python資料探勘實戰筆記——文字分析(6):關鍵詞提取
阿新 • • 發佈:2018-12-11
緊接上篇的文件,這節學習關鍵字的提取,關鍵詞——keyword,是人們快速瞭解文件內容,把握主題的重要內容。
#匯入需要的模組 import os import codecs import pandas import jieba import jieba.analyse #搭建語料庫 for root, dirs, files in os.walk( r"C:\Users\www12\Desktop\data\2.6\SogouC.mini\\Sample\\" ): for name in files: filePath = root + '\\' + name; f = codecs.open(filePath, 'r', 'utf-8') content = f.read().strip() f.close()#讀取檔案內容 tags = jieba.analyse.extract_tags(content, topK=5)#獲取每篇文字詞頻在前五的關鍵詞 filePaths.append(filePath) contents.append(content)
關鍵字提取: tags = jieba.analyse.extract_tags(content, topK=n) 引數: content:文章內容 topK=n:n個關鍵詞
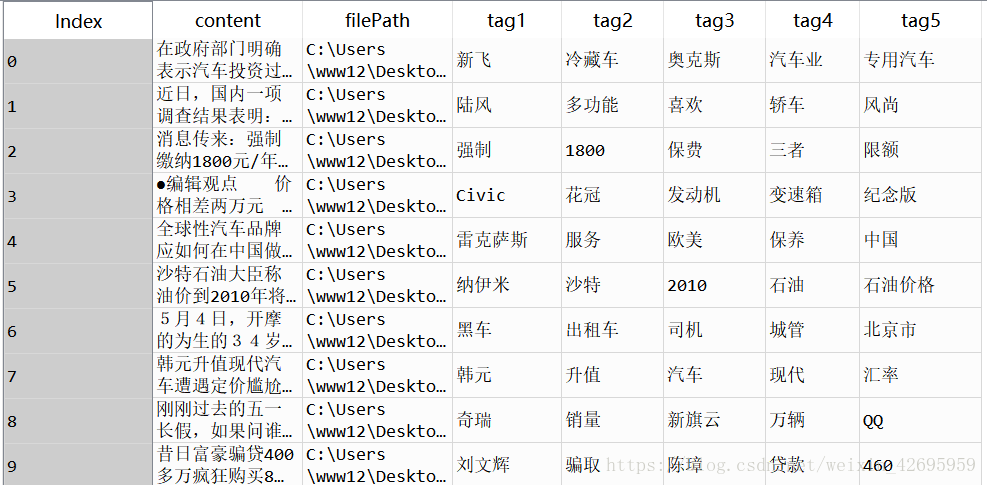
tag1s.append(tags[0])#陣列提取對應的關鍵詞 tag2s.append(tags[1]) tag3s.append(tags[2]) tag4s.append(tags[3]) tag5s.append(tags[4]) #關鍵詞陣列新增至資料框 tagDF = pandas.DataFrame({ 'filePath': filePaths, 'content': contents, 'tag1': tag1s, 'tag2': tag2s, 'tag3': tag3s, 'tag4': tag4s, 'tag5': tag5s })
提取完成,結果如圖: