
Sklearn常用特徵提取和處理方法
1、將分類變數轉換為數值編號,才可以被處理
import pandas as pd import numpy as np from sklearn import preprocessing
用LabelEncoder對不同的犯罪型別編號 leCrime = preprocessing.LabelEncoder() crime = leCrime.fit_transform(train.Category)
2、將分類特徵因子化
為什麼要因子化: 對於型別因變數。如果僅僅採用數值編碼,那最大的問題就是在這種處理方式中,各種類別的特徵都被看成是有序的,這顯然是非常不符合實際場景的,所以因子化
方法有兩種:
1) pandas 的 get_dummies()方法 ,
days = pd.get_dummies(train.DayOfWeek) district = pd.get_dummies(train.PdDistrict) dummies_Cabin = pd.get_dummies(data_train[‘Cabin’], prefix= ‘Cabin’)
2) sklearn.preprocessing.OneHotEncoder方法
enc = OneHotEncoder() enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1],[1, 0, 2]]) print “enc.n_values_ is:”,enc.n_values_
print enc.transform([[0, 1, 1]]).toarray()
3)筆記
1、在實際建模前,所有的分類特徵,都需要進行因子化
2、pd.get_dummies()是 pandas庫提供的快捷方式,但不儲存轉換資訊。OneHotEncoder是比較完備的轉換器
3.不需要對特徵進行歸一化的情況
基於樹的方法不需要進行特徵的歸一化。例如隨機森林,bagging與boosting等方法。如果是基於引數的模型或者基於距離的模型,因為需要對引數或者距離進行計算,都需要進行歸一化。
4.PCA之前需要做標準化
collist=features.columns.tolist() scaler = preprocessing.StandardScaler() scaler.fit(features) features[collist]=scaler.transform(features)
new_PCA=PCA(n_components=60) new_PCA.fit(features) print(new_PCA.explained_variance_ratio_)
5、機器學習中的標準化/歸一化
資料的標準化(normalization)是將資料按比例縮放,使之落入一個小的特定區間。
標準化處理的好處:
1 加快梯度下降的求解速度,即提升模型的收斂速度
對於gradient descent演算法來說,learning rate的大小對其收斂速度至關重要。如果feature的scale不同,理論上不同的feature就需要設定不同的learning rate,但是gradient descent只有一個learning rate,這就導致不同feature的收斂效果不同,從而影響總體的收斂效果。所以在求解模型之前歸一化不同feature的scale,可以有效提高gradient descent的收斂速度。 因此在機器學習中使用梯度下降法求最優解時,歸一化也很有必要,否則模型很難收斂甚至有時不能收斂。
2 有可能提高模型的精度
一些分類器需要計算樣本之間的距離,如果一個特徵的值域範圍非常大,那麼距離計算就會主要取決於這個特徵,有時就會偏離實際情況。 如果feature的scale相差很大,則會出現scale越大的feature,對模型的影響越大。 也需要注意的是,各維分別做歸一化會丟失各維方差這一資訊,但各維之間的相關係數可以保留
標準化處理的常用方法:
1、線性標準化(歸一化)(min-max normalization)
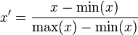
# 使用scikit-learn函式
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
feature_scaled = min_max_scaler.fit_transform(feature)
# 使用numpy自定義函式
def min_max_norm(x):
x = np.array(x)
x_norm = (x-np.min(x))/(np.max(x)-np.min(x))
return x_norm
標準差標準化(z-score standardization)
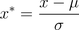
# 使用scikit-learn函式
from sklearn import preprocessing
standar_scaler = preprocessing.StandardScaler()
feature_scaled = standar_scaler.fit_transform(feature)
# 使用numpy自定義函式
def min_max_norm(x):
x = np.array(x)
x_norm = (x-np.mean(x))/np.std(x)
return x_norm
非線性歸一化
經常用在資料分化較大的場景,有些數值大,有些很小。通過一些數學函式,將原始值進行對映。該方法包括log、指數、反正切等。需要根據資料分佈的情況,決定非線性函式的曲線。
log函式:x = lg(x)/lg(max);反正切函式:x = atan(x)*2/pi
6.分類訓練集和測試集時,需要分層進行抽取
from sklearn.cross_validation import StratifiedShuffleSplit sss = StratifiedShuffleSplit(labels, train_size=0.5) for train_index, test_index in sss: features_train,features_test=features.iloc[train_index],features.iloc[test_index] labels_train,labels_test=labels[train_index],labels[test_index] features_test.index=range(len(features_test)) features_train.index=range(len(features_train)) labels_train.index=range(len(labels_train)) labels_test.index=range(len(labels_test)) features.index=range(len(features)) labels.index=range(len(labels))