的資料不屬於同一型別,則需要繼續劃分資料子集,該資料子集劃分後作為一個分支繼續進行當前的判斷。
用偽程式碼表示如下:
if 資料集中所有的向量屬於同一分類:
return 分類標籤
else:
if 屬性特徵已經使用完:
進行投票決策
return 票數最多的分類標籤
else:
尋找資訊增益率最大的資料集劃分方式(找到要分割的屬性特徵T)
根據屬性特徵T建立分支
if 屬性為連續型屬性:
讀入取值序列並升序排列
選擇資訊增益最大的分割點作為子樹的劃分依據
else:
for 屬性特徵T的每個取值
成為當前樹分支的子樹
劃分資料集(將T屬性特徵的列丟棄或遮蔽)
return 分支(新的資料集,遞迴)
根據上面的虛擬碼,可以得到下面一步一部的訓練演算法流程,其中很多的過程和在ID3決策樹中的過程是相似的甚至一模一樣的。
1、尋找資訊增益率最大的資料集劃分方式(找到要分割的屬性特徵T):
1 #計算夏農熵/期望資訊 2 def calculateEntropy(dataSet): 3 ClassifyCount = {}#分類標籤統計字典,用來統計每個分類標籤的概率 4 for vector in dataSet: 5 clasification = vector[-1] #獲取分類 6 if not clasification in ClassifyCount.keys():#如果分類暫時不在字典中,在字典中新增對應的值對 7 ClassifyCount[clasification] = 0 8 ClassifyCount[clasification] += 1 #計算出現次數 9 shannonEntropy=0.0 10 for key in ClassifyCount: 11 probability = float(ClassifyCount[key]) / len(dataSet) #計算概率 12 shannonEntropy -= probability * log(probability,2) #夏農熵的每一個子項都是負的 13 return shannonEntropy 14 15 #連續型屬性不需要將訓練集中有,測試集中沒有的值補全,離散性屬性需要 16 # def addFeatureValue(featureListOfValue,feature): 17 # feat = [[ 'Private', 'Self-emp-not-inc', 'Self-emp-inc', 18 # 'Federal-gov', 'Local-gov', 'State-gov', 'Without-pay', 'Never-worked'], 19 # [],[],[],[],[]] 20 # for featureValue in feat[feature]: #feat儲存的是所有屬性特徵的所有可能的取值,其結構為feat = [ [val1,val2,val3,…,valn], [], [], [], … ,[] ] 21 # featureListOfValue.append(featureValue) 22 23 #選擇最好的資料集劃分方式 24 def chooseBestSplitWay(dataSet,labelType): 25 isContinuous = -1 #判斷是否是連續值,是為1,不是為0 26 HC = calculateEntropy(dataSet)#計算整個資料集的夏農熵(期望資訊),即H(C),用來和每個feature的夏農熵進行比較 27 bestfeatureIndex = -1 #最好的劃分方式的索引值,因為0也是索引值,所以應該設定為負數 28 gainRatioMax=0.0 #資訊增益率=(期望資訊-熵)/分割獲得的資訊增益,即為GR = IG / split = ( HC - HTC )/ split , gainRatioMax為最好的資訊增益率,IG為各種劃分方式的資訊增益 29 30 continuousValue = -1 #設定如果是連續值的屬性返回的最好的劃分方式的最好分割點的值 31 for feature in range(len(dataSet[0]) -1 ): #計算feature的個數,由於dataset中是包含有類別的,所以要減去類別 32 featureListOfValue=[vector[feature] for vector in dataSet] #對於dataset中每一個feature,建立單獨的列表list儲存其取值,其中是不重複的 33 addFeatureValue(featureListOfValue,feature) #增加在訓練集中有,測試集中沒有的屬性特徵的取值 34 if labelType[feature] == 'uncontinuous': 35 unique=set(featureListOfValue) 36 HTC=0.0 #儲存HTC,即H(T|C) 37 split = 0.0 #儲存split(T) 38 for value in unique: 39 subDataSet = splitDataSet(dataSet,feature,value) #劃分資料集 40 probability = len(subDataSet) / float(len(dataSet)) #求得當前類別的概率 41 split -= probability * log(probability,2) #計算split(T) 42 HTC += probability * calculateEntropy(subDataSet) #計算當前類別的夏農熵,並和HTC想加,即H(T|C) = H(T1|C)+ H(T2|C) + … + H(TN|C) 43 IG=HC-HTC #計算對於該種劃分方式的資訊增益 44 if split == 0: 45 split = 1 46 gainRatio = float(IG)/float(split) #計算對於該種劃分方式的資訊增益率 47 if gainRatio > gainRatioMax : 48 isContinuous = 0 49 gainRatioMax = gainRatio 50 bestfeatureIndex = feature 51 else: #如果feature是連續型的 52 featureListOfValue = set(featureListOfValue) 53 sortedValue = sorted(featureListOfValue) 54 splitPoint = [] 55 for i in range(len(sortedValue)-1):#n個value,應該有n-1個分割點splitPoint 56 splitPoint.append((float(sortedValue[i])+float(sortedValue[i+1]))/2.0) 57 58 #C4.5修正,不再使用資訊增益率來選擇最佳分割點 59 # for i in range(len(splitPoint)): #對於n-1個分割點,計算每個分割點的資訊增益率,來選擇最佳分割點 60 # HTC = 0.0 61 # split = 0.0 62 # gainRatio = 0.0 63 # biggerDataSet,smallerDataSet = splitContinuousDataSet(dataSet,feature,splitPoint[i]) 64 # print(i) 65 # probabilityBig = len(biggerDataSet)/len(dataSet) 66 # probabilitySmall = len(smallerDataSet)/len(dataSet) 67 # HTC += probabilityBig * calculateEntropy(biggerDataSet) 68 # HTC += probabilityBig * calculateEntropy(smallerDataSet) 69 # if probabilityBig != 0: 70 # split -= probabilityBig * log(probabilityBig,2) 71 # if probabilitySmall != 0: 72 # split -= probabilitySmall *log(probabilitySmall,2) 73 # IG = HC - HTC 74 # if split == 0: 75 # split = 1; 76 # gainRatio = IG/split 77 # if gainRatio>gainRatioMax: 78 # isContinuous = 1 79 # gainRatioMax = gainRatio 80 # bestfeatureIndex = feature 81 # continuousValue = splitPoint[i] 82 IGMAX = 0.0 83 for i in range(len(splitPoint)): 84 HTC = 0.0 85 split = 0.0 86 87 biggerDataSet,smallerDataSet = splitContinuousDataSet(dataSet,feature,splitPoint[i]) 88 probabilityBig = len(biggerDataSet) / len(dataSet) 89 probabilitySmall = len(smallerDataSet) / len(dataSet) 90 HTC += probabilityBig * calculateEntropy(biggerDataSet) 91 HTC += probabilityBig * calculateEntropy(smallerDataSet) 92 if probabilityBig != 0: 93 split -= probabilityBig * log(probabilityBig, 2) 94 if probabilitySmall != 0: 95 split -= probabilitySmall * log(probabilitySmall, 2) 96 IG = HC - HTC 97 if IG>IGMAX: 98 IGMAX = IG 99 continuousValue = splitPoint[i] 100 N = len(splitPoint) 101 D = len(dataSet) 102 IG -= log(featureListOfValue - 1, 2) / abs(D) 103 GR = float(IG) / float(split) 104 if GR > gainRatioMax: 105 isContinuous = 1 106 gainRatioMax = GR 107 bestfeatureIndex = feature 108 109 return bestfeatureIndex,continuousValue,isContinuous
這裡需要解釋的地方有幾個:
1)資訊增益的計算:
經過前面對資訊增益的計算,來到這裡應該很容易能看得懂這段程式碼了。IG表示的是對於某一種劃分方式的資訊增益,由上面公式可知:IG = HC - HTC,HC和HTC的計算基於相同的函式calculateEntropy(),唯一不同的是,HC的計算相對簡單,因為它是針對整個資料集(子集)的;HTC的計算則相對複雜,由條件概率得知HTC可以這樣計算:

所以我們可以反覆呼叫calculateEntropy()函式,然後對於每一次計算結果進行累加,這就可以得到HTC。
2)addFeatureValue()函式
增加這一個函式的主要原因是:在測試集中可能出現訓練集中沒有的特徵的取值的情況,這在我所使用的adlut資料集中是存在的。慶幸的是,adult資料集官方給出了每種屬性特徵可能出現的所有的取值,這就創造瞭解決這個機會的條件。如上所示,在第二部分準備資料集中,每個屬性特徵的取值已經給出,那我們就可以在建立儲存某一屬性特徵的所有不重複取值的時候加上沒有存在的,但是可能出現在測試集中的取值。這就是addFeatureValue()的功用了。
3)chooseBestSplitWay()函式中的修正部分:
這是C4.5修正和不修正的區別之處,下面是不修正的程式碼:
1 else: #如果feature是連續型的 2 featureListOfValue = set(featureListOfValue) 3 sortedValue = sorted(featureListOfValue) 4 splitPoint = [] 5 for i in range(len(sortedValue)-1):#n個value,應該有n-1個分割點splitPoint 6 splitPoint.append((float(sortedValue[i])+float(sortedValue[i+1]))/2.0) 7 8 #C4.5修正,不再使用資訊增益率來選擇最佳分割點 9 for i in range(len(splitPoint)): #對於n-1個分割點,計算每個分割點的資訊增益率,來選擇最佳分割點 10 HTC = 0.0 11 split = 0.0 12 gainRatio = 0.0 13 biggerDataSet,smallerDataSet = splitContinuousDataSet(dataSet,feature,splitPoint[i]) 14 print(i) 15 probabilityBig = len(biggerDataSet)/len(dataSet) 16 probabilitySmall = len(smallerDataSet)/len(dataSet) 17 HTC += probabilityBig * calculateEntropy(biggerDataSet) 18 HTC += probabilityBig * calculateEntropy(smallerDataSet) 19 if probabilityBig != 0: 20 split -= probabilityBig * log(probabilityBig,2) 21 if probabilitySmall != 0: 22 split -= probabilitySmall *log(probabilitySmall,2) 23 IG = HC - HTC 24 if split == 0: 25 split = 1; 26 gainRatio = IG/split 27 if gainRatio>gainRatioMax: 28 isContinuous = 1 29 gainRatioMax = gainRatio 30 bestfeatureIndex = feature 31 continuousValue = splitPoint[i] 32 return bestfeatureIndex,continuousValue,isContinuous
這段程式碼本身是沒有錯誤的,它也能根據連續型屬性的非修正演算法來進行劃分,但是它的問題在於,它總是優先選擇連續型屬性來作為劃分描述屬性,如下所示:

這些屬性大多數都是連續型屬性,這就使得我們原本解決“ID3決策樹傾向於選擇取值多的屬性”轉變為“C4.5決策樹傾向於選擇連續型屬性”的問題。
所以根據上述的“修正”過程,得到下面的修正程式碼:
1 else: #如果feature是連續型的 2 featureListOfValue = set(featureListOfValue) 3 sortedValue = sorted(featureListOfValue) 4 splitPoint = [] 5 for i in range(len(sortedValue)-1):#n個value,應該有n-1個分割點splitPoint 6 splitPoint.append((float(sortedValue[i])+float(sortedValue[i+1]))/2.0) 7 8 #C4.5修正,不再使用資訊增益率來選擇最佳分割點 9 IGMAX = 0.0 10 for i in range(len(splitPoint)): 11 HTC = 0.0 12 split = 0.0 13 14 biggerDataSet,smallerDataSet = splitContinuousDataSet(dataSet,feature,splitPoint[i]) 15 probabilityBig = len(biggerDataSet) / len(dataSet) 16 probabilitySmall = len(smallerDataSet) / len(dataSet) 17 HTC += probabilityBig * calculateEntropy(biggerDataSet) 18 HTC += probabilityBig * calculateEntropy(smallerDataSet) 19 if probabilityBig != 0: 20 split -= probabilityBig * log(probabilityBig, 2) 21 if probabilitySmall != 0: 22 split -= probabilitySmall * log(probabilitySmall, 2) 23 IG = HC - HTC 24 if IG>IGMAX: 25 IGMAX = IG 26 continuousValue = splitPoint[i] 27 N = len(featureListOfValue) 28 D = len(dataSet) 29 IG -= log(N - 1, 2) / abs(D) 30 GR = float(IG) / float(split) 31 if GR > gainRatioMax: 32 isContinuous = 1 33 gainRatioMax = GR 34 bestfeatureIndex = feature 35 36 37 return bestfeatureIndex,continuousValue,isContinuous
這種演算法所執行的結果比較傾向於平均化:
由於 將連續性資料和離散型資料的處理方式統一的放在同一個chooseBestSplitWay中會導致這個函式非常的臃腫混亂,所以後面將它解析了,具體看完整程式碼。
4)在處理連續型屬性的時候,屬性取值序列進行了一次去重操作。
這個操作可以沒有,但是測試結果表示,進行一次去重操作反而可以提高程式的執行效率和正確率。
為什麼要進行這個去重操作?
考慮下面一種連續性屬性的取值序列:{A1,A2,…,An},其中An-m,An-m+1,…,An (0 <= m < n )是相等的,這種資料序列出現的概率非常大,比如age序列(已經升序):{1,2,3,4,…,80,80,80,80}
①如果按照上述的連續值處理的操作來做的話,那麼對於這個沒有去重的取值序列來說,將有多次取值為某一個數,那麼這多次取同一個數來進行資料集劃分的操作將是一模一樣的,加上C4.5本身就是一個低效的演算法,如果重複值非常多,會導致演算法更加的低效。
②另外一個情況就是,考慮它的分割點情況,在最後的{…,80,80,80,…,80}的序列中,顯然分割點為(80+80)/ 2 = 80,那麼在進行劃分資料集的時候,將會劃分為[min,80]以及(80,max]的情況,這樣又會遇到一個問題,即劃分的資料子集中,很有可能出現空集的情況。這樣就會導致我們計算出來的概率probability的取值為0,這樣又要對log(p)的計算進行0值的檢查。如果對資料集進行去重,本身是不會影響到資訊熵和最佳分割點的,因為在劃分資料集的時候,probability的計算是針對不去重列表的。而且對於去重後的分割點列表,對於每個取值,劃分資料集可以保證不會出現空值,這就極大程度地降低了程式的執行效率。
2、劃分資料集
其實在上一步就已經使用到了劃分資料集了,它沒有像我上面給到的流程那樣,在建立子樹後才劃分資料集,而是先進行劃分,然後再進行建立子樹,原因在於劃分資料集後計算資訊增益會變的更加通用,可以僅僅使用calculateEntropy()這個函式,而不需要在calculateEntropy()函式的前面增加一個劃分條件,所以我們應該將“劃分資料集”提前到“尋找最好的屬性特徵之後”立刻進行:
1 #劃分資料集 2 def splitDataSet(dataSet,featureIndex,value):#根據離散值劃分資料集,方法同ID3決策樹 3 newDataSet=[] 4 for vec in dataSet:#將選定的feature的列從資料集中去除 5 if vec[featureIndex] == value: 6 rest = vec[:featureIndex] 7 rest.extend(vec[featureIndex + 1:]) 8 newDataSet.append(rest) 9 return newDataSet 10 11 12 def splitContinuousDataSet(dataSet,feature,continuousValue):#根據連續值來劃分資料集 13