
Navicat工具、pymysql模組、資料備份
一. IDE工具介紹(Navicat)
生產環境還是推薦使用mysql命令列,但為了方便我們測試,可以使用IDE工具,我們使用Navicat工具,這個工具本質上就是一個socket客戶端,視覺化的連線mysql服務端的一個工具,並且他是圖形介面版的。我們使用它和直接使用命令列的區別就類似linux和windows系統操作起來的一個區別。
navicat的使用見上一篇部落格
掌握: #1. 測試+連結資料庫 #2. 新建庫 #3. 新建表,新增欄位+型別+約束 #4. 設計表:外來鍵 #5. 新建查詢 #6. 備份庫/表 #注意: 批量加註釋:ctrl+?鍵 批量去註釋:ctrl+shift+?鍵
二. MySQL資料備份
分類:
#1. 物理備份: 直接複製資料庫檔案,適用於大型資料庫環境。但不能恢復到異構系統中如Windows。 #2. 邏輯備份: 備份的是建表、建庫、插入等操作所執行SQL語句,適用於中小型資料庫,效率相對較低。 #3. 匯出表: 將表匯入到文字檔案中。
一、使用mysqldump實現邏輯備份
#語法: # mysqldump -h 伺服器 -u使用者名稱 -p密碼 資料庫名 > 備份檔案.sql #示例: #單庫備份 mysqldump -uroot -p123 db1 > db1.sql mysqldump-uroot -p123 db1 table1 table2 > db1-table1-table2.sql #多庫備份 mysqldump -uroot -p123 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql #備份所有庫 mysqldump -uroot -p123 --all-databases > all.sql
二、恢復邏輯備份
#方法一: [[email protected] backup]# mysql -uroot -p123 < /backup/all.sql#方法二: mysql> use db1; mysql> SET SQL_LOG_BIN=0; mysql> source /root/db1.sql #注:如果備份/恢復單個庫時,可以修改sql檔案 DROP database if exists school; create database school; use school;
三、備份/恢復案例
#資料庫備份/恢復實驗一:資料庫損壞 備份: 1. # mysqldump -uroot -p123 --all-databases > /backup/`date +%F`_all.sql 2. # mysql -uroot -p123 -e 'flush logs' //截斷併產生新的binlog 3. 插入資料 //模擬伺服器正常執行 4. mysql> set sql_log_bin=0; //模擬伺服器損壞 mysql> drop database db; 恢復: 1. # mysqlbinlog 最後一個binlog > /backup/last_bin.log 2. mysql> set sql_log_bin=0; mysql> source /backup/2014-02-13_all.sql //恢復最近一次完全備份 mysql> source /backup/last_bin.log //恢復最後個binlog檔案 #資料庫備份/恢復實驗二:如果有誤刪除 備份: 1. mysqldump -uroot -p123 --all-databases > /backup/`date +%F`_all.sql 2. mysql -uroot -p123 -e 'flush logs' //截斷併產生新的binlog 3. 插入資料 //模擬伺服器正常執行 4. drop table db1.t1 //模擬誤刪除 5. 插入資料 //模擬伺服器正常執行 恢復: 1. # mysqlbinlog 最後一個binlog --stop-position=260 > /tmp/1.sql # mysqlbinlog 最後一個binlog --start-position=900 > /tmp/2.sql 2. mysql> set sql_log_bin=0; mysql> source /backup/2014-02-13_all.sql //恢復最近一次完全備份 mysql> source /tmp/1.log //恢復最後個binlog檔案 mysql> source /tmp/2.log //恢復最後個binlog檔案 注意事項: 1. 完全恢復到一個乾淨的環境(例如新的資料庫或刪除原有的資料庫) 2. 恢復期間所有SQL語句不應該記錄到binlog中
四、實現自動化備份
備份計劃: 1. 什麼時間 2:00 2. 對哪些資料庫備份 3. 備份檔案放的位置 備份指令碼: [[email protected]~]# vim /mysql_back.sql #!/bin/bash back_dir=/backup back_file=`date +%F`_all.sql user=root pass=123 if [ ! -d /backup ];then mkdir -p /backup fi # 備份並截斷日誌 mysqldump -u${user} -p${pass} --events --all-databases > ${back_dir}/${back_file} mysql -u${user} -p${pass} -e 'flush logs' # 只保留最近一週的備份 cd $back_dir find . -mtime +7 -exec rm -rf {} \; 手動測試: [[email protected] ~]# chmod a+x /mysql_back.sql [[email protected] ~]# chattr +i /mysql_back.sql [[email protected] ~]# /mysql_back.sql 配置cron: [[email protected] ~]# crontab -l * * * /mysql_back.sql
五、表的匯出和匯入
SELECT... INTO OUTFILE 匯出文字檔案 示例: mysql> SELECT * FROM school.student1 INTO OUTFILE 'student1.txt' FIELDS TERMINATED BY ',' //定義欄位分隔符 OPTIONALLY ENCLOSED BY '”' //定義字串使用什麼符號括起來 LINES TERMINATED BY '\n' ; //定義換行符 mysql 命令匯出文字檔案 示例: # mysql -u root -p123 -e 'select * from student1.school' > /tmp/student1.txt # mysql -u root -p123 --xml -e 'select * from student1.school' > /tmp/student1.xml # mysql -u root -p123 --html -e 'select * from student1.school' > /tmp/student1.html LOAD DATA INFILE 匯入文字檔案 mysql> DELETE FROM student1; mysql> LOAD DATA INFILE '/tmp/student1.txt' INTO TABLE school.student1 FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '”' LINES TERMINATED BY '\n';
#可能會報錯 mysql> select * from db1.emp into outfile 'C:\\db1.emp.txt' fields terminated by ',' lines terminated by '\r\n'; ERROR 1238 (HY000): Variable 'secure_file_priv' is a read only variable #資料庫最關鍵的是資料,一旦資料庫許可權洩露,那麼通過上述語句就可以輕鬆將資料匯出到檔案中然後下載拿走,因而mysql對此作了限制,只能將檔案匯出到指定目錄 在配置檔案中 [mysqld] secure_file_priv='C:\\' #只能將資料匯出到C:\\下 重啟mysql 重新執行上述語句
六、資料庫遷移
務必保證在相同版本之間遷移 # mysqldump -h 源IP -uroot -p123 --databases db1 | mysql -h 目標IP -uroot -p456
三. pymysql模組
我們要學的pymysql就是用來在python程式中如何操作mysql,它和mysql自帶的那個客戶端還有navicat是一樣的,本質上就是一個套接字客戶端,只不過這個套接字客戶端是在python程式中用的,既然是客戶端套接字,應該怎麼用,是不是要連線服務端,並且和服務端進行通訊啊,讓我們來學習一下pymysql這個模組
#安裝 pip3 install pymysql
一 連結、執行sql、關閉(遊標)
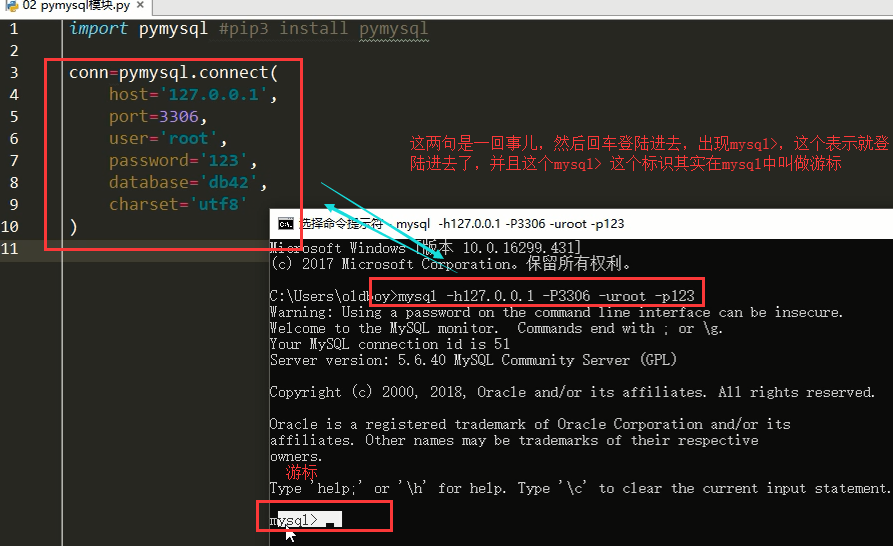
import pymysql user=input('使用者名稱: ').strip() pwd=input('密碼: ').strip() #連結,指定ip地址和埠,本機上測試時ip地址可以寫localhost或者自己的ip地址或者127.0.0.1,然後你操作資料庫的時候的使用者名稱,密碼,要指定你操作的是哪個資料庫,指定庫名,還要指定字符集。不然會出現亂碼 conn=pymysql.connect(host='localhost',port=3306,user='root',password='123',database='student',charset='utf8') #指定編碼為utf8的時候,注意沒有-,別寫utf-8,資料庫為 #得到conn這個連線物件 #遊標 cursor=conn.cursor() #這就想到於mysql自帶的那個客戶端的遊標mysql> 在這後面輸入指令,回車執行 #cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #獲取字典資料型別表示的結果:{'sid': 1, 'gender': '男', 'class_id': 1, 'sname': '理解'} {'欄位名':值} #然後給遊標輸入sql語句並執行sql語句execute sql='select * from userinfo where name="%s" and password="%s"' %(user,pwd) #注意%s需要加引號,執行這句sql的前提是醫藥有個userinfo表,裡面有name和password兩個欄位,還有一些資料,自己新增資料昂 print(sql) res=cursor.execute(sql) #執行sql語句,返回sql查詢成功的記錄數目,是個數字,是受sql語句影響到的記錄行數,其實除了受影響的記錄的條數之外,這些記錄的資料也都返回了給遊標,這個就相當於我們subprocess模組裡面的管道PIPE,乘放著返回的資料 #all_data=cursor.fetchall() #獲取返回的所有資料,注意凡是取資料,取過的資料就沒有了,結果都是元祖格式的 #many_data=cursor.fetchmany(3) #一下取出3條資料, #one_data=cursor.fetchone() #按照資料的順序,一次只拿一個數據,下次再去就從第二個取了,因為第一個被取出去了,取一次就沒有了,結果也都是元祖格式的 fetchone:(1, '男', 1, '理解') fetchone:(2, '女', 1, '鋼蛋') fetchall:((3, '男', 1, '張三'), (4, '男', 1, '張一')) #上面fetch的結果都是元祖格式的,沒法看出哪個資料是對應的哪個欄位,這樣是不是不太好看,想一想,我們可以通過python的哪一種資料型別,能把欄位和對應的資料表示出來最清晰,當然是字典{'欄位名':值} #我們可以再建立遊標的時候,在cursor裡面加上一個引數:cursor=conn.cursor(cursor=pymysql.cursors.DictCursor)獲取的結果就是字典格式的,fetchall或者fetchmany取出的結果是列表套字典的資料形式 上面我們說,我們的資料取一次是不是就沒有了啊,實際上不是的,這個取資料的操作就像讀取檔案內容一樣,每次read之後,游標就移動到了對應的位置,我們可以通過seek來移動游標 同樣,我們可以移動遊標的位置,繼續取我們前面的資料,通過cursor.scroll(數字,模式),第一個引數就是一個int型別的數字,表示往後移動的記錄條數,第二個引數為移動的模式,有兩個值:absolute:絕對移動,relative:相對移動 #絕對移動:它是相對於所有資料的起始位置開始往後面移動的 #相對移動:他是相對於遊標的當前位置開始往後移動的 #絕對移動的演示 #print(cursor.fetchall()) #cursor.scroll(3,'absolute') #從初始位置往後移動三條,那麼下次取出的資料為第四條資料 #print(cursor.fetchone()) #相對移動的演示 #print(cursor.fetchone()) #cursor.scroll(1,'relative') #通過上面取了一次資料,遊標的位置在第二條的開頭,我現在相對移動了1個記錄,那麼下次再取,取出的是第三條,我相對於上一條,往下移動了一條 #print(cursor.fetchone()) print(res) #一個數字 cursor.close() #關閉遊標 conn.close() #關閉連線 if res: print('登入成功') else: print('登入失敗')
二 execute()之sql注入
之前我們進行使用者名稱密碼認證是先將使用者名稱和密碼儲存到一個檔案中,然後通過讀檔案裡面的內容,來和客戶端傳送過來的使用者名稱密碼進行匹配,現在我們學了資料庫,我們可以將這些使用者資料儲存到資料庫中,然後通過資料庫裡面的資料來對客戶端進行使用者名稱和密碼的認證。
自行建立一個使用者資訊表userinfo,裡面包含兩個欄位,username和password,然後裡面寫兩條記錄
#我們來使用資料來進行一下使用者名稱和密碼的認證操作 import pymysql conn = pymysql.connect( host='127.0.0.1', port=3306, user='root', password='666', database='crm', charset='utf8' ) cursor = conn.cursor(pymysql.cursors.DictCursor) uname = input('請輸入使用者名稱:') pword = input('請輸入密碼:') sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword) res = cursor.execute(sql) #res我們說是得到的行數,如果這個行數不為零,說明使用者輸入的使用者名稱和密碼存在,如果為0說名存在,你想想對不 print(res) #如果輸入的使用者名稱和密碼錯誤,這個結果為0,如果正確,這個結果為1 if res: print('登陸成功') else: print('使用者名稱和密碼錯誤!') #通過上面的驗證方式,比我們使用檔案來儲存使用者名稱和密碼資訊的來進行驗證操作要方便很多。
但是我們來看下面的操作,如果將在輸入使用者名稱的地方輸入一個 chao'空格然後--空格然後加上任意的字串,就能夠登陸成功,也就是隻知道使用者名稱的情況下,他就能登陸成功的情況:
uname = input('請輸入使用者名稱:') pword = input('請輸入密碼:') sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword) print(sql) res = cursor.execute(sql) #res我們說是得到的行數,如果這個行數不為零,說明使用者輸入的使用者名稱和密碼存在,如果為0說名存在,你想想對不 print(res) #如果輸入的使用者名稱和密碼錯誤,這個結果為0,如果正確,這個結果為1 if res: print('登陸成功') else: print('使用者名稱和密碼錯誤!') #執行看結果:居然登陸成功 請輸入使用者名稱:chao' -- xxx 請輸入密碼: select * from userinfo where username='chao' -- xxx' and password=''; 登陸成功 我們來分析一下: 此時uname這個變數等於什麼,等於chao' -- xxx,然後我們來看我們的sql語句被這個字串替換之後是個什麼樣子: select * from userinfo where username='chao' -- xxx' and password=''; 其中chao後面的這個',在進行字串替換的時候,我們輸入的是chao',這個引號和前面的引號組成了一對,然後後面--在sql語句裡面是註釋的意思,也就是說--後面的sql語句被註釋掉了。也就是說,拿到的sql語句是select * from userinfo where username='chao';然後就去自己的資料庫裡面去執行了,發現能夠找到對應的記錄,因為有使用者名稱為chao的記錄,然後他就登陸成功了,但是其實他連密碼都不知道,只知道個使用者名稱。。。,他完美的跳過了你的認證環節。
然後我們再來看一個例子,直接連使用者名稱和密碼都不知道,但是依然能夠登陸成功的情況:
請輸入使用者名稱:xxx' or 1=1 -- xxxxxx 請輸入密碼: select * from userinfo where username='xxx' or 1=1 -- xxxxxx' and password=''; 登陸成功 我們只輸入了一個xxx' 加or 加 1=1 加 -- 加任意字串 看上面被執行的sql語句你就發現了,or 後面跟了一個永遠為真的條件,那麼即便是username對不上,但是or後面的條件是成立的,也能夠登陸成功。
上面兩個例子就是兩個sql注入的問題,看完上面這兩個例子,有沒有感覺後背發涼啊同志們,別急,我們來解決一下這個問題,怎麼解決呢?
有些網站直接在你輸入內容的時候,是不是就給你限定了,你不能輸入一些特殊的符號,因為有些特殊符號可以改變sql的執行邏輯,其實不光是--,還有一些其他的符號也能改變sql語句的執行邏輯,這個方案我們是在客戶端給使用者輸入的地方進行限制,但是別人可不可以模擬你的客戶端來發送請求,是可以的,他模擬一個客戶端,不按照你的客戶端的要求來,就發一些特殊字元,你的客戶端是限制不了的。所以單純的在客戶端進行這個特殊字元的過濾是不能解決根本問題的,那怎麼辦?我們服務端也需要進行驗證,可以通過正則來將客戶端傳送過來的內容進行特殊字元的匹配,如果有這些特殊字元,我們就讓它登陸失敗。
在服務端來解決sql注入的問題:不要自己來進行sql字串的拼接了,pymysql能幫我們拼接,他能夠防止sql注入,所以以後我們再寫sql語句的時候按下面的方式寫:
之前我們的sql語句是這樣寫的: sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword) 以後再寫的時候,sql語句裡面的%s左右的引號去掉,並且語句後面的%(uname,pword)這些內容也不要自己寫了,按照下面的方式寫 sql = "select * from userinfo where username=%s and password=%s;" 難道我們不傳值了嗎,不是的,我們通過下面的形式,在excute裡面寫引數: #cursor.execute(sql,[uname,pword]) ,其實它本質也是幫你進行了字串的替換,只不過它會將uname和pword裡面的特殊字元給過濾掉。 看下面的例子: uname = input('請輸入使用者名稱:') #輸入的內容是:chao' -- xxx或者xxx' or 1=1 -- xxxxx pword = input('請輸入密碼:') sql = "select * from userinfo where username=%s and password=%s;" print(sql) res = cursor.execute(sql,[uname,pword]) #res我們說是得到的行數,如果這個行數不為零,說明使用者輸入的使用者名稱和密碼存在,如果為0說名存在,你想想對不 print(res) #如果輸入的使用者名稱和密碼錯誤,這個結果為0,如果正確,這個結果為1 if res: print('登陸成功') else: print('使用者名稱和密碼錯誤!') #看結果: 請輸入使用者名稱:xxx' or 1=1 -- xxxxx 請輸入密碼: select * from userinfo where username=%s and password=%s; 使用者名稱和密碼錯誤!
通過pymysql提供的excute完美的解決了問題。
總結咱們剛才說的兩種sql注入的語句#1、sql注入之:使用者存在,繞過密碼 chao' -- 任意字元 #2、sql注入之:使用者不存在,繞過使用者與密碼 xxx' or 1=1 -- 任意字元
解決方法總結:
# 原來是我們對sql進行字串拼接 # sql="select * from userinfo where name='%s' and password='%s'" %(user,pwd) # print(sql) # res=cursor.execute(sql) #改寫為(execute幫我們做字串拼接,我們無需且一定不能再為%s加引號了) sql="select * from userinfo where name=%s and password=%s" #!!!注意%s需要去掉引號,因為pymysql會自動為我們加上 res=cursor.execute(sql,[user,pwd]) #pymysql模組自動幫我們解決sql注入的問題,只要我們按照pymysql的規矩來。
三 增、刪、改:conn.commit()
查操作在上面已經說完了,我們來看一下增刪改,也要注意,sql語句不要自己拼接,交給excute來拼接
import pymysql #連結 conn=pymysql.connect(host='localhost',port='3306',user='root',password='123',database='crm',charset='utf8') #遊標 cursor=conn.cursor() #執行sql語句 #part1 # sql='insert into userinfo(name,password) values("root","123456");' # res=cursor.execute(sql) #執行sql語句,返回sql影響成功的行數 # print(res) # print(cursor.lastrowid) #返回的是你插入的這條記錄是到了第幾條了 #part2 # sql='insert into userinfo(name,password) values(%s,%s);' # res=cursor.execute(sql,("root","123456")) #執行sql語句,返回sql影響成功的行數 # print(res) #還可以進行更改操作: #res=cursor.excute("update userinfo set username='taibaisb' where id=2") #print(res) #結果為1 #part3 sql='insert into userinfo(name,password) values(%s,%s);' res=cursor.executemany(sql,[("root","123456"),("lhf","12356"),("eee","156")]) #執行sql語句,返回sql影響成功的行數,一次插多條記錄 print(res) #上面的幾步,雖然都有返回結果,也就是那個受影響的函式res,但是你去資料庫裡面一看,並沒有儲存到資料庫裡面, conn.commit() #必須執行conn.commit,注意是conn,不是cursor,執行這句提交後才發現表中插入記錄成功,沒有這句,上面的這幾步操作其實都沒有成功儲存。 cursor.close() conn.close()
四 查:fetchone,fetchmany,fetchall
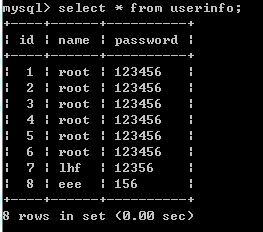
import pymysql #連結 conn=pymysql.connect(host='localhost',user='root',password='123',database='egon') #遊標 cursor=conn.cursor() #執行sql語句 sql='select * from userinfo;' rows=cursor.execute(sql) #執行sql語句,返回sql影響成功的行數rows,將結果放入一個集合,等待被查詢 # cursor.scroll(3,mode='absolute') # 相對絕對位置移動 # cursor.scroll(3,mode='relative') # 相對當前位置移動 res1=cursor.fetchone() res2=cursor.fetchone() res3=cursor.fetchone() res4=cursor.fetchmany(2) res5=cursor.fetchall() print(res1) print(res2) print(res3) print(res4) print(res5) print('%s rows in set (0.00 sec)' %rows) conn.commit() #提交後才發現表中插入記錄成功 cursor.close() conn.close() ''' (1, 'root', '123456') (2, 'root', '123456') (3, 'root', '123456') ((4, 'root', '123456'), (5, 'root', '123456')) ((6, 'root', '123456'), (7, 'lhf', '12356'), (8, 'eee', '156')) rows in set (0.00 sec) '''
五 獲取插入的最後一條資料的自增ID
import pymysql conn=pymysql.connect(host='localhost',user='root',password='123',database='egon') cursor=conn.cursor() sql='insert into userinfo(name,password) values("xxx","123");' rows=cursor.execute(sql) print(cursor.lastrowid) #在插入語句後檢視 conn.commit() cursor.close() conn.close()