Hbase讀寫流程和定址機制
阿新 • • 發佈:2018-12-10
寫操作流程
(1) Client通過Zookeeper的排程,向RegionServer發出寫資料請求,在Region中寫資料。
(2) 資料被寫入Region的MemStore,直到MemStore達到預設閾值。
(3) MemStore中的資料被Flush成一個StoreFile。
(4) 隨著StoreFile檔案的不斷增多,當其數量增長到一定閾值後,觸發Compact合併操作,將多個StoreFile合併成一個StoreFile,同時進行版本合併和資料刪除。
(5) StoreFiles通過不斷的Compact合併操作,逐步形成越來越大的StoreFile。
(6) 單個StoreFile
可以看出HBase只有增添資料,所有的更新和刪除操作都是在後續的Compact歷程中舉行的,使得使用者的寫操作只要進入記憶體就可以立刻返回,實現了HBase I/O的高機能。
讀操作流程
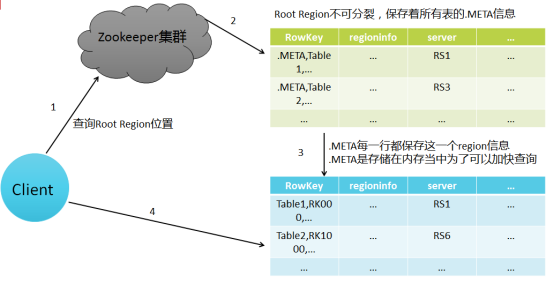
(1) Client訪問Zookeeper,查詢-ROOT-表,獲取.META.表資訊。
(2) 從.META.表查詢,獲取存放目標資料的
(3) 通過RegionServer獲取需要查詢的資料。
(4) Regionserver的記憶體分為MemStore和BlockCache兩部分,MemStore主要用於寫資料,BlockCache主要用於讀資料。讀請求先到MemStore中查資料,查不到就到BlockCache中查,再查不到就會到StoreFile上讀,並把讀的結果放入BlockCache。
定址過程:client-->Zookeeper-->-ROOT-表-->.META.表-->RegionServer-->Region-->client
Hbase定址機制